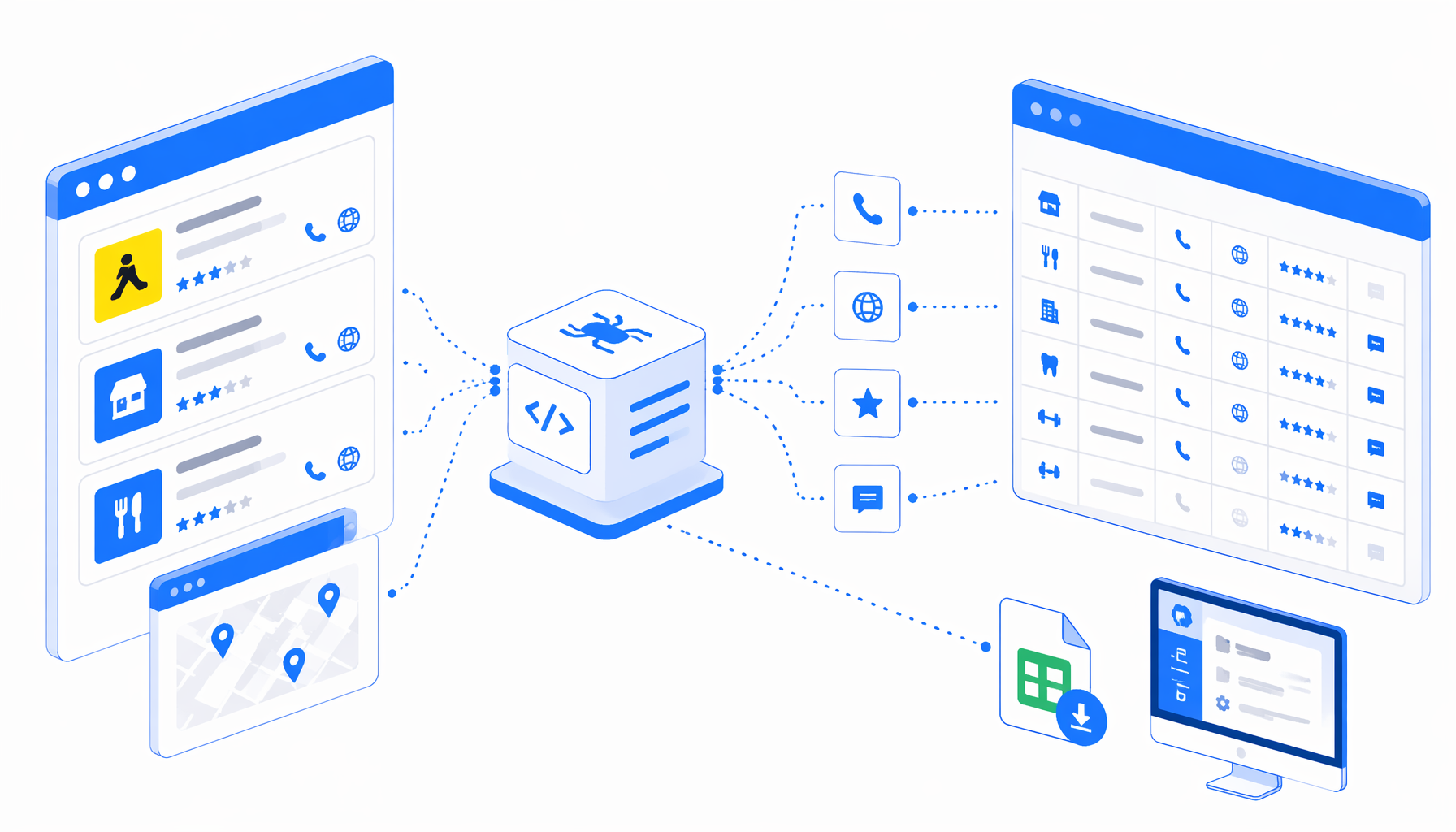
A PagesJaunes.ca business details scraper is most useful when the job is not "collect everything." The practical jobs are narrower: audit Canadian business citations, build a reviewed source list, monitor visible review rows, qualify a local market, or compare directory data against an internal CRM. This guide maps those workflows to the PagesJaunes.ca Business Details Scraper template for UScraper.
Problem
Why teams scrape PagesJaunes.ca business details
Canadian directory research often starts as manual browser work. A local SEO analyst searches the live PagesJaunes.ca directory or YellowPages.ca directory, opens several business profiles, copies phones and websites into a spreadsheet, then repeats the same routine for another category or city. A newsroom researcher does the same thing while building a source list. A market analyst does it while checking how many competitors publish websites, ratings, specialties, or French-language service details.
