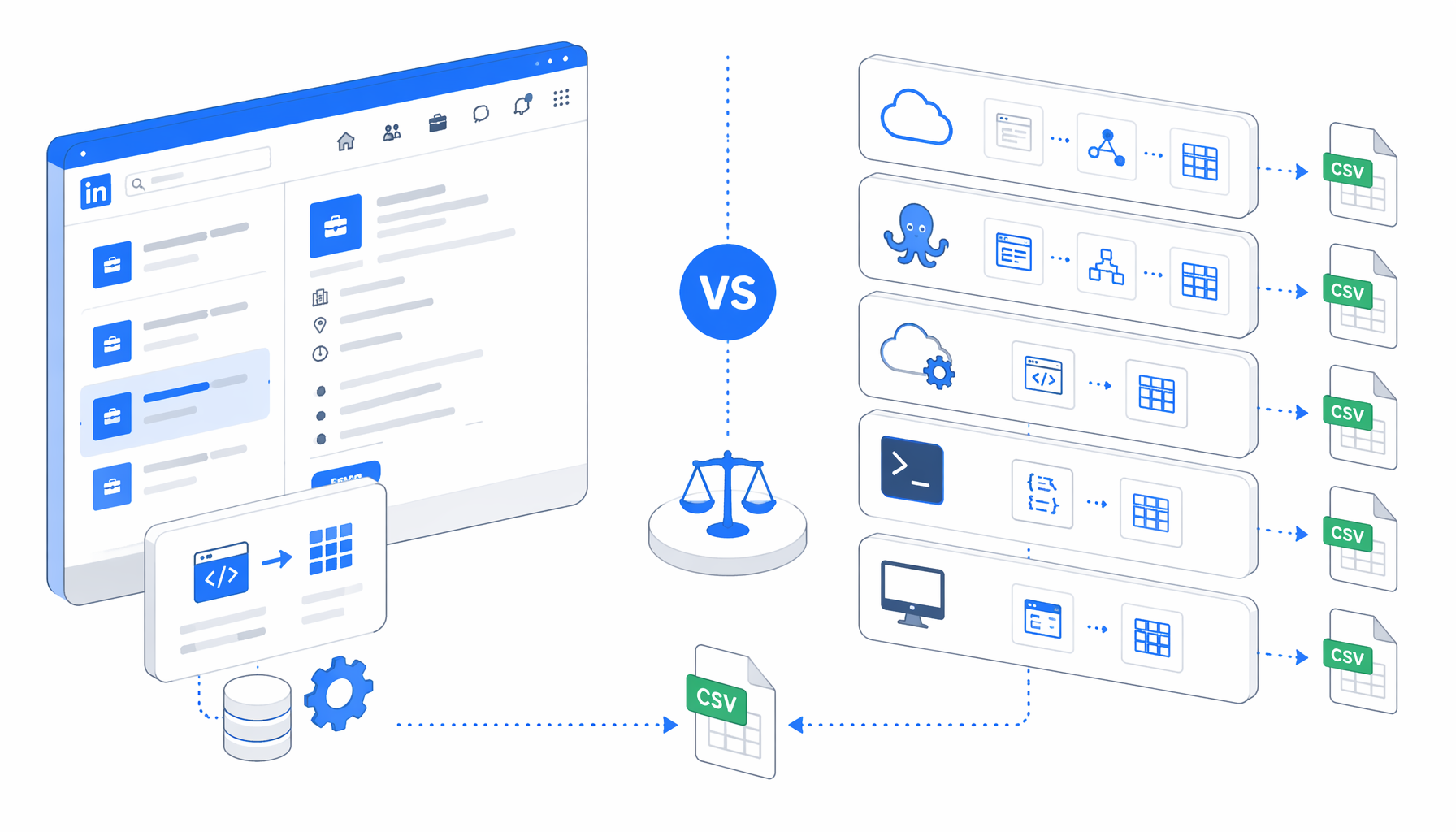
Choosing the best LinkedIn job scraper is really a hosting and ownership decision: cloud actor, no-code SaaS, managed API, open-source script, or local desktop app. This comparison shows where UScraper's LinkedIn Job Details Page Scraper template fits for CSV-first job research.
Comparison frame
What a LinkedIn job scraper has to solve
LinkedIn job pages are useful because they combine role, employer, location, hiring timing, taxonomy, compensation signals, and sometimes recruiter context. They are also sensitive to session state. A page can render normally in one browser profile, hide fields in another, redirect through an authwall, or return only partial public metadata.
That is why searches such as how to scrape LinkedIn jobs, LinkedIn job scraping tools, and LinkedIn jobs scraper comparison split into several lanes: official LinkedIn routes for approved Talent Solutions workflows, cloud actors such as Apify, no-code templates such as Octoparse, PhantomBuster, and Browse AI, managed providers such as Bright Data, scripts such as JobSpy or linkedin-jobs-scraper, and local desktop workflows such as UScraper.
The practical question is not "can this tool scrape LinkedIn?" It is "where does the browser run, who owns failures, what does each row cost, and can the team explain where the data went?"
Side-by-side
LinkedIn job scraper alternatives compared
| Option | Best fit | Hosting | Code needed | Output shape | Pricing shape | Main trade-off |
|---|---|---|---|---|---|---|
| LinkedIn Job Posting API | Authorized ATS and employer posting workflows | LinkedIn API | Developer integration | Job posting API responses | Partner/API access | Compliance-first, but not a search-results exporter |
| Apify LinkedIn jobs actor | Recurring hosted scraping and datasets | Apify cloud | Low to medium | Dataset, JSON, CSV | Platform usage plus actor costs | Good infrastructure; cloud custody |
| Octoparse LinkedIn job details template | No-code visual scraping | Vendor environment | Low | CSV, Excel | SaaS tiers and task limits | Convenient setup; less local ownership |
| Bright Data LinkedIn Jobs Scraper | Enterprise extraction or API delivery | Vendor infrastructure | Low to medium | API, JSON, datasets | Usage or dataset pricing | Strong scale; heavier than analyst CSV |
| PhantomBuster LinkedIn Job Scraper | Sales or recruiting automation | PhantomBuster cloud | Low | CSV, JSON, sheets | Subscription resources | Good automation surface; account governance matters |
| Browse AI LinkedIn jobs template | Cloud monitoring and bulk lists | Browse AI cloud | Low | Table, sheets, integrations | Subscription/task model | Fast start; less local review control |
| Open-source scripts and libraries | Engineering-owned parsers | Your stack | High | DataFrame, JSON, CSV | Engineering plus proxy/API cost | Maximum flexibility, maximum maintenance |
| UScraper + LinkedIn Job Details Page Scraper | Local CSV from known job URLs | Local desktop app | Low | CSV with 16 columns | Free template; app licensing applies | Best for inspectable local runs |
This is not a universal ranking. Enterprise procurement may prefer Bright Data. Engineers feeding a warehouse may prefer Apify or scripts. Analysts exporting a known URL list often need a simpler local workflow.
Where UScraper fits
When UScraper is the right LinkedIn job details scraper
The companion LinkedIn Job Details Page Scraper template is intentionally narrow. It expects LinkedIn job detail URLs, opens each one, waits for the page or authwall redirect, injects a normalizing JavaScript extractor, and appends one row per URL into linkedin_job_details_scraper_v2.csv.
The template exports Job_title, Job_link, Company, Company_link, Job_location, Post_time, Applicant_count, Job_description, Industry, Employment_type, Valid_through, Seniority_level, Job_function, Hiring_person, minPay, and maxPay.
That shape works for recruiting research, hiring-intent monitoring, compensation benchmarking, job-board cleanup, and AI training-data preparation where the source URLs are already selected. It is a detail-page extractor for controlled batches, not a massive LinkedIn search crawler.
UScraper wins when rows should stay in folders your team administers.
Hosted tools win for scheduling, retries, proxy pools, APIs, and concurrency.
UScraper wins when analysts need visible waits, JavaScript, and export columns.
Scripts win for full code ownership; UScraper wins for operator-owned maintenance.
Where alternatives win
When Apify, Octoparse, Bright Data, PhantomBuster, Browse AI, or scripts make more sense
Choose Apify for cloud actors, API orchestration, hosted datasets, and repeatable jobs that other systems trigger. Choose Octoparse when a no-code team wants a visual task builder. Choose Bright Data when procurement values managed infrastructure and support. Choose PhantomBuster when scraping sits inside sales or recruiting automation. Choose Browse AI for cloud monitoring and spreadsheet sync. Choose open-source scripts when developers need tests, custom parsing, queues, retries, and database writes.
Compliance
Legal and platform fit
Do not treat a CSV export as permission to reuse LinkedIn data. Review the LinkedIn User Agreement, robots directives, privacy obligations, client contracts, copyright, database rights, outreach rules, and local law. Do not bypass authwalls, CAPTCHA, MFA, rate limits, or technical controls.
The official LinkedIn Talent Solutions documentation is useful context, but the Job Posting API is for authorized posting and lifecycle workflows. It is not a drop-in replacement for exporting competitor job listings into a spreadsheet.
Decision guide
Which LinkedIn job scraping tool should you pick?
Pick official LinkedIn APIs for approved partner workflows. Pick Apify for hosted actors and programmable datasets. Pick Octoparse for no-code scraping. Pick Bright Data for managed extraction and support. Pick PhantomBuster or Browse AI for broader cloud automation. Pick scripts when engineering will own the parser.
Pick UScraper when the job is more concrete: import the template, add LinkedIn job detail URLs you are allowed to process, run with an authorized browser profile, verify the CSV, and keep the workflow inspectable. Start with the LinkedIn Job Details Page Scraper template, then browse the UScraper template library or return to the blog for related tutorials and comparisons.
FAQ
The best LinkedIn job scraper depends on scale, data custody, and maintenance ownership. Use hosted actors or managed APIs for high-volume cloud jobs, scripts when engineers own parsing, and UScraper when analysts need a local desktop workflow that exports approved job detail URLs to CSV.