This tutorial shows how to scrape MercadoLibre product details into CSV with the MercadoLibre Product Details Scraper for UScraper. You will prepare product or item API URLs, import the workflow, confirm the export path, run a small validation batch, and handle common MercadoLibre access issues before scaling.
Scope
Prerequisites for scraping MercadoLibre product data
You need UScraper installed as a local desktop app, a reviewed list of MercadoLibre product or item API URLs, and a folder where the CSV can be written. Start with three to five products. A small run is enough to confirm access, row shape, field coverage, and export behavior before you add a larger product set.
This guide is for product-detail research, not login automation, checkout flows, account pages, CAPTCHA bypassing, or scraping private seller data. MercadoLibre also has official developer resources for items and searches, API basics, and item descriptions. If your use case needs an approved integration, quotas, seller account data, or governed API access, review those docs before building a scraping workflow.
Treat access and permission as separate questions. If a browser can load a page, that still does not automatically mean your team can automate, store, redistribute, or resell the data.
Review the current MercadoLibre terms, API rules, and robots.txt before running automation. Keep request volume modest, do not bypass verification, and document the source URLs you used.
Workflow
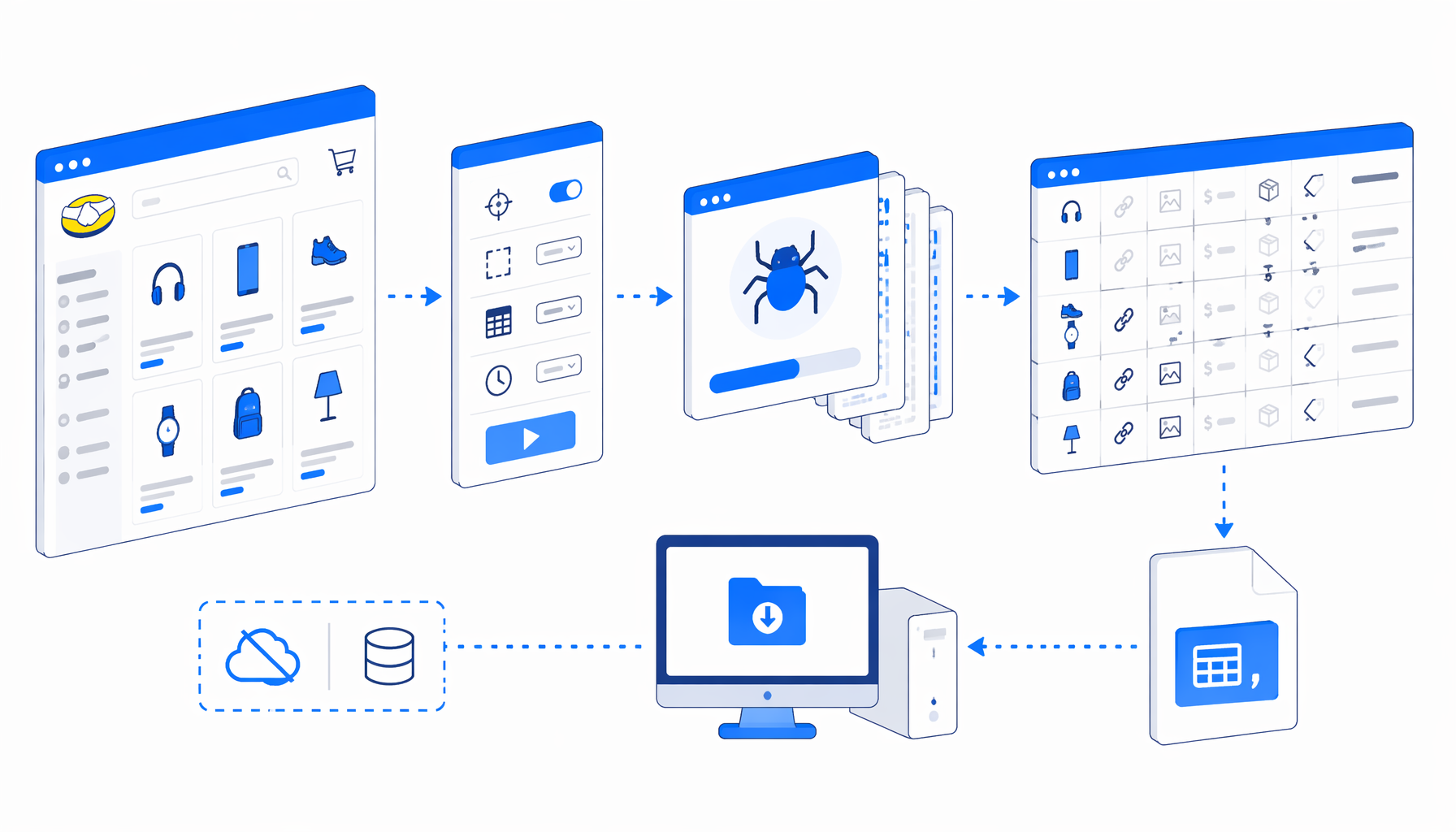
How the MercadoLibre product scraper works
The JSON export is the operational source of truth. Its block sequence is compact:
Set Window Size -> Navigate -> Wait for Page Load
-> Inject JavaScript -> Wait for Element
-> Structured Export -> Loop Continue
Navigate contains the URL list. In the bundled workflow, the sample inputs are MercadoLibre Mexico item API URLs such as https://api.mercadolibre.com/items/MLM1952878400. Wait for Page Load gives each response time to finish. Inject JavaScript reads JSON from the response body when possible, extracts common item fields, checks attributes for brand, creates a normalized #uscraper-product-row, and falls back to bundled sample metadata only when live access fails for the preview products.
