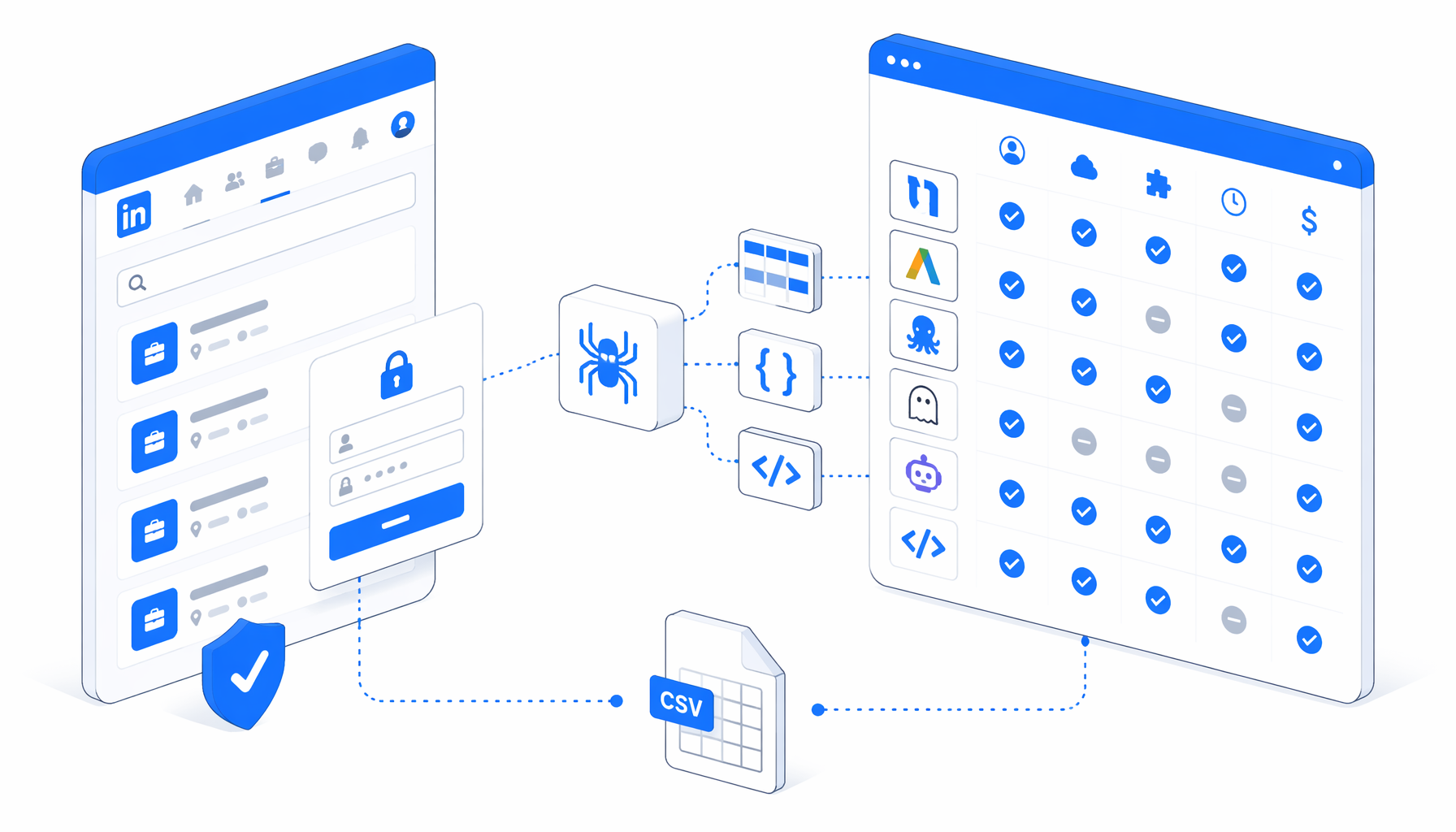
The best LinkedIn job scraper is the one that matches your access model, compliance posture, output format, and maintenance capacity. This comparison covers UScraper, Apify, Octoparse, PhantomBuster, Browse AI, Bright Data, LinkedIn API routes, and scripts for exporting LinkedIn Jobs data to CSV.
Decision frame
What makes LinkedIn job scraper alternatives hard to compare
Most searches for linkedin job scraper alternatives mix three workflows: job discovery from LinkedIn Jobs filters, detail extraction from visible job cards, and production ingestion into databases or alerting systems. A recruiter who needs a reviewed CSV is not buying the same thing as a developer searching for a LinkedIn Jobs API alternative with data contracts and uptime.
Start with custody, permission, and output. Throughput only matters after you know the source access is acceptable and the rows are trustworthy.
Before automating LinkedIn Jobs, review the official LinkedIn Jobs source, LinkedIn User Agreement, robots directives, and LinkedIn developer documentation. Browser access does not automatically grant reuse, resale, enrichment, or model-training rights.
