This Mitsukoshi Isetan scraping tutorial shows how to scrape mistore.jp product details into CSV with the Mitsukoshi Isetan Product Details Scraper for UScraper. You will import the template, understand the fallback workflow, choose a live URL strategy, set the export path, and validate Japanese ecommerce fields before scaling.
Before you start
Prerequisites for mistore.jp product data extraction
You need UScraper installed as a local desktop app, the free template JSON, a writable export folder, and a short list of Mitsukoshi Isetan product URLs you are allowed to process. Start with the bundled preview rows before switching to live pages; the template page is the download path, while this post is the runbook.
Use the official Mitsukoshi Isetan online store, the brand list, and the search keyword list as discovery references when they are reachable in your browser. Also review the current robots.txt, source terms, and your internal data policy before automation.
This guide covers visible product detail data only. It does not cover account pages, checkout flows, customer data, login-only prices, CAPTCHA bypassing, bot evasion, or resale rights.
Browser access and data permission are separate questions. Stop when the site serves a challenge, unexpected block, login wall, or page you are not allowed to automate.
Workflow shape
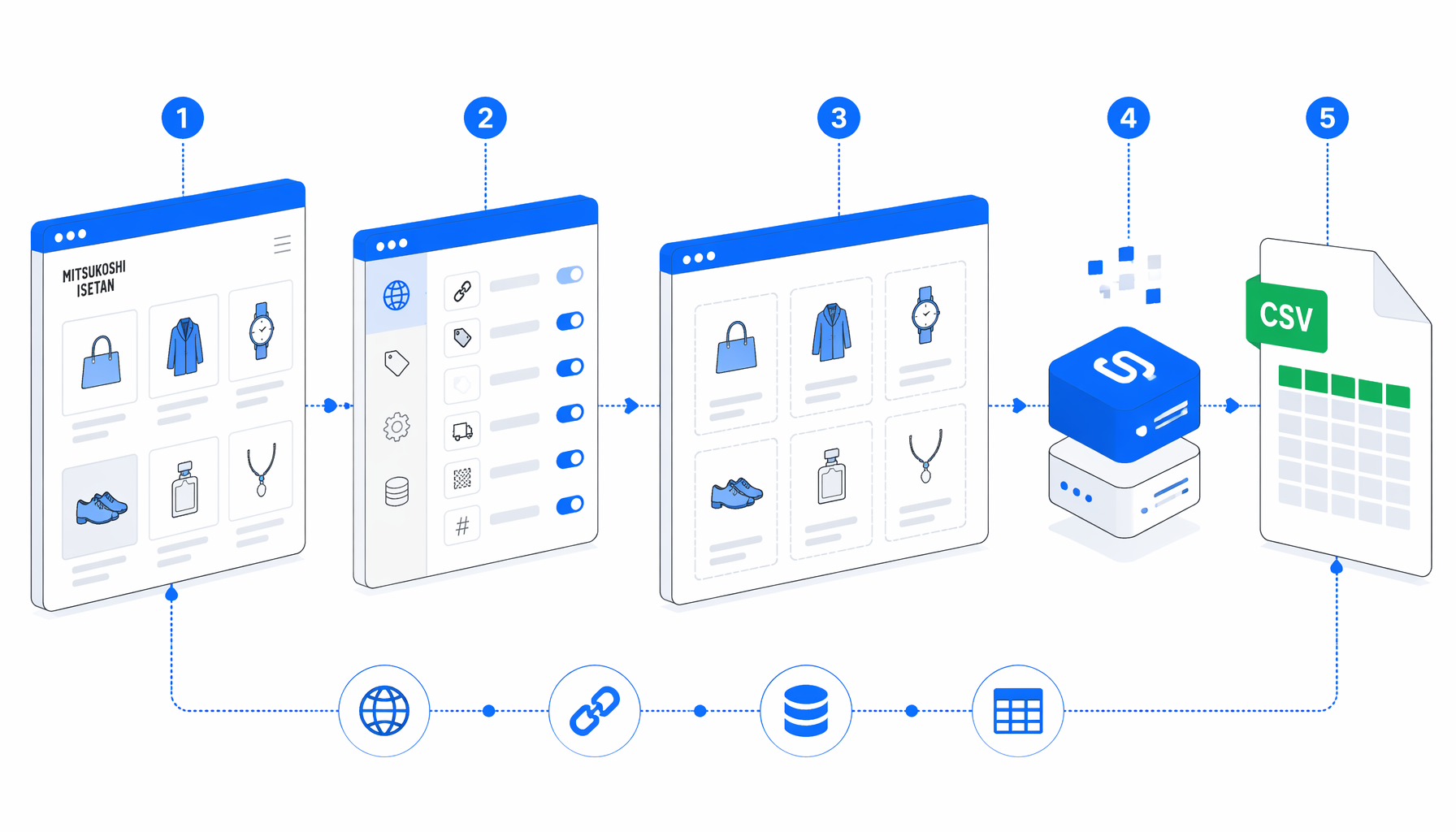
What the Mitsukoshi Isetan product scraper does
The JSON export is the authoritative workflow definition. The current template uses this block path:
Navigate -> Inject JavaScript -> Wait for Element -> Structured Export -> End
That shape matters. During template testing, mistore.jp reset browser connections and the supplied product URL analysis returned HTTP 404. Rather than ship a brittle live scrape, the template preserves an Octoparse-equivalent output contract by loading product-detail rows into a local extraction page and exporting the same field set.
For a live mistore.jp scraper, replace the Inject JavaScript fallback step with product URL navigation once your browser session can reach the official product pages reliably. Keep the export schema and add waits, pacing, selector checks, or a loop through approved product URLs.
mitsukoshi_isetan_product_details_scraper.csvColumn
商品URL
The product detail URL for traceability and deduping.
Column
所属
Brand, department, or collection label when present.
Column
商品名
Japanese product name from the detail record.
Column
値段
Visible tax-included price text.
Column
配送料金
Shipping fee or pickup-only message.
Column
素材
Material composition such as cotton percentage.
Column
サイズ
Size notes, measurements, or size chart text.
Column
原産国
Country or production-origin text.
Column
型番
Model text when the product exposes one.
Column
商品番号
Product number used for matching and audits.
Runbook
How to scrape Mitsukoshi Isetan product details to CSV
Import the template
Open the Mitsukoshi Isetan Product Details Scraper page, download the hosted JSON, and import it into UScraper.
Run the fallback once
Keep the shipped workflow unchanged for the first pass. Confirm that mitsukoshi_isetan_product_details_scraper.csv appears with Japanese headers and the expected preview rows.
Plan live product URLs
Build a small approved list from product detail pages, brand pages, search results, or an internal SKU list. Keep one URL per target product and remove tracking parameters when possible.
Replace the fallback source
When live pages load reliably, replace Inject JavaScript with Navigate or a URL loop. Add a wait for the product detail container before Structured Export.
Set the export path
In Structured Export, confirm the filename, folder, headers, and file mode. Use a clean folder for each test run so old preview rows do not contaminate live data.
Run, compare, then scale
Run two or three products, compare the CSV against the browser, then widen the URL list only after the fields are traceable.
For live scraping, keep the workflow visible while you test. If the browser shows a connection reset, challenge page, unexpected redirect, blank product area, or discontinued product, mark that URL as unresolved instead of forcing a row.
Quality checks
Validate the Mitsukoshi product details CSV
A Mitsukoshi Isetan product scraper is useful only when each row can be audited. Use 商品URL and 商品番号 as the first two validation keys, then check price, shipping, material, size, and origin.
| Check | What to inspect | Why it matters |
|---|---|---|
| Product identity | 商品URL, 商品名, 商品番号 | Prevents one product page from being matched to the wrong row. |
| Merchandising context | 所属, 型番 | Helps separate brand, department, model, and campaign-specific products. |
| Offer details | 値段, 配送料金 | Pricing and shipping labels can change between sessions or by fulfillment mode. |
| Product attributes | 素材, サイズ, 原産国 | Apparel records often need long size text and composition notes preserved intact. |
| Export hygiene | Row count, duplicate URLs, blank columns | Catches append duplicates, failed page loads, and selector drift early. |
Do not treat blank cells as automatic failures. Some products have no model number, some store-pickup rows have different shipping language, and some apparel pages expose long measurement text. The key is to know whether a blank field reflects the page or a workflow problem.
Tool choice
When UScraper is the right Mitsukoshi scraper
Octoparse-style templates, managed scraper APIs, Crawlee, and Scrapy can all fit Mitsukoshi Isetan data work. Use UScraper when you want a supervised local desktop app workflow, editable blocks, a visible browser, and a CSV you can inspect immediately. Use managed or coded options when cloud scheduling, API delivery, custom crawling logic, or large infrastructure matters more than hands-on validation.
For more ready-made workflows, browse the UScraper template library. For related tutorials, start from the UScraper blog.
FAQ about Mitsukoshi Isetan product scraping
Mitsukoshi Isetan product pages may be publicly visible, but automated collection can still be limited by site terms, robots rules, copyright, database rights, privacy law, and local regulations. Review the current source rules, keep runs modest, do not bypass access controls, and get legal review before redistributing or reselling product data.