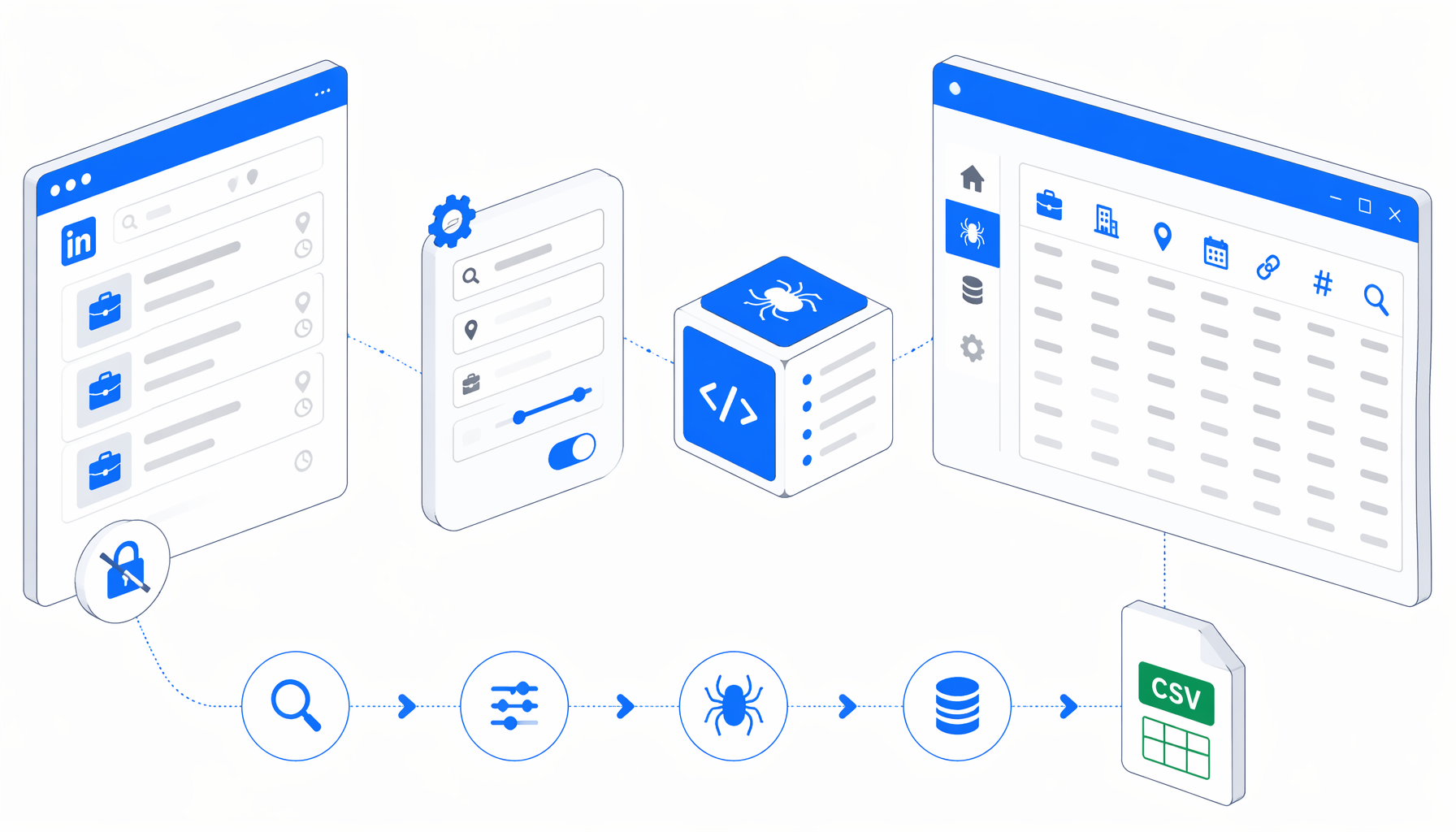
This tutorial shows how to scrape LinkedIn jobs without login into a reviewable CSV. Use the LinkedIn Job Scraper No Login Required template to edit public search URLs, set the export path, validate rows, and handle empty batches or blank optional fields.
Before you start
Prerequisites for a LinkedIn job scraper no login workflow
You need UScraper as a local desktop app, the LinkedIn Job Scraper No Login Required template, and one narrow job search to test. Use the public LinkedIn Jobs search page to choose keyword, location, date posted, workplace type, and other filters.
This no-login approach is for public listing cards. It is not a profile scraper, recruiter contact finder, message automation tool, or bypass for pages LinkedIn puts behind login. For official job posting integrations, review LinkedIn Talent documentation such as the XML feed development guide.
Technical access is not permission. Check LinkedIn's User Agreement, robots directives, privacy rules, contracts, and local regulations before reuse.
Workflow anatomy
How the no-login LinkedIn job scraper works
The JSON export is the authoritative workflow definition. The bundled template uses LinkedIn's public jobs-guest listing endpoint with predictable start offsets:
Navigate batch URLs -> Wait for page load -> Sleep briefly
-> Check for .job-search-card -> Structured Export -> Loop Continue
If .job-search-card exists, UScraper exports one row per card. If LinkedIn returns an authwall, empty result, or a page without cards, the workflow exits cleanly.
| Block | What it does | What to verify |
|---|---|---|
| Navigate | Opens each configured public batch URL | Replace sample keyword, location, and start offsets. |
| Wait for Page Load | Gives the endpoint time to render or redirect | Watch the first few pages. |
| Sleep | Adds a short pacing gap | Increase only if pages load slowly in your environment. |
| Element Exists | Checks for .job-search-card rows | Empty results usually mean no cards, an authwall, or layout drift. |
| Structured Export | Appends card fields to CSV | Confirm filename, save folder, headers, and append mode. |
| Loop Continue | Advances to the next offset | Keep this at the end of the success path. |
Runbook
How to scrape LinkedIn jobs without login
Import the template
Open the LinkedIn Job Scraper No Login Required page, download the JSON, and import it into UScraper.
Build the search
Decide how to search jobs on LinkedIn: keyword, location, date posted, remote or hybrid preference, and any company or experience filters.
Edit the Navigate URLs
Replace the sample keywords=Senior%20Digital%20Designer and location=United%20States values with your approved search terms.
Set the export path
In Structured Export, confirm linkedin-job-search-scraper-by-url.csv, headers, append mode, and the local save folder.
Run a short batch
Process two or three offsets while watching the browser. Stop if LinkedIn returns no cards, a login wall, or repeated blank rows.
Validate the CSV
Compare several rows against live cards, dedupe by job URL or job ID, then expand the offset list only after the export is auditable.
Output
LinkedIn jobs to CSV: fields to validate
There is no bundled CSV sample for this template. Use the export shape in the JSON definition, then treat your first validation run as the real sample. Listing-card fields are most reliable because they are visible in the public batch response.
linkedin-job-search-scraper-by-url.csvColumn
title
Visible job title from the public job card.
Column
company_name
Employer name from the card subtitle.
Column
location
Location text displayed on the card.
Column
published_at
Machine-readable date from the time element when present.
Column
job_url
LinkedIn job detail URL from the card.
Column
id
Best-effort job ID from the card metadata or URL.
Column
company_url
Company profile URL when exposed.
Column
company_logo_url
Logo image URL from the listing card.
Column
search_keywords
Keyword parameter from the current batch URL.
Column
search_location
Location parameter from the current batch URL.
Column
batch_start
Pagination offset used for the batch.
| Field group | Columns included |
|---|---|
| Listing basics | title, company_name, location, published_at, published_relative, benefits |
| Links and IDs | id, job_url, apply_url, company_url, company_id, company_logo_url |
| Optional public signals | applications_count, apply_type, salary, contract_type, work_type, sector, experience_level |
| Detail placeholders | description, description_html, poster_full_name, poster_profile_url |
| Search context | search_keywords, search_location, batch_start |
Use job_url or id as your dedupe key. Blank optional columns usually mean the data was not present in the public listing-card HTML.
Troubleshooting
Common issues: empty batches, authwalls, and blank columns
Run the first export with the browser and CSV open side by side. Check the first row, last row, one recent job, and one blank optional field.
| Symptom | Likely cause | Fix |
|---|---|---|
| CSV exists but has no rows | The current batch returned no .job-search-card elements | Open the URL manually and confirm the search has public cards. |
| Every offset stops quickly | LinkedIn returned an authwall, empty response, or changed markup | Reduce to one URL, inspect the response, and pause if access prompts appear. |
| Many duplicates | The same offsets were rerun in append mode | Dedupe by job_url or id, then clear the file before another test. |
| Salary or applicants are blank | LinkedIn did not show those fields in the listing card | Leave them blank unless the field is visibly present. |
| Search terms are wrong | Encoded URL parameters were edited inconsistently | Rebuild the search URL carefully and keep one keyword-location pair per batch. |
Tool choice
LinkedIn job scraper alternatives: template, code, hosted actor, or feed
The best LinkedIn job scraper depends on the owner of the workflow and the data-use review behind it.
| Option | Best fit | Trade-off |
|---|---|---|
| UScraper no-login template | Analyst-led CSV exports from public listing cards | You manage search scope, validation, pacing, and compliance review. |
| Python, Selenium, Playwright, Puppeteer, or Scrapy | Engineering-owned scraping with tests and storage | More control, more maintenance and policy review. |
| Hosted actors or scraper APIs | Managed infrastructure, scheduling, and dataset delivery | Data runs through vendor infrastructure and billing may scale with volume. |
| LinkedIn Talent XML feeds or posting APIs | Approved job posting integrations | Designed for posting or managing jobs, not general public search exports. |
If the deliverable is a spreadsheet, start with a short UScraper run from the template library. For production data services, involve engineering and legal before choosing a code scraper, hosted actor, or API route.
FAQ
Frequently asked questions
The UScraper template targets publicly returned LinkedIn job listing cards and does not automate account login. It stops when LinkedIn returns an authwall, empty batch, or page shape without job cards.
Next step
Download the LinkedIn job scraper no login template
Use this tutorial as the runbook and the LinkedIn Job Scraper No Login Required page as the download path. Import the JSON, run two or three offsets, inspect the CSV, then expand only after rows are consistent.
For adjacent workflows, browse UScraper templates, compare related job-board tutorials in the UScraper blog, or use a detail-page template when your approved workflow starts from a known list of job URLs.