Comparison
LinkedIn job scraping tools compared
Pricing and platform limits change, so treat this as a buying model, then check Apify pricing, Octoparse pricing, and PhantomBuster pricing before procurement.
| Option | Best fit | Hosting | Code required | Pricing shape | Output notes |
|---|---|---|---|---|---|
| UScraper LinkedIn Job Scraper Login Required | Recruiters, analysts, agencies, and researchers who want a supervised export after login | Local desktop app | No-code visual workflow; selectors and JavaScript columns are inspectable | Free template; UScraper product plan applies | CSV with job, company, location, salary, freshness, preference labels, detail text, and company fields |
| Apify LinkedIn Jobs actors | Developers who want cloud actor runs, datasets, schedules, and APIs | Hosted actor marketplace | Config-first; API optional | Usage-based platform billing plus actor economics | Strong for cloud pipelines; compare actor freshness, fields, proxy needs, and run cost |
| Octoparse LinkedIn Job Listing Scraper | Analysts who want a mature visual scraping platform and hosted template library | Visual SaaS with cloud options by plan | No-code to low-code | Subscription tiers and plan limits | Good no-code experience; local custody is less central |
| PhantomBuster LinkedIn Job Scraper | Sales, recruiting, and automation teams chaining LinkedIn workflows | Hosted automation platform | No-code; session setup required | Subscription and execution limits | Useful when extraction feeds broader automation |
| Browse AI LinkedIn job robots | Teams monitoring a search page or extracting job detail pages through hosted robots | Hosted SaaS | No-code | Plan or credit-based SaaS | Better for monitored robots and integrations than local file custody |
| Bright Data LinkedIn Scraper | Engineering and data teams needing vendor-supported web data infrastructure | Vendor API or dataset platform | API integration | Contract or usage-based data product | Strong when procurement, support, and structured delivery matter |
| JobSpy, Python packages, or custom scripts | Engineers who own parser logic, retries, storage, and tests | Local, server, notebook, or container | Code required | Open-source plus infrastructure and engineering time | Maximum control; less friendly for non-engineers who need a repeatable CSV workflow |
UScraper fit
Where UScraper wins honestly
UScraper is strongest when the job is a controlled LinkedIn Jobs export from a signed-in browser profile. The template sets a large viewport, opens LinkedIn Jobs search URLs, waits for rendered job cards, skips empty or blocked pages, and appends visible fields to a local CSV. It does not automate login, CAPTCHA, or MFA.
That makes it useful for teams that care about reviewability. You can inspect the browser state, workflow blocks, JSON template, and CSV. The bundled workflow includes 40 offsets from start=0 through start=975, and you can replace the sample URLs with approved searches.
UScraper wins. The workflow runs in a local desktop app and writes a normal CSV to the configured save folder instead of routing every run through a hosted actor.
UScraper wins. Blocks for navigation, waiting, existence checks, structured export, and loop continuation are visible, so analysts can reason about what happened.
Apify, Bright Data, or an API wins. If the data must flow into production systems through APIs, webhooks, queues, and scheduled hosted runs, a cloud stack is the better default.
Where others win
When another LinkedIn jobs scraper is the better choice
No single tool should win every LinkedIn job scraping comparison. Apify is stronger for cloud actors, datasets, APIs, and run logs. Octoparse is stronger for hosted visual scraping. PhantomBuster fits LinkedIn automation chains. Browse AI fits monitoring and no-code alerts, while Bright Data fits vendor-supported data infrastructure.
Open-source tools such as JobSpy or custom Playwright scripts make sense when your team can maintain selectors, retries, storage, and compliance checks. Approved API access is usually cleaner for production integrations and commercial redistribution.
Output
Output shape: what a useful LinkedIn jobs CSV should include
The UScraper workflow definition is the authoritative sample for this template. It shows setup, multi-URL navigation, page-load waits, an Element Exists check for job cards, Structured Export, and Loop Continue. The export writes linkedin-job-scraper-login-required.csv in append mode with headers enabled.
| Column group | Fields | Why it matters |
|---|---|---|
| Run context | Result_count, Current_Page, Page_URL | Keeps rows traceable to source page and offset. |
| Job listing | Title, Title_URL, Image, Company, Location, Salary, Updated | Covers the fields recruiters compare first. |
| Job signals | Count_of_people_clicked_apply, Job_preference_1, Job_preference_2, Job_preference_3, Job_preference_4 | Captures demand and role attributes when rendered. |
| Detail text | About_the_job | Supports skill extraction, taxonomy review, and QA. |
| Company context | Company_URL, Company_follower, Company_size, Count_of_employee_onLinkedIn, Company_Intro | Adds employer context to hiring analysis. |
Because the bundle has no sample CSV, validate with a small approved search first. Run two or three offsets, then spot-check title, URL, company, location, blank optional fields, and duplicates.
Selection guide
Start with a small, reviewable run
The practical way to compare LinkedIn job scraping tools is to run a small test. Import the LinkedIn Job Scraper Login Required template, prepare a signed-in browser profile, replace the sample URLs with an approved search, and export a short CSV. Compare rows against the browser before increasing offsets.
If the workflow fits, keep raw exports separate from reviewed datasets. For adjacent job-board workflows, browse the template library or the UScraper blog.
Frequently asked questions
UScraper is strongest for supervised local CSV exports from a signed-in browser session. Apify, Bright Data, and scripts are stronger for developer-owned pipelines. Octoparse, Browse AI, and PhantomBuster fit hosted no-code operations.