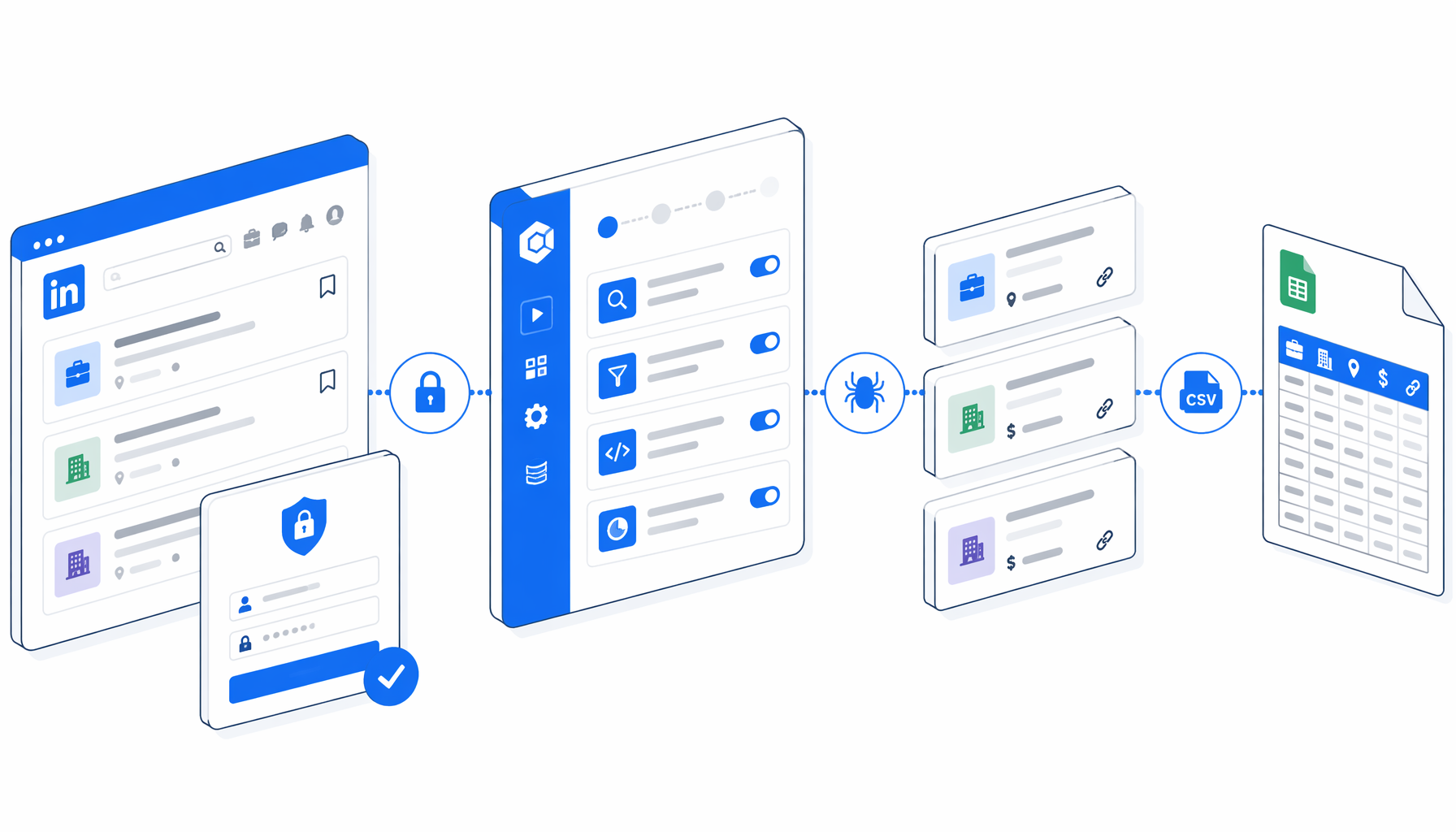
This LinkedIn job scraper tutorial shows how to export LinkedIn Jobs search results into CSV when a signed-in browser session is required. You will import the LinkedIn Job Scraper Login Required template, prepare the search, set the export path, validate a short run, and fix blank-row issues before scaling.
Before you start
Prerequisites for scraping LinkedIn jobs after login
You need UScraper as a local desktop app, the LinkedIn Job Scraper Login Required template, a browser profile that can view your target LinkedIn Jobs search, and a CSV folder. The template does not automate login, CAPTCHA, MFA, checkpoints, cookie copying, or access-control bypasses.
Start with one narrow query. Learn how to search jobs on LinkedIn, apply filters for title, location, date posted, work style, and company, then copy the search URL. The bundled workflow uses sample URLs and start= offsets from 0 through 975; replace them with approved searches.
Review LinkedIn's User Agreement, robots directives, internal data policy, and applicable employment-data or privacy rules. For official posting workflows, start with the LinkedIn API documentation and Job Posting API overview.
A signed-in page is still not automatic permission to collect or reuse data. Keep runs modest, stop when LinkedIn shows access prompts, and get legal review before commercial workflows.