Manual collection also breaks context. A phone number gets separated from the business page, a review comment lands without the date, and a website field loses its source.
The useful artifact is not a giant raw scrape. It is a CSV that preserves enough evidence for a human to verify the row later.
Before any automation, review the Yellow Pages Canada terms, current robots files for PagesJaunes.ca and YellowPages.ca, and general robots.txt guidance from Google Search Central. Treat policy review as part of the workflow, especially if rows will feed outreach, resale, enrichment, or public reporting.
Personas
Use cases for a YellowPages Canada scraper
| Persona | Pain | CSV outcome |
|---|---|---|
| Local SEO teams | Client NAP data, website links, categories, and review signals differ across citation sources. | Compare nom_du_magasin, location, téléphone, site_web, rating, and comments against the client record. |
| Newsrooms and researchers | Source lists need contact context, geography, language, and visible public-review clues. | Build a reviewed lead sheet from selected business profiles before interviews or fact-checking. |
| Agencies and consultants | Category audits are hard to repeat across cities or verticals. | Export restaurant type, specialty, language, website, and rating fields into a consistent spreadsheet. |
| Operations teams | CRM records decay, especially phones, websites, branch locations, and service details. | Use the CSV as a verification queue before updating internal systems. |
| Monitoring teams | Manual review checks miss changes in visible sentiment, dates, or helpful counts. | Export visible review rows on a schedule you control, then diff small batches over time. |
Workflow
How the template turns page URLs into structured export
The PagesJaunes.ca Business Details Scraper workflow is intentionally narrow. It opens each supplied business profile URL, waits for the page, clears common consent overlays, clicks visible phone reveal controls where possible, normalizes business and review text, and writes one or more rows to pagesjaunes-ca-detail-scraper.csv.
Analyst workflow
- 1
Import
Download the JSON from the template page and import it into the UScraper local desktop app.
- 2
Configure
Replace the sample URL with approved PagesJaunes.ca or YellowPages.ca business detail URLs.
- 3
Run
Keep the wait, consent cleanup, phone reveal, and normalization blocks in place for the first batch.
- 4
Review
Open the CSV, spot-check several rows against live pages, and only then expand the URL list.
Export fields that matter in real workflows
pagesjaunes-ca-detail-scraper.csvColumn
nom_du_magasin
Business name from the detail page.
Column
location
Visible address or location text.
Column
téléphone
Phone number after visible reveal controls are clicked where possible.
Column
site_web
Website link exposed on the profile.
Column
type_de_restaurant
Restaurant type or category-like detail when present.
Column
spécialité
Specialty, service, or cuisine detail.
Column
Language
Languages listed on the profile.
Column
star_rating
Review-level rating or business rating fallback.
Column
nom_du_client
Reviewer name from visible review rows.
Column
date
Visible review date.
Column
commentaires
Cleaned review comment text.
Column
utile
Helpful count when displayed.
These fields are useful because they combine identity, contact, category, and review evidence in one row. For example, a local SEO team can filter profiles with missing websites, a newsroom can segment sources by city and language, and an operations team can mark review rows that need manual follow-up.
Fit
When UScraper is the right PagesJaunes.ca data extractor
Use UScraper when the work is supervised, the URL list is reviewed, and the deliverable is a spreadsheet. The local desktop app model is practical for research packs, client audits, and one-off monitoring where the analyst wants to see the workflow blocks and keep the export path under control.
Use a hosted alternative when the requirements change. Octoparse PagesJaunes.ca templates can fit hosted no-code tasks. Apify YellowPages Canada actors can fit API-driven cloud pipelines. Open-source scripts, such as a YellowPages.ca Python scraper, can fit engineering-owned systems where tests, queues, and custom retry logic are part of the project.
| Requirement | Better fit |
|---|---|
| Small batch, reviewed detail URLs, local CSV | UScraper template |
| Recurring cloud schedule and API dataset | Hosted actor or SaaS scraper |
| Custom parser with tests and internal integrations | Engineering-owned script |
| Citation audit or source-list spreadsheet | UScraper template plus manual QA |
For implementation steps, use the companion how-to guide. For tool selection, compare the PagesJaunes.ca scraper alternatives or browse the full UScraper template library.
FAQ
Frequently asked questions
The best fit is a team with a reviewed list of Canadian business detail URLs and a specific research workflow: citation audits, newsroom source lists, local market mapping, review monitoring, or CRM qualification. It is less suited to unsupervised bulk collection.