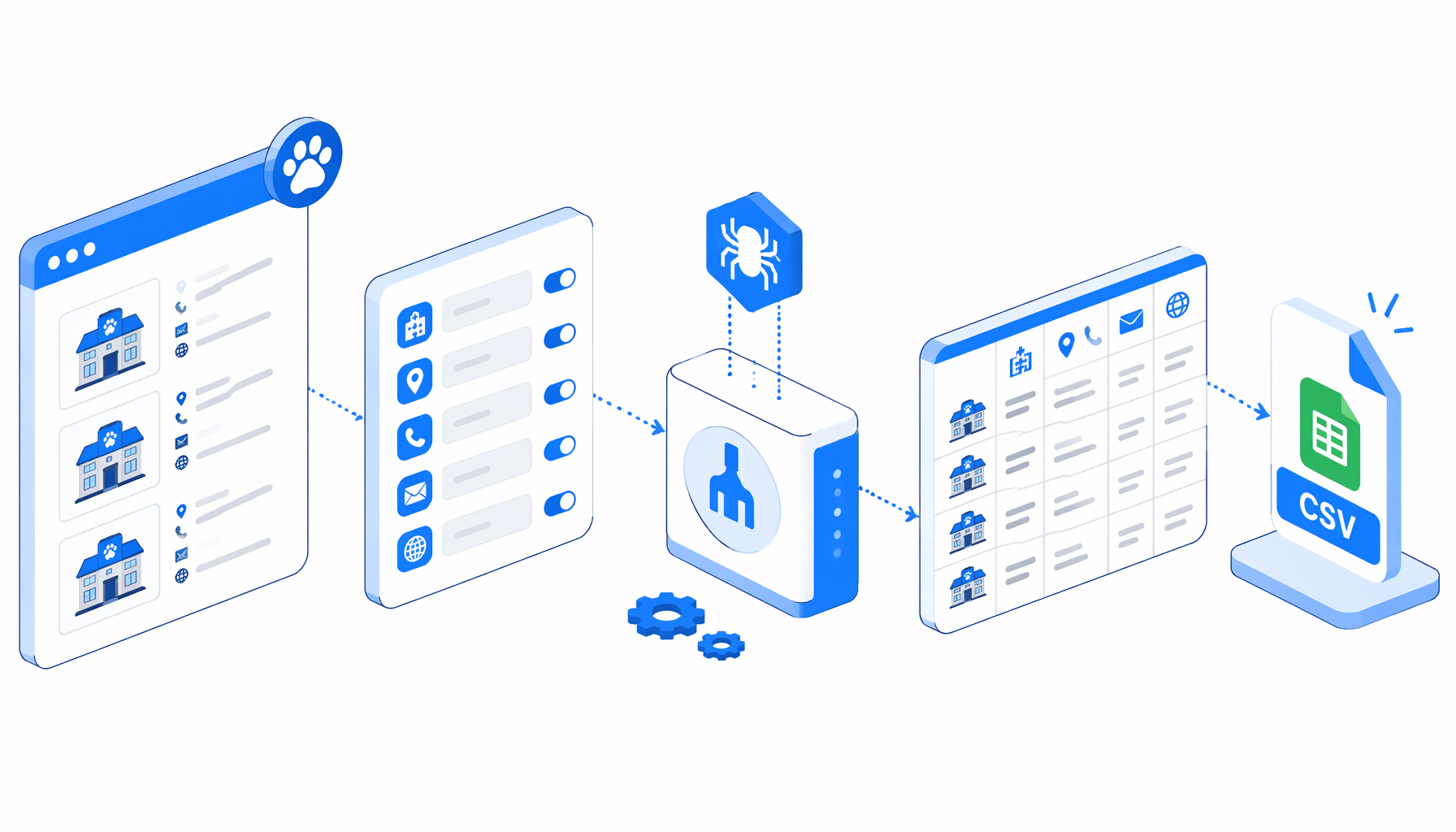
This tutorial shows how to scrape Peppy animal hospital details into CSV with the Peppy Animal Hospital Details Scraper for UScraper. You will import the workflow, review the URL list, set the export path, run a small validation batch, and check the hospital contact fields before scaling.
Before you start
Prerequisites, scope, and source checks
You need UScraper installed, the current JSON from the Peppy Animal Hospital Details Scraper template, a small set of PEPPY facility or clinic website URLs you are allowed to process, and a local folder for the CSV export. Start with the sample URLs from the template, then replace them with a reviewed list after the first run passes QA.
The PEPPY facility surface is a directory-style source for pet-related facilities, but this workflow does not crawl every listing page by itself. It is a by-URL veterinary clinic scraper: the Navigate block loops through hospital websites, not a search-results pagination sequence. That makes the workflow easier to audit because every row can be traced back to one input URL.
