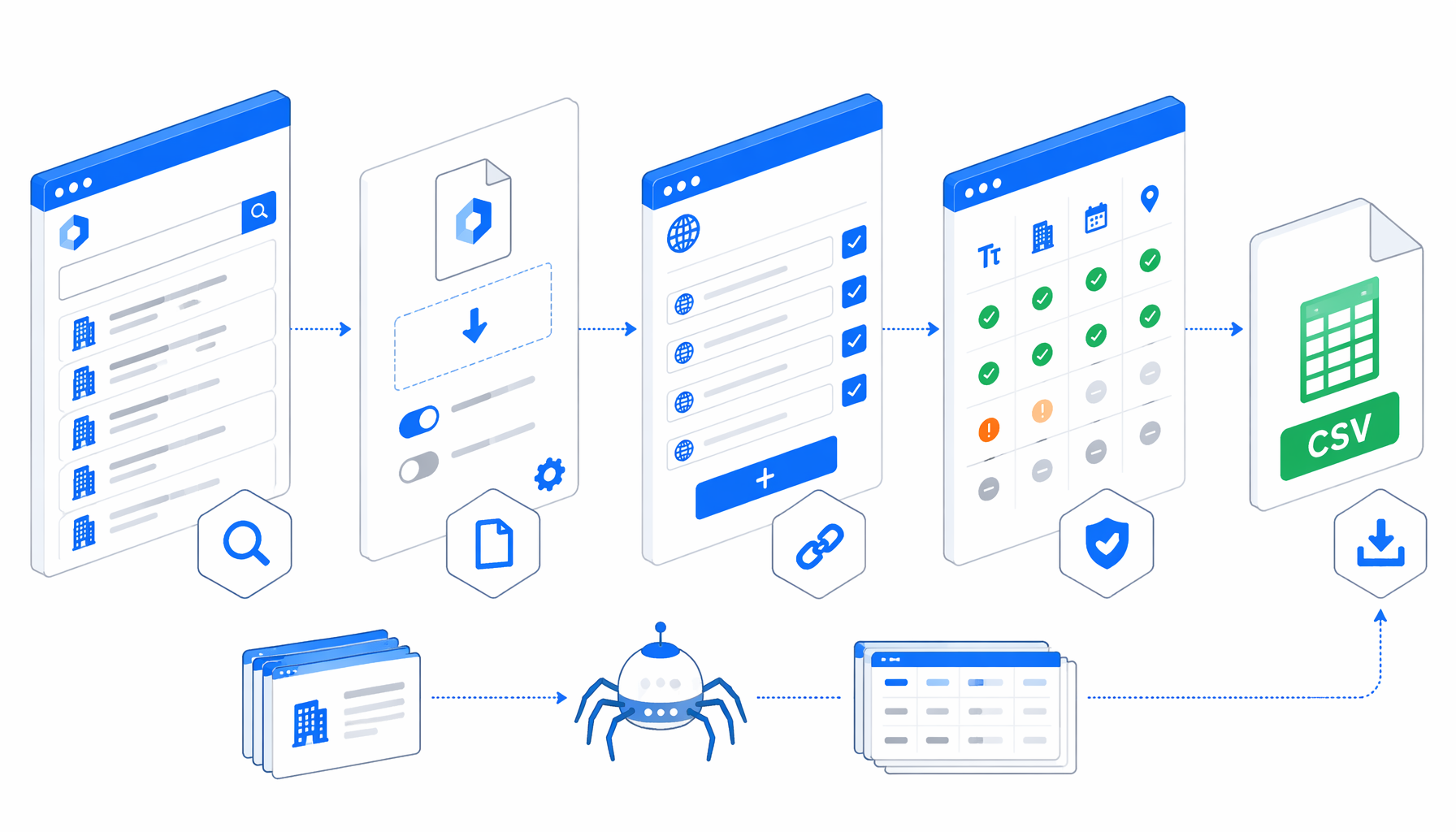
This IPROS scraper tutorial shows how to turn reviewed IPROS company pages into a local CSV using the IPROS Company Search Results Scraper template for UScraper. You will collect allowed company URLs, import the workflow, set the export path, validate rows, and handle common issues without writing a parser.
Before you start
Prerequisites for scraping IPROS company data
IPROS describes itself as a B2B search site for products, services, technical information, manufacturers, and handling companies. Start from the official IPROS company search or IPROS GMS company search, then review the company detail URLs you plan to process.
You need the UScraper local desktop app, a writable export folder, and a short list of allowed company detail URLs. Start with three to five URLs because IPROS pages can vary by language, profile completeness, access state, and layout.
Review IPROS guidance before automating, including the search help category, service help category, and current robots file for the relevant host.
Compliance first: scrape only pages you have permission to access, keep request volume modest, do not bypass technical controls, and document why each exported field is needed.
Workflow anatomy
How the IPROS company search results scraper works
The companion template follows a URL-loop flow: Set Window Size -> Navigate -> Wait for Page Load -> Sleep -> Wait for Element -> Inject JavaScript -> Structured Export -> Loop Continue. Navigate owns the URL list, wait blocks reduce half-loaded rows, Inject JavaScript normalizes labels, Structured Export writes the CSV, and Loop Continue advances.
During template testing, IPROS returned CloudFront 403 responses in the test environment. The workflow attempts live extraction first and includes fallback values for known sample URLs when blocked. Treat fallback rows as troubleshooting aids, not production data.
| Workflow part | What it controls | Why it matters |
|---|---|---|
| Navigate | The IPROS company detail URL list | This is your input batch. Replace the sample URLs before production use. |
| Wait blocks | Page load, short sleep, and visible body checks | Prevents export columns from firing against a blank or partially rendered page. |
| Inject JavaScript | Text normalization, Japanese label lookup, blocked-page detection | Keeps selectors readable and handles common company-profile labels. |
| Structured Export | