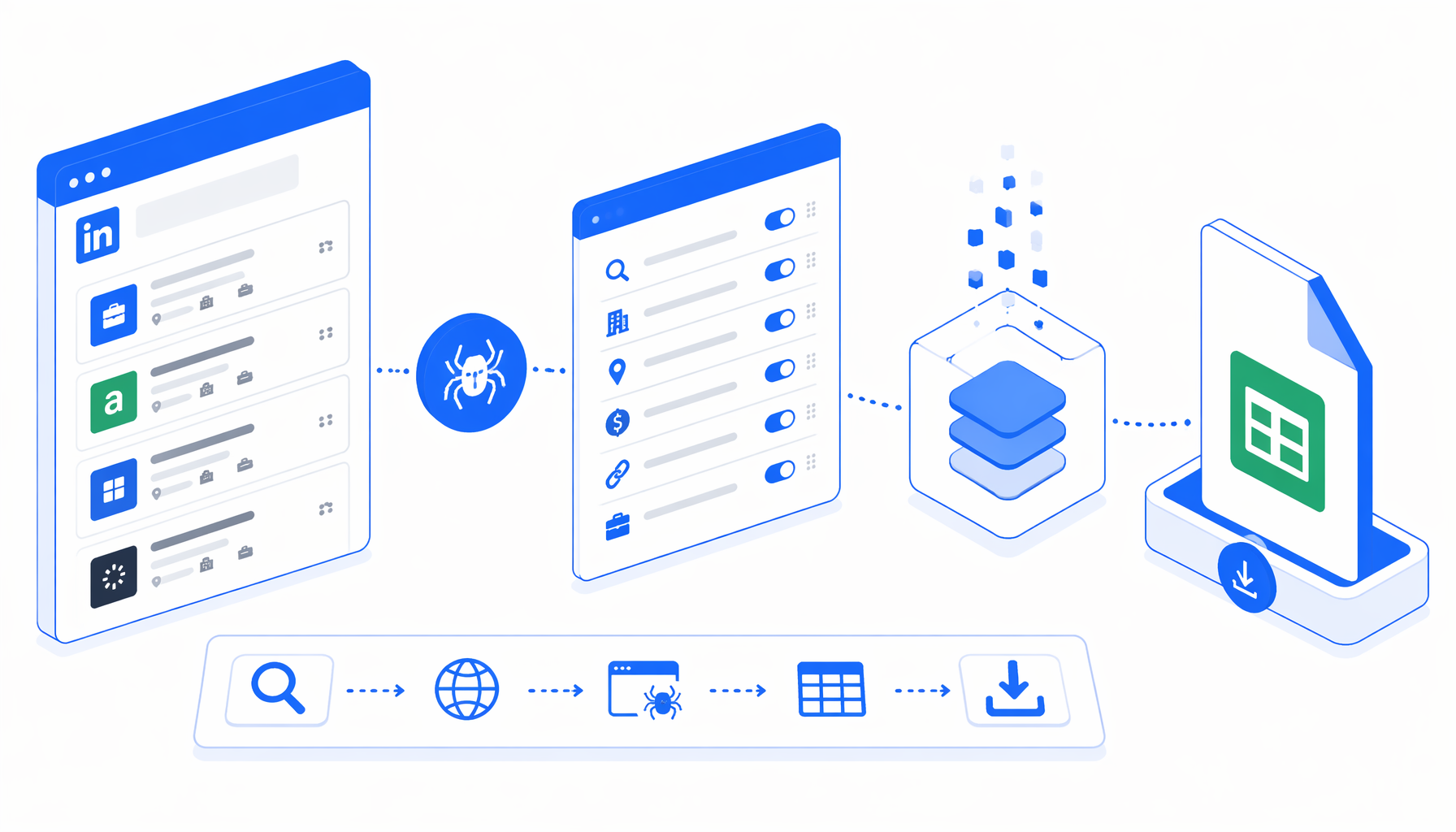
This LinkedIn scraping tutorial shows how to scrape LinkedIn jobs into CSV without writing Python code. You will import the LinkedIn Jobs Scraper for CSV Export template, edit the keyword and location URLs, set the export path, run a small validation batch, and review the output before scaling.
Before you start
Prerequisites for scraping LinkedIn jobs
You need the UScraper local desktop app, the LinkedIn Jobs Scraper template, and one approved job search to test. Keep the first run narrow: one role, one location, and a few pagination offsets.
The template is built for LinkedIn Jobs listing cards. It is not a LinkedIn profile scraper, people search scraper, messaging tool, or workaround for private pages. Full job descriptions usually require visiting detail URLs separately, so this workflow focuses on search-result data that can be reviewed in a spreadsheet.
Technical access is not permission. Review LinkedIn's User Agreement, Professional Community Policies, robots directives, privacy rules, contracts, and local regulations before collecting or reusing job data.
Workflow
How the LinkedIn jobs scraper works
The JSON export is the authoritative workflow definition. The template uses LinkedIn's public jobs-guest listing endpoint instead of the normal Jobs UI, which may redirect to an authentication wall. UScraper opens each configured URL, waits for the response, checks whether job cards exist, exports visible rows, and advances to the next offset.