Structured Export then reads that normalized row and writes the final CSV columns. Loop Continue advances to the next URL.
mercadolibre_detalles_scraper_fallback.csvColumn
producto
Product title from the item response or validated fallback data.
Column
producto_url
MercadoLibre product URL or reconstructed item permalink.
Column
imagen_url
Primary picture URL, secure thumbnail, or preview image URL.
Column
precio
Current item price when available in the response.
Column
estrellas
Rating placeholder; tune this if your source exposes rating data.
Column
estado
Availability signal such as Stock disponible or Sin stock.
Column
marca
Brand attribute from the item data when present.
Column
descripcion
Product description text from an approved source or fallback row.
Runbook
Scrape MercadoLibre product details to CSV
Import the workflow
Open the related template page, download the hosted JSON, and import it into UScraper.
Replace the sample URLs
In Navigate, paste the MercadoLibre product or item API URLs your team has reviewed. Keep one product per input URL and test with a short list first.
Review the JavaScript block
Confirm the normalizer still maps item JSON into #uscraper-product-row. If you add fallback rows, only use data you are allowed to store.
Confirm the export path
In Structured Export, check the filename, save folder, headers, and append mode. Use a clean file when you want a fresh validation run.
Run, inspect, then scale
Run a few products, open the CSV, compare rows against the source, and expand only after product URLs, prices, brands, and descriptions look correct.
Append mode is useful for ongoing product research, but it can also create duplicate rows during testing. Before reruns, either clear the file or deduplicate by producto_url. Keep the input URL list beside the output file so every row can be traced back to the run that produced it.
Validation
Validate MercadoLibre prices, brands, and descriptions
A MercadoLibre product scraper is only useful if the CSV is auditable. Open the export beside the source URLs and check rows from the beginning, middle, and end of the run.
| Check | What to compare | Why it matters |
|---|---|---|
| Product identity | producto and producto_url | Confirms the row belongs to the intended item. |
| Commercial fields | precio and estado | Flags unavailable items, changed prices, or blocked responses. |
| Catalog fields | marca and descripcion | Shows whether the item data exposes useful enrichment fields. |
| Media | imagen_url | Lets catalog teams verify the product image can be inspected or downloaded separately. |
| Empty cells | Any blank or fallback-only row | Signals access variation, missing attributes, or a source-specific mapping gap. |
If many rows are blank, do not immediately add more URLs. Check whether MercadoLibre returned a verification page, an error object, a different item response, or a category with fewer attributes. Fix the access path or mapper first, then rerun a small batch.
Alternatives
MercadoLibre scraper API, Python, Octoparse, or UScraper?
Python tutorials with requests, BeautifulSoup, Scrapy, or Selenium are useful when your team wants full control over HTTP sessions, parsing, retries, and code review. A MercadoLibre scraper API or hosted actor can be better when you need cloud scheduling, JSON endpoints, proxy management, and higher automation throughput. Octoparse-style visual templates are convenient when the team already runs that platform.
UScraper fits a different workflow: supervised no-code execution, editable blocks, visible validation, and local CSV output. It is a practical Octoparse MercadoLibre alternative when you want the export to stay in a desktop workflow and you do not need a hosted scraping pipeline.
| Option | Good fit | Trade-off |
|---|---|---|
| UScraper template | Local CSV exports, small approved batches, editable no-code workflow | Best for supervised runs and validation, not unattended high-volume crawling. |
| Python scraper | Custom parsing, tests, integrations, version control | Requires engineering time and ongoing selector or API maintenance. |
| Scraper API or hosted actor | Scheduling, managed infrastructure, JSON delivery | Usage billing and third-party processing are part of the workflow. |
| Official MercadoLibre API | Approved integrations and governed platform access | Requires following API requirements, credentials, quotas, and endpoint rules. |
Browse more ecommerce workflows in the UScraper template library, or return to the UScraper blog for scraping tutorials and comparisons.
Frequently asked questions
MercadoLibre product pages and item API responses may be public, but collection can still be limited by MercadoLibre terms, robots directives, API rules, intellectual property rights, privacy law, and local marketplace regulations. Use modest volume, do not bypass verification or access controls, and get legal review before using exported product data commercially.