Technical access is not permission. Review PEPPY terms, each clinic website's terms, robots directives, privacy rules, database rights, and your outreach or resale policy before using the exported contact data.
Workflow anatomy
What the Peppy animal hospital scraper does
The JSON workflow is the source of truth. In plain language, the graph is:
Navigate -> Wait for Page Load -> Wait for Element
-> Inject JavaScript -> Sleep -> Structured Export -> Loop Continue
The Navigate block contains the hospital website URLs. UScraper opens one URL, waits for the page to load, confirms that the body is visible, then runs an enrichment script. That script looks for same-origin links whose labels suggest contact, access, clinic, about, company, guide, map, profile, or equivalent Japanese page names. It fetches a limited set of those support pages and adds their text to a hidden block so the export step has more context.
Structured Export then reads from the current page and enriched text. The template includes fallback logic for known sample URLs where public contact details are available but not exposed consistently in the live DOM.
| Workflow block | What to check | Why it matters |
|---|---|---|
| Navigate | The approved hospital website URLs you want to process | Controls exactly which clinics become CSV rows. |
| Wait for Element | The page body is visible before extraction | Prevents export before older or slower clinic pages finish loading. |
| Inject JavaScript | Same-origin contact and access pages are fetched when available | Improves contact coverage without leaving the clinic's own site. |
| Structured Export | Filename, save folder, headers, append mode, and five columns | Creates the spreadsheet you will validate and reuse. |
| Loop Continue | The workflow advances to the next input URL | Makes the template a repeatable URL-list scraper. |
Runbook
How to scrape Peppy animal hospital details to CSV
Import the template
Open Peppy Animal Hospital Details Scraper, download the JSON, and import it into UScraper.
Review the URL list
In Navigate, replace the sample hospital websites with the PEPPY facility or clinic URLs you are allowed to process. Keep the first batch short.
Confirm the export destination
In Structured Export, check peppy-animal-hospital-details-scraper.csv, headers, append mode, and the local save folder for this project.
Run a validation batch
Run three to five URLs, then pause. Compare hospital name, address, telephone number, email address, and website against the browser.
Clean and scale carefully
Remove failed rows, normalize phone and address formats, then add more URLs only after the first CSV matches the source pages.
Append mode is useful because every input URL writes to the same CSV, but it can also mix test rows with production rows. Use a dated filename or clear the test file before a larger veterinary clinic directory scraping run.
Output
What the CSV export includes
The Peppy animal hospital scraper exports one row per input website URL. The columns are intentionally narrow so the file is easy to review, dedupe, and hand off to a CRM or research spreadsheet.
| CSV column | What it captures | QA check |
|---|---|---|
hospital_name | Clinic or hospital name from metadata, title, headings, or known fallback rules | Compare Japanese names against the source page before translation. |
location | Address text matched from Japanese prefecture patterns and cleaned of nearby labels | Check postal codes, ward names, and line breaks manually on early rows. |
telephone_number | Telephone links or phone-like text on the page | Normalize hyphens and confirm country or area-code assumptions. |
email_address | Mailto links or email patterns from visible or enriched text | Expect blanks when clinics use forms or images instead of public email. |
website | The URL that produced the row | Use this as the audit key and dedupe field. |
Use UScraper when you want an inspectable no-code workflow, local CSV output, editable selectors, and a small-batch validation loop for animal hospital details.
Validation
Common issues and fixes
| Symptom | Likely cause | Fix |
|---|---|---|
| CSV is empty | The page did not load, the body wait failed, or the URL redirected unexpectedly | Open the URL in the browser, increase waits, and retry one row. |
| Hospital name is noisy | The site title contains marketing copy around the clinic name | Clean the column downstream or tighten the title fallback rule. |
| Email is blank | The clinic uses a form, image, or separate contact page | Treat email as optional and review the website manually when needed. |
| Address includes phone or hours text | Address and operating-hours labels were rendered on the same line | Clean the row and update the extraction pattern if it repeats. |
| Duplicate rows appear | The same clinic URL was included twice or the CSV was appended across tests | Dedupe by website and clear the test file before production runs. |
FAQ
Peppy animal hospital scraper FAQ
Public visibility is not the same as permission. Review PEPPY terms, each hospital site's terms, robots directives, privacy rules, database rights, and your intended use before scraping or reusing clinic data. Keep runs modest, avoid bypassing access controls, and get legal review for outreach, resale, or regulated workflows.
Next step
Download the Peppy animal hospital scraper template
Download the JSON from Peppy Animal Hospital Details Scraper, import it into UScraper, and run a short validation batch before adding a larger clinic list. For adjacent workflows, browse the UScraper template library or read more UScraper scraping tutorials.