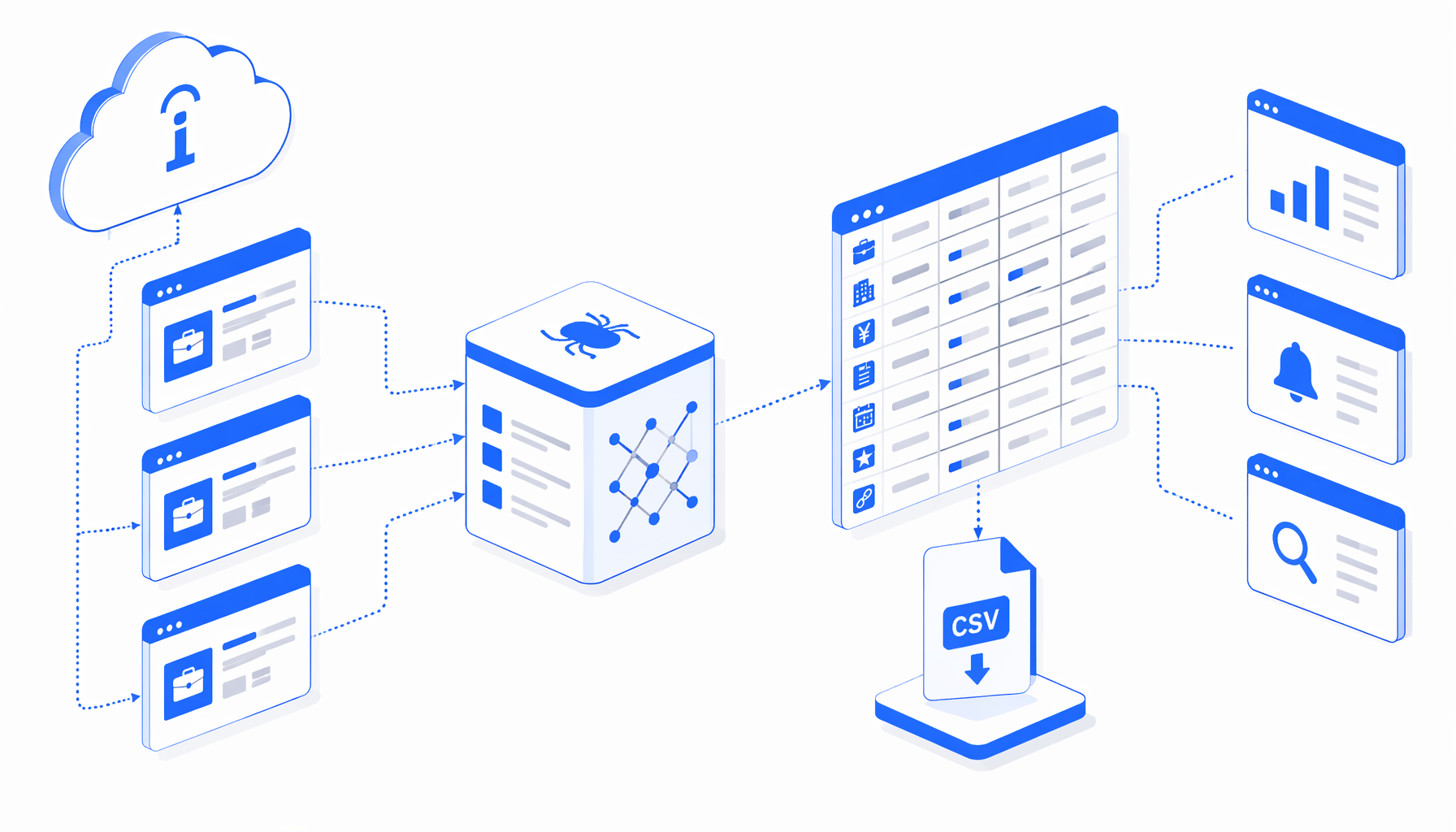
Indeed Japan job data extraction is useful when the team already has reviewed jp.indeed.com job URLs and needs a structured file for analysis. The Indeed Japan Job Scraper by URL template turns job-detail and search-result pages into a CSV with job title, company, location, salary, employment type, posted date, rating, source URL, and timestamp fields.
Problem
Why Indeed Japan research gets messy in browser tabs
Manual job research starts cleanly: search Indeed Japan, open a few listings, copy titles and salaries into a spreadsheet, then add notes for a client, editor, or analyst. The problem appears when the list grows. Tabs expire, copied URLs lose their original query, salary phrases mix hourly and annual formats, and nobody can explain whether a blank row means "no salary listed" or "the page did not load."
That is why a URL-based Indeed Japan job scraper is useful for research workflows. It does not try to replace judgment. It standardizes the capture step after a human has decided which job-detail pages or search-result URLs are in scope.
The valuable file is not just a list of jobs. It is a traceable snapshot: source URL, page URL, extracted fields, timestamp, and a clear marker when the page asked for additional verification.
Before automating collection, review the current Indeed Japan site, Indeed legal policies, robots.txt, and your own data-use rules. Browser-visible pages can still be governed by terms, access controls, privacy obligations, copyright, database rights, and downstream reuse limits.
Personas
Who uses a job postings scraper for Japan workflows?
| Persona | What they need | Why a CSV helps |
|---|---|---|
| Research teams | Hiring-market snapshots for roles, sectors, or cities | Normalize titles, employers, locations, salary text, source URL, and scrape time before analysis. |
| Newsrooms | Evidence trails for stories about hiring, wages, or skill demand | Keep source pages and run dates beside notes so editors can recheck claims. |
| SEO teams | Competitor hiring pages, keyword demand, and local intent clues | Compare job language, employer categories, and location modifiers across reviewed searches. |
| Recruiting agencies | Client discovery and employer targeting | Filter by company, role, salary phrase, employment type, and posting recency before manual outreach. |
| Monitoring teams | Recurring checks on the same approved search URLs | Compare raw exports by date instead of rebuilding spreadsheets from memory. |
Searches such as scrape job postings, scrape job boards, scrape Indeed Japan jobs, and indeed job data extraction usually point to the same operational need: turn unstable browser sessions into rows a team can audit, filter, and discuss.
Workflow
How the template turns URLs into structured export rows
The workflow is built around a clear path: Navigate -> wait for page load -> wait for body -> detect verification -> export blocker row or job rows -> check pagination -> click Next when available -> continue to the next input URL.
The Navigate block holds the supplied Indeed Japan URLs. The workflow can process direct /viewjob pages and accessible /jobs search-result pages. For search results, it exports visible job cards, checks for an enabled Next pagination link, waits after the click, and appends more rows until pagination ends or the next input URL begins.
| Workflow part | What it controls | Why it matters |
|---|---|---|
| Input URLs | The reviewed jp.indeed.com pages | Scope is explicit and repeatable. |
| Verification branch | Indeed or Cloudflare additional-verification pages | Blocked runs become diagnostic rows, not silent blanks. |
| Structured Export | CSV filename, headers, append mode, and columns | Analysts get one file with stable field names. |
| Pagination loop | Enabled Next links on search-result pages | Search pages can produce multiple pages of rows when accessible. |
| Timestamp | Current_Time formatted for Asia/Tokyo | Snapshots can be compared by run date. |
Output
What the Indeed jobs to CSV export contains
The bundle has no CSV sample, so the JSON workflow definition and your first validation run are the authoritative sample. The export is designed for spreadsheet review before the data enters a dashboard, sourcing sheet, newsroom notebook, or SEO research file.
jp-indeed-job-url-scraper-cloud.csvColumn
キーワード
Keyword from the q parameter when present.
Column
職位
Job title, or BLOCKED_BY_INDEED_VERIFICATION for verification pages.
Column
仕事内容詳細ページリンク
Job detail URL, canonical job URL, or current URL.
Column
会社名
Employer name when visible.
Column
職務内容詳細
Description, snippet, page text, or verification note.
Column
勤務地
Work location shown by Indeed Japan.
Column
給料
Salary phrase detected from yen, annual, monthly, hourly, or daily pay text.
Column
雇用形態
Employment type such as 正社員, 契約社員, 派遣社員, アルバイト, 業務委託, 新卒, or インターン.
Column
投稿日
Visible posting date or recency text.
Column
会社口コミランキング
Company review rating when available.
Column
PageUrl
Source page where the row was collected.
Column
Current_Time
Run timestamp formatted for Asia/Tokyo.
Use cases
Concrete workflows for research, newsrooms, SEO, and monitoring
Labor-market research
A researcher tracks a fixed set of Tokyo search URLs for software, hospitality, or sales roles. Each run creates a dated CSV, then the team compares company names, salary phrases, employment types, and posting recency.
Newsroom reporting
A reporter collects a modest list of public job pages tied to a story angle, keeps the source URL beside each row, and uses the CSV as a notebook index rather than a republished database.
SEO and content strategy
An SEO team compares job-title wording, skill phrases, city modifiers, and employer categories to understand how hiring demand is described in live listings.
Recruiting agency research
An agency exports reviewed result pages, filters by title and location, then manually reviews employers before outreach. The CSV is a triage layer, not an automatic contact engine.
For macro labor-market questions, the official Indeed Hiring Lab Japan, Hiring Lab API, and Indeed data FAQ may be a better starting point than page-level scraping. Use the scraper when the project specifically needs page-level rows from reviewed Indeed Japan URLs.
Run pattern
A controlled process for scraping Indeed Japan jobs
Define the research question
Decide whether the run supports salary review, competitor hiring analysis, newsroom evidence, SEO planning, or monitoring. The question determines which URLs belong in scope.
Prepare approved URLs
Save direct job URLs and narrow search-result URLs. Keep the original URL list beside the CSV so every exported row can be traced back to a planned input.
Run a small validation batch
Start with one direct job page and one search page. Confirm normal rows, pagination behavior, and any BLOCKED_BY_INDEED_VERIFICATION rows before expanding.
Review the CSV before analysis
Deduplicate by detail URL and source page, filter blocker rows, spot-check titles and companies, then copy the reviewed file into your analysis workbook or dashboard.
FAQ
FAQ
Use it when a researcher, newsroom, SEO team, recruiter, or monitoring team already has reviewed jp.indeed.com URLs and needs a CSV that can be audited row by row.
When the row-level workflow is the right fit, import Indeed Japan Job Scraper by URL from the UScraper templates library. For related tutorials and comparison posts, browse the UScraper blog.