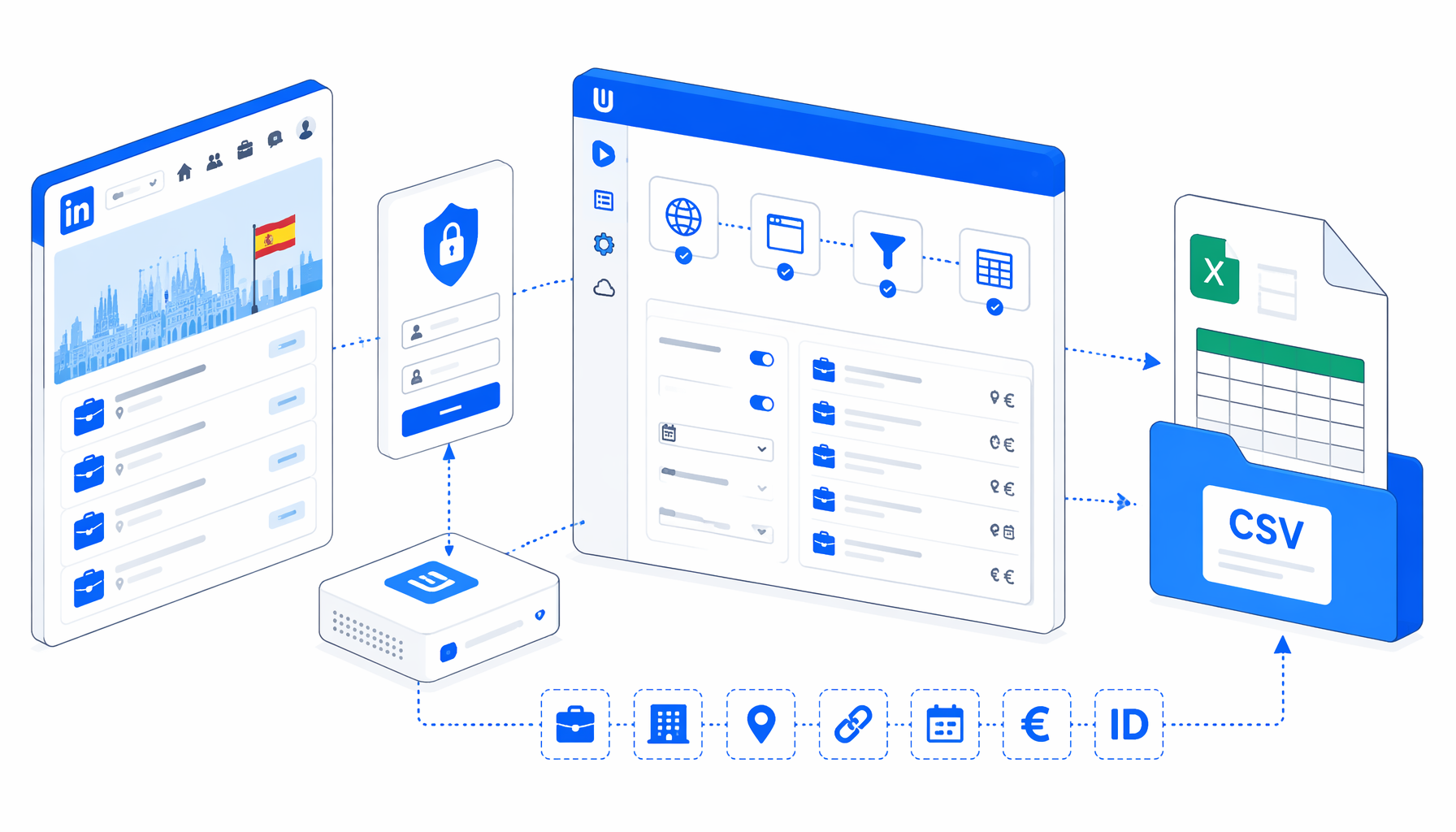
This LinkedIn job scraper tutorial shows how to collect LinkedIn Spain job cards into CSV with the LinkedIn Español Empleo Scraper (requiere Login) template for UScraper. You will import the workflow, understand the login-required caveat, choose an export path, run a small validation batch, and decide when a local desktop app is the right path.
Before you start
Prerequisites and boundaries
You need UScraper installed as a local desktop app, the related LinkedIn Spain jobs template, and a folder where the CSV can be written. Start with the bundled Spain search offsets before changing keywords, location text, or pagination depth.
This template is best-effort. The supplied JSON notes that normal LinkedIn Jobs search pages redirected to an authentication wall during testing, so the workflow uses LinkedIn guest job-posting fragment URLs with location=Spain, geoId=105646813, and known start offsets. LinkedIn may still require login, show a checkpoint, return CAPTCHA, alter parameters, or rate-limit the session.
Review LinkedIn's current User Agreement, robots.txt, your internal data policy, and applicable privacy or employment-data rules before running automated collection.
A scraper is a collection method, not a permission model. Keep runs proportionate, do not bypass access controls, and stop when a site asks for verification.
Workflow anatomy
How the LinkedIn Spain job scraper works
The workflow is deliberately small: Set Window Size -> Navigate -> Wait for Page Load -> Wait for Element -> Structured Export -> Sleep -> Loop Continue. The Navigate block owns the result-page fragments. The Wait for Element block checks for .base-search-card or .job-search-card. Structured Export appends one row per job card found on the current fragment page.
The JSON export is the authoritative workflow definition. In plain English, it loops through ten Spain offsets, waits for job cards, and writes the same column set into one CSV file.
{
"urls": [
"https://www.linkedin.com/jobs-guest/jobs/api/seeMoreJobPostings/search?keywords=&location=Spain&geoId=105646813&start=0",
"https://www.linkedin.com/jobs-guest/jobs/api/seeMoreJobPostings/search?keywords=&location=Spain&geoId=105646813&start=25",
"https://www.linkedin.com/jobs-guest/jobs/api/seeMoreJobPostings/search?keywords=&location=Spain&geoId=105646813&start=50"
],
"rowSelector": ".base-search-card, .job-search-card",
"fileName": "linkedin_espana_empleo_scraper_requiere_login.csv",
"fileMode": "append",
"columns": ["job_title", "company", "location", "job_url", "job_id", "posted_date", "salary", "easy_apply", "promoted"]
}
| Block | What it does | Validation check |
|---|---|---|
| Set Window Size | Opens a consistent browser viewport | Keep layout-dependent selectors stable. |
| Navigate | Loops through Spain job fragment URLs | Confirm offsets match the result depth you want. |
| Wait for Element | Waits for LinkedIn job-card selectors | A timeout usually means authwall, checkpoint, empty result, or layout change. |
| Structured Export | Appends job-card fields to CSV | Check filename, headers, save folder, and duplicate rows. |
| Loop Continue | Advances to the next URL in the list | Keep it at the end of the loop body. |
Runbook
How to scrape LinkedIn jobs to CSV
Import the workflow
Open the LinkedIn Spain jobs scraper template, download the JSON workflow, and import it into UScraper.
Confirm the access state
Open the first bundled URL in the browser session you plan to use. Continue only if your policy allows that access state and LinkedIn is showing job cards, not a checkpoint or blocked page.
Tune the search scope
In Navigate, keep the Spain geoId=105646813 unless you are deliberately changing markets. Add keywords only after the original blank-keyword export works.
Set the export folder
In Structured Export, confirm linkedin_espana_empleo_scraper_requiere_login.csv, headers, append mode, and the save location you want for this research run.
Validate before scaling
Run one offset, inspect several rows against the page, then widen the Navigate list only after title, company, location, URL, date, and job ID look correct.
Output
Export shape and validation checks
There is no bundled CSV sample for this template, so the JSON export is the reliable source for the output shape. Treat the first run as your sample: open the CSV, click several job_url values, and compare the row to the rendered card.
linkedin_espana_empleo_scraper_requiere_login.csvColumn
job_title
Visible job-card title from the LinkedIn result card.
Column
company
Company subtitle or linked company name.
Column
location
Visible job location text from the card.
Column
job_url
Source LinkedIn job URL for review and dedupe.
Column
job_id
Extracted from the job URL when the ID pattern is present.
Column
posted_date
Visible posting age or date text.
Column
posted_datetime
Datetime attribute from the time element when available.
Column
salary
Salary card text when LinkedIn exposes it.
Column
easy_apply
True when the card text contains Easy Apply or solicitud sencilla.
Column
promoted
True when the card text contains promoted or promocionado.
Column
card_text
Raw card text for QA when a specific field is blank.
Use job_id or job_url as the dedupe key. Use card_text to troubleshoot missing fields before editing selectors. If salaries or posting dates are blank, confirm that LinkedIn exposed those values on the card; the workflow cannot export fields that were never rendered.
Alternatives
LinkedIn job scraper options and trade-offs
The "best LinkedIn job scraper" depends on the job you need done. UScraper is strongest when an analyst wants a local desktop app, visible browser QA, and a CSV file they can inspect immediately. Other tools make sense when you need managed infrastructure, cloud scheduling, proxy handling, or API delivery.
| Option | Best fit | Trade-off |
|---|---|---|
| UScraper template | Local CSV workflow with visible browser validation | You manage access state, scope, and troubleshooting. |
| Octoparse login-required template | No-code cloud or desktop-style template users | Output and pricing depend on the provider workflow. |
| PhantomBuster job scraper | Hosted automation from job URLs or search inputs | Requires cloud execution and account/session configuration. |
| Bright Data or Apify | API or hosted scraper delivery | Better for managed scale, less direct local custody. |
| Python libraries such as JobSpy | Developer-controlled extraction pipeline | Requires code, dependencies, and maintenance. |
For an Octoparse LinkedIn scraper alternative, the practical question is not only whether the fields can be extracted. Ask where the data runs, where the CSV is saved, how easy the first-row QA is, and whether you need a hosted scheduler or a local workflow.
Troubleshooting
Common issues with login-required LinkedIn jobs
The template cannot bypass an authwall. Confirm whether your allowed workflow includes a signed-in browser session. If not, stop the run or switch to an approved data source.
FAQ
FAQ
Is it legal to scrape LinkedIn jobs?
LinkedIn job pages may be visible in a browser, but automated access can still be limited by LinkedIn's User Agreement, robots rules, account controls, copyright, privacy law, and employment-data rules. Review the current policies, avoid bypassing access controls, keep collection proportionate, and get legal advice before commercial use.
Why does this LinkedIn job scraper mention login required?
During testing, normal LinkedIn Jobs search URLs redirected to an authentication wall. The UScraper template therefore uses public guest job-posting fragment URLs for Spain with offset pagination, while still warning that LinkedIn may require login, show CAPTCHA or checkpoint pages, alter parameters, or rate-limit requests.
What does the LinkedIn Spain jobs CSV export?
The workflow exports job_title, company, location, job_url, job_id, posted_date, posted_datetime, salary, image_url, image_alt, easy_apply, promoted, and card_text columns into linkedin_espana_empleo_scraper_requiere_login.csv.
Can I use this instead of Octoparse, PhantomBuster, Apify, or Bright Data?
Use UScraper when you want a local desktop app workflow and CSV output you can inspect on your machine. Hosted products and APIs may be a better fit for managed infrastructure, scheduling, proxy handling, large-scale datasets, or formal enterprise delivery.
Where does the CSV file go?
The template writes linkedin_espana_empleo_scraper_requiere_login.csv to the save location configured in the Structured Export block. Change that folder before running a production batch, especially if you keep separate exports for each keyword, region, or date.
Next step
Download the LinkedIn Spain jobs scraper
Use the LinkedIn Español Empleo Scraper (requiere Login) as the download and import path. For broader scraping workflows, browse the UScraper template library or return to the UScraper blog for more tutorials and comparisons.