Navigate URLs -> Wait for Page Load -> Element Exists
-> Structured Export -> Loop Continue
| Workflow block | Purpose | What to check |
|---|---|---|
| Navigate | Loops through the configured keywords, location, and start URLs | Replace the sample query with your approved search. |
| Wait for Page Load | Allows each listing response to finish loading | Keep the default 30 second timeout unless pages are consistently slow. |
| Element Exists | Checks for li:has(a[href*="/jobs/view/"]) | Empty pages, authwalls, or markup changes should stop the run. |
| Structured Export | Writes one row per visible job card | Confirm linkedin-scraper.csv, headers, append mode, and save folder. |
| Loop Continue | Moves to the next configured offset | Keep it at the end of the successful export path. |
Runbook
How to scrape LinkedIn jobs to CSV
Import the template
Open the LinkedIn Jobs Scraper template, download the JSON, and import it into UScraper.
Choose a narrow search
Pick one role and one location. Avoid mixing markets, seniority levels, and remote filters until the first export is validated.
Edit the Navigate URLs
Replace keywords=software%20engineer and location=United%20States in every URL. Keep the start offsets predictable.
Set the export path
In Structured Export, confirm linkedin-scraper.csv, headers, append mode, and the local folder where the CSV should be saved.
Run a watched batch
Process a few offsets while watching for empty responses, redirects, login prompts, or repeated rows. Stop if the page state changes.
Validate before scaling
Compare several rows against the visible cards, dedupe by job_url or job_id, then expand the offset list gradually.
Output
LinkedIn jobs to CSV: export fields
There is no bundled CSV sample for this workflow. Use the JSON export shape as the source of truth, then treat your first short run as the real sample. Salary, work type, and experience level can be blank when LinkedIn does not expose them in the listing response.
linkedin-scraper.csvColumn
job_title
Visible title from the LinkedIn job card.
Column
company
Employer name shown in the card subtitle.
Column
location
Location text from the listing card.
Column
posted_date
Relative posting date when visible.
Column
salary
Salary text when LinkedIn exposes it.
Column
job_url
LinkedIn job detail URL.
Column
company_url
Company page URL when exposed.
Column
job_id
Best-effort ID parsed from the job URL.
Column
work_type
Remote, Hybrid, On-site, or Onsite signal inferred from card text.
Column
raw_card_text
Normalized card text for audits and selector troubleshooting.
Sample rows
1 of many
| job_title | company | location | posted_date | salary | job_url | company_url | job_id | work_type | raw_card_text |
|---|---|---|---|---|---|---|---|---|---|
| Senior Software Engineer | ExampleCloud | United States Remote | 2 days ago | $145,000 - $190,000 | 1234567890 | Remote | Senior Software Engineer ExampleCloud United States Remote... |
| Field group | Columns included |
|---|---|
| Listing basics | job_title, company, location, posted_date, posted_datetime, salary |
| Links and IDs | job_url, company_url, company_logo_url, job_id, source_page_url |
| Inferred fields | work_type, experience_level_hint |
| Audit field | raw_card_text |
Validation
Common LinkedIn scraping issues and fixes
Run the first export with the browser and CSV open side by side. Check the first row, last row, one job with salary text, and one blank optional field.
| Symptom | Likely cause | Fix |
|---|---|---|
| CSV has headers but no rows | The current response had no matching job cards | Open the URL manually and reduce to one offset. |
| The run stops early | LinkedIn returned no cards, a redirect, or a changed page shape | Pause, inspect the page state, and avoid increasing volume. |
| Many rows repeat | The same offsets were rerun in append mode | Dedupe by job_url or job_id, then clear the CSV before retesting. |
| Salary or work type is blank | The field was not visible in that card | Leave it blank unless the value is clearly present. |
| Job IDs are missing | The URL pattern changed or the card link was absent | Keep raw_card_text for audit and update selectors if needed. |
Alternatives
LinkedIn scraper alternatives: desktop app, Python, or hosted API
The best LinkedIn scraping tool depends on who owns the workflow. UScraper is strongest when the goal is a reviewable local CSV. Python, Playwright, Selenium, or Scrapy are better when engineers need versioned code, tests, queues, and storage. Hosted scraper APIs can help with managed infrastructure and structured JSON, but they add vendor billing and data-handling review.
| Option | Best fit | Trade-off |
|---|---|---|
| UScraper template | Analyst-led LinkedIn jobs to CSV exports | You supervise pacing, validation, and policy review. |
| Python scraper | Engineering-owned scraping pipelines | More control, more maintenance. |
| Hosted scraper API | Managed scheduling or structured JSON delivery | Vendor infrastructure, usage costs, and data handling review. |
| Official LinkedIn routes | Approved partner or platform integrations | Not a general public search export path. |
If you searched for "scrape LinkedIn with Python" but only need a spreadsheet, start with the UScraper template library. If you need profile enrichment, messaging, or a production job search API, do a separate technical and policy review.
FAQ
Frequently asked questions
Yes, the UScraper LinkedIn Jobs Scraper template is a no-code workflow for supervised exports from public LinkedIn job listing responses. It does not automate account login or bypass access controls.
Next step
Download the LinkedIn Jobs Scraper template
Use this tutorial as the operating runbook and the LinkedIn Jobs Scraper for CSV Export page as the download path. Import the JSON, test two or three offsets, inspect linkedin-scraper.csv, then widen the query only after the output is consistent.
For adjacent workflows, browse all UScraper templates, read more tutorials in the UScraper blog, or use a job detail scraper when your approved workflow starts from a known list of job URLs instead of a search result page.