This tutorial shows how to scrape iTownPage business details from supplied itp.ne.jp detail-page URLs into CSV with the iTown Page Details Scraper for UScraper.
Before you start
Prerequisites and iTownPage policy checks
You need UScraper installed as a local desktop app, a short list of approved iTownPage detail URLs, and a folder where the CSV can be saved. This is an enrichment workflow: you already have pages like https://itp.ne.jp/.../<business-id> and want one reviewable CSV row per detail page.
iTownPage is the public itp.ne.jp business and facility search service from NTT Town Page. Before automation, review the current iTownPage overview and terms of use. This article covers controlled extraction from visible detail pages; it is not guidance for bypassing access controls, collecting login-only data, ignoring robots rules, or republishing directory records without permission.
Technical access is not permission. Start with a small batch, document your source and purpose, and get legal review before outreach, resale, or redistribution.
Workflow shape
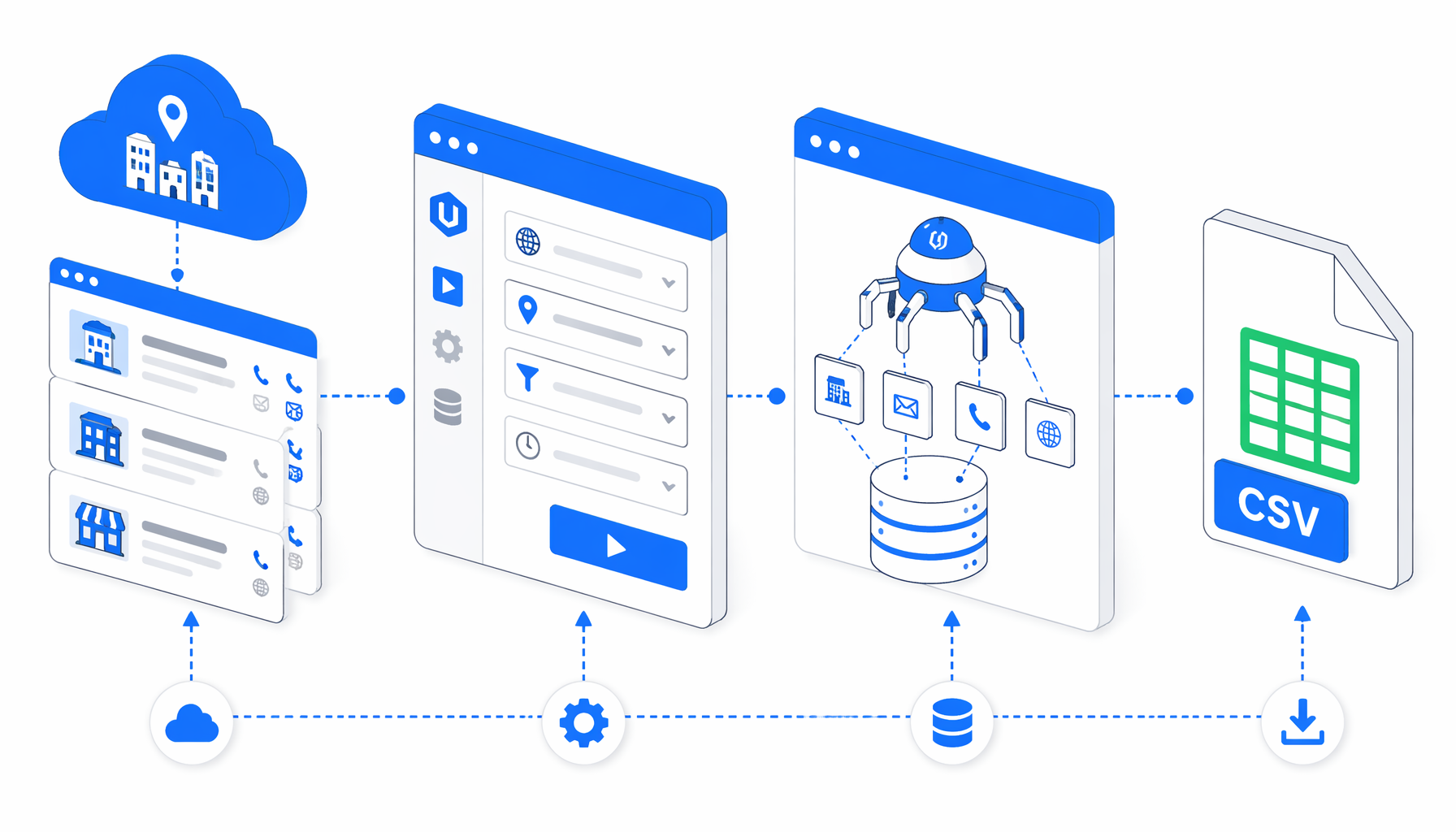
How the iTownPage scraper workflow works
The bundled JSON uses a compact detail-page loop: Set Window Size -> Navigate -> Wait for Page Load -> Sleep -> Wait for Element -> Structured Export -> Loop Continue. The Navigate block contains a multi-URL input list. Structured Export reads from body, writes headers, and uses append mode so every supplied URL lands in the same CSV.