Workflow anatomy
How the LinkedIn job scraper workflow works
The JSON export is the authoritative workflow definition. In plain English:
Set Window Size -> Navigate URL offsets -> Wait for Page Load -> Sleep
-> Check for job cards -> Wait for job cards -> Structured Export -> Loop Continue
The Element Exists block checks LinkedIn job-card selectors before extraction. If a page is empty, blocked, redirected, or too slow, the false branch moves to Loop Continue instead of forcing junk rows into the CSV.
| Workflow block | Purpose | Validation check |
|---|---|---|
| Set Window Size | Uses a consistent viewport | Keep layout-dependent selectors stable. |
| Navigate | Loops through configured LinkedIn Jobs URLs | Replace sample URLs with approved searches and offsets. |
| Wait for Page Load and Sleep | Allows LinkedIn to render or redirect | Watch the first pages before running unattended. |
| Element Exists | Confirms job cards are present | Timeouts usually mean authwall, empty search, or layout drift. |
| Structured Export | Appends visible fields to CSV | Confirm file name, save folder, headers, and append mode. |
| Loop Continue | Advances to the next URL | Keep it at the end of success and skip paths. |
Runbook
How to scrape LinkedIn jobs to CSV
Import the template
Open the LinkedIn Job Scraper Login Required page, download the JSON, and import it into UScraper.
Prepare the browser session
Open LinkedIn manually in the browser profile UScraper will use. Complete verification, then confirm a normal Jobs page displays job cards.
Edit the Navigate URLs
Replace the sample URLs with approved role, region, filter, and start= offset URLs.
Set the export path
In Structured Export, confirm the CSV name, headers, append mode, and save folder.
Run a small validation batch
Start with two or three offsets while watching the browser. Stop on authwalls, checkpoints, CAPTCHA, blank pages, or redirects.
Validate before scaling
Compare rows against live cards, dedupe by job URL, and widen the URL list only after core fields look plausible.
Output
LinkedIn jobs to CSV: export shape
There is no bundled CSV sample, so use the JSON export and your first validation run as the source of truth. Listing fields are usually more reliable than detail and company fields because optional panels vary by account, region, job status, and page state.
linkedin-job-scraper-login-required.csvColumn
Title
Visible job title from the result card.
Column
Title_URL
LinkedIn job detail URL.
Column
Company
Employer name from the listing card.
Column
Location
Location, remote, hybrid, or on-site text.
Column
Salary
Salary snippet when displayed.
Column
Updated
Visible posting or update date.
Column
About_the_job
Best-effort detail text when rendered.
Column
Company_URL
Company profile URL.
Column
Company_size
Employee range.
| Field group | Columns included |
|---|---|
| Run context | Result_count, Current_Page, Page_URL |
| Job listing | Title, Title_URL, Image, Company, Location, Salary, Updated |
| Job signals | Count_of_people_clicked_apply, Job_preference_1, Job_preference_2, Job_preference_3, Job_preference_4 |
| Detail and company | About_the_job, Company_URL, Company_follower, Company_size, Count_of_employee_onLinkedIn, Company_Intro |
Use Title_URL as the primary dedupe key. If optional fields are blank, confirm LinkedIn rendered them in the browser.
Validation
Common LinkedIn job scraper issues and fixes
Run the first export with the browser and CSV open side by side. Check the first row, last row, one salary row, and one skipped page.
| Symptom | Likely cause | Fix |
|---|---|---|
| CSV exists but has no rows | No matching job cards rendered | Open the current URL and check for authwall, checkpoint, or empty search. |
| Only title and URL look reliable | Detail panel or company box did not render | Treat listing fields as the main dataset and optional fields as best effort. |
| Many rows are duplicated | Append mode reran the same offsets | Dedupe by Title_URL or start with a fresh file. |
| Salary is blank | LinkedIn did not display pay data on that card | Do not infer missing salary; validate against the live page. |
| Every page is skipped | Session changed, page was throttled, or selectors drifted | Pause, reload one URL manually, and rerun a two-offset test. |
Tool choice
LinkedIn job scraper alternatives: local workflow, code, or API
The best LinkedIn job scraper depends on who owns the workflow. UScraper fits analyst-led CSV exports where browser state, row output, and local file path need to stay visible.
| Option | Best fit | Trade-off |
|---|---|---|
| UScraper template | Supervised CSV export from a signed-in local desktop app session | You manage scope, pacing, and access state. |
| Python, Selenium, Playwright, Puppeteer, or Crawlee | Engineering-owned scraping with tests and storage | More control, more maintenance. |
| Hosted actors and scraper APIs | Managed infrastructure, scheduling, and dataset delivery | Data runs through vendor infrastructure and may bill per run. |
| LinkedIn Job Posting API | Approved partners posting and managing jobs through LinkedIn | Official route for posting workflows, not a general job-search export. |
If the deliverable is a reviewable spreadsheet, validate a short run from the template library. If it is a production data service, involve engineering and legal before choosing a code scraper, cloud actor, or API route.
FAQ
Frequently asked questions
LinkedIn Jobs pages can be governed by LinkedIn's User Agreement, robots directives, privacy law, copyright rules, and local regulations even after login. Do not bypass authwalls, CAPTCHA, MFA, or technical controls.
Next step
Download the LinkedIn job scraper template
Use this article as the runbook and the LinkedIn Job Scraper Login Required page as the download path. Import the JSON, run two or three offsets, validate the CSV, then expand only after rows are auditable. For adjacent workflows, browse UScraper templates or the UScraper blog.