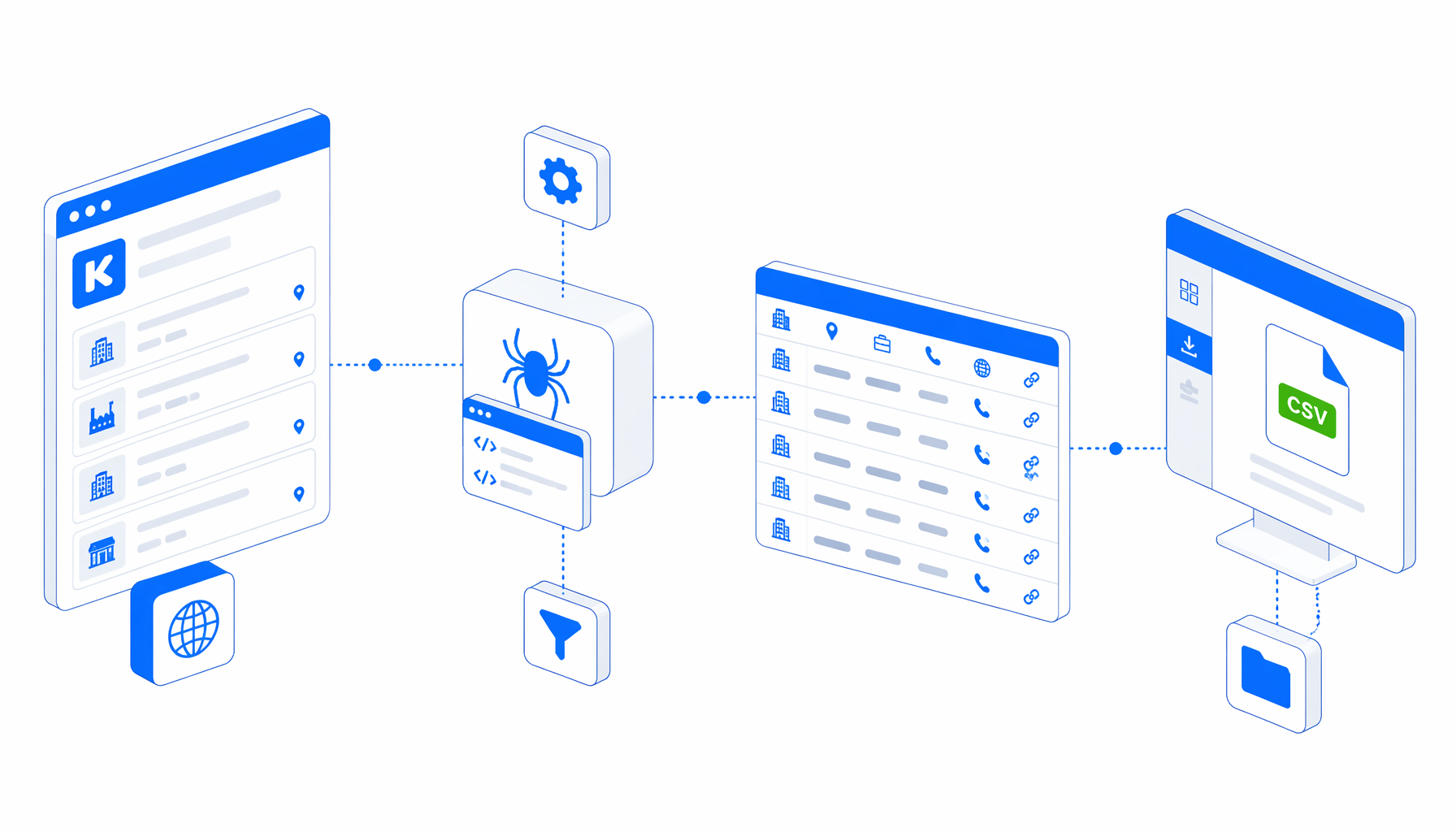
Kompass company data extraction is usually not a "scrape everything" problem. Research teams need a clean way to turn specific company detail pages into a CSV they can audit, filter, and hand to sales, editorial, SEO, or monitoring workflows. This use case explains when the Kompass Recherche Scraper template fits, what it exports, and when an official data package or hosted actor is the better choice.
Use case fit
Why teams scrape Kompass pages into CSV
Kompass is a B2B directory used for supplier discovery, company validation, and market research. The official ecosystem includes public directory pages, country portals, and paid sales tools such as EasyBusiness for prospecting and market analysis. That creates a common gap: a team may not need a contracted data feed yet, but it still needs a repeatable way to collect selected company details from reviewed pages.
Manual copy-paste works for five companies. It breaks at fifty. Names lose accents, phone numbers get reformatted, and the analyst forgets which source URL justified a row. A no-code Kompass scraper is useful when the problem is repeatable detail-page extraction, not a high-volume crawler.
The cleanest research workflow starts with a known list of company detail URLs, captures only the fields your team can justify, and keeps the source URL beside every row.
Personas
Four workflows that benefit from structured Kompass export
Market researchers use Kompass pages to profile suppliers by region, sector, and activity. A CSV export gives them a reviewable worksheet with company descriptions, locations, and websites before they merge data with internal CRM or procurement lists.
Export shape
What the Kompass Recherche Scraper template delivers
The template is detail-page driven. It opens URLs from the Navigate block, waits for the page, checks for DataDome or captcha-delivery interstitials, then runs Structured Export from the rendered page body. The key columns are:
| CSV column | Field purpose | Typical downstream use |
|---|---|---|
nom_de_l_entreprise | Company name as shown on Kompass | Deduplication, CRM matching, report title |
lieu | Location text | Territory filters and regional mapping |
presentation | Company description or profile text | Research notes, entity summaries, analyst review |
fournisseur | Supplier, activity, or category signal | Industry segmentation and competitor grouping |
telephone | Phone value visible in the session | Contact validation and enrichment checks |
site_de_l_entreprise | Company website URL | Outreach review, SEO checks, account research |
url_de_la_page_detaillee | Exact Kompass detail page URL | Audit trail and source verification |
For the bundled TotalEnergies sample URL, the JSON includes fallback preview values if the browser hits a DataDome interstitial. For accessible pages, it extracts from the live DOM. That behavior matters: a blocked session should not be mistaken for a successful refresh.
Workflow
From pain to outcome in five steps
Collect approved detail URLs
Start from Kompass pages your team already reviewed, an internal research shortlist, or a legally approved source list. The template is not designed to discover every company automatically.
Import the JSON template
Download the free workflow from Kompass Recherche Scraper and import it into UScraper so Navigate, waits, checks, export columns, and loop continuation are already wired.
Replace the sample URL list
Put your Kompass detail URLs into the Navigate block. Keep the page-load wait, body wait, short sleep, and DataDome check until you have tested real pages.
Set the local CSV destination
Structured Export writes kompass-recherche-scraper.csv with headers and append mode. Use a campaign-specific folder when the research will be reviewed by other teams.
Run, audit, then enrich
Export a small batch first, compare rows against on-screen pages, then enrich the CSV with CRM IDs, notes, or classification fields outside the scraper.
The result is a reproducible process: the same URLs, columns, file name pattern, and source URL beside every extracted row.
Alternatives
Kompass scraper alternative vs API vs managed service
There is no universal "best Kompass scraper." The right option depends on scale, paperwork, and who owns maintenance.
| Option | Best fit | Trade-off |
|---|---|---|
| UScraper Kompass Recherche Scraper | Analyst batches, known detail URLs, local CSV review, no-code selector edits | You supply URLs and maintain selectors when the page layout changes |
| Octoparse Kompass templates | Hosted no-code teams that already use Octoparse | Project behavior and runtime sit inside another platform |
| Apify Kompass actor or Spider listing | API-style runs, cloud orchestration, larger extraction jobs | Usage-based cloud costs and third-party processing |
| Thunderbit Kompass template | AI-assisted browser extraction into common work tools | Good for quick capture; validate schema control for repeatable research |
| Official Kompass data or EasyBusiness | Contracted prospecting, licensed data access, procurement-grade scale | Requires commercial evaluation rather than a same-day CSV workflow |
Use the local template when you need to answer: "Can we extract these seven fields reliably for this specific research batch?" Use an official route or managed vendor when you need guaranteed access, broader coverage, service terms, and scale.
Guardrails
Compliance and data-quality guardrails
Kompass terms of use, its general data use policy, and regional privacy rules should shape the job before you press Run. CNIL guidance on web scraping and legitimate interest emphasizes safeguards when collecting personal data available online, especially when business profiles expose contact details.
Data quality needs its own checks. Spot-check the first ten rows, deduplicate on company name plus source URL, and keep blocked-page notes visible. If the template detects a captcha or DataDome interstitial, pause and decide whether your use case belongs in an official data channel.
Frequently asked questions
It is best for analyst-led B2B research when you already have approved Kompass detail URLs and need a repeatable CSV with company name, location, presentation, activity, phone, website, and source URL.