The important detail is status logic. During live analysis, itp.ne.jp returned Access Denied for some pages, so the export columns include defensive JavaScript fallbacks. The workflow checks for blocked-page text, avoids phone-like digits from blocked URLs, and writes No_detail_page when a page is missing, blocked, or low-signal.
| Workflow part | What it controls | Practical note |
|---|---|---|
| Set Window Size | Stable browser viewport | Keep it unless you are debugging a layout-specific issue. |
| Navigate | Multi-URL iTownPage detail input | Replace sample URLs with your approved detail pages. |
| Waits and body check | Page load timing | Increase waits before assuming selectors are broken. |
| Structured Export | CSV name, save folder, append mode, columns | Confirm the folder before any client or campaign run. |
| Loop Continue | Advances through supplied URLs | Stop early if status values show repeated Access Denied pages. |
Runbook
How to scrape iTownPage detail pages to CSV
Import the template
Open iTown Page Details Scraper, download the JSON, and import it into UScraper.
Replace the sample URLs
In the Navigate block, swap the bundled itp.ne.jp URLs for your approved detail-page list. Keep the first run to 5 to 10 URLs.
Set the export folder
In Structured Export, confirm Itown-page-details-cloud-only.csv, headers, append mode, and a project-specific save location.
Run one controlled batch
Keep the browser visible. If an access challenge, blank page, or unexpected notice appears, stop the run instead of pushing more URLs through the loop.
Validate and expand
Open the CSV, filter No_detail_page, spot-check successful rows against the browser, then decide whether to run a larger list.
Output
iTownPage business details CSV columns
The JSON export is the authoritative sample for this workflow. There is no bundled CSV sample, so your first small run creates the sample you should validate. Expect one row per supplied URL, with blank contact fields when the page is blocked or does not expose that field.
Itown-page-details-cloud-only.csvColumn
会社名
Company or shop name from headings, metadata, or title fallback.
Column
メールアドレス
Email from mailto links or visible page text when present.
Column
URL
Current browser URL after navigation.
Column
電話番号
Phone from tel links or labeled text, disabled on Access Denied pages.
Column
ホームページ
External business homepage after excluding common map, social, and itp.ne.jp links.
Column
オリジナル_URL
Original or current URL retained for reconciliation.
Column
No_detail_page
Blank for likely valid pages; Access Denied or No detail page for failed rows.
| Field group | How to validate it | What to do with blanks |
|---|---|---|
| Identity | Compare 会社名 and URL against the open page. | Recheck title selectors if many valid pages have no name. |
| Contact | Compare メールアドレス, 電話番号, and ホームページ. | Treat blanks as unknown, not as proof the business has no contact route. |
| Status | Filter No_detail_page before CRM import. | Separate blocked or missing pages from usable business rows. |
Quality control
Validation and common iTownPage scraping issues
Before using the export for lead research, keep the browser beside the CSV and check the first, middle, and last row from each batch.
| Symptom | Likely cause | Fix |
|---|---|---|
Every row says Access Denied | Source returned an access-control page | Stop, reduce volume, increase waits, and review terms. |
| Company names are blank | The page layout changed or the page is not a detail page | Open the URL manually and update selectors only after confirming the page is valid. |
| Phone values look like URL digits | Blocked-page text or URL fragments were being matched | Keep the access-denied guard enabled; do not force phone extraction on blocked pages. |
| CSV contains duplicates | Append mode reused an old file or the URL list repeats | Dedupe by オリジナル_URL, then by normalized company name and phone. |
| Homepage points to a map or social site | External-link filtering needs review | Inspect the link list and adjust exclusions for the current page layout. |
Tool choice
Octoparse iTownPage alternative, Apify, Thunderbit, or Python
If you search for itownpage scraper tutorial or octoparse itownpage alternative, you will see several routes: Octoparse templates, an Apify iTown Japan Directory Scraper actor, Thunderbit's no-code template, and Python examples using Selenium or BeautifulSoup.
UScraper fits when you want a supervised local CSV workflow, visible browser QA, editable blocks, and a file saved directly from the desktop app. Cloud scrapers are stronger when scheduling or hosted infrastructure matter more than local review. Python is strongest when your team can own selectors, retries, storage, and compliance checks in code.
| Approach | Best fit | Trade-off |
|---|---|---|
| UScraper detail template | Controlled URL-list enrichment and spreadsheet review | You maintain selectors if itp.ne.jp changes. |
| Octoparse-style template | Marketplace workflow and cloud or desktop runs | Vendor limits, pricing, and custody need review. |
| Apify or hosted actor | API jobs, scheduling, and integrations | Requires platform setup and external runs. |
| Python scraper | Full code ownership and custom parsing | Higher maintenance burden. |
For adjacent workflows, browse the UScraper template library or read more tutorials on the UScraper blog.
FAQ
iTownPage scraper FAQ
iTownPage business information may be visible in a browser, but automated collection can still be limited by itp.ne.jp terms, robots controls, privacy rules, database rights, and local law. Review the current terms, avoid bypassing access controls, keep batches modest, and get legal review before outreach, resale, or republication.
Next step
Download the iTownPage business details scraper
Use this article as the runbook and the iTown Page Details Scraper as the download path. Start with a small URL list, confirm the CSV shape, then decide whether a local desktop workflow, a hosted scraper, or a custom Python pipeline is the right long-term route for your iTownPage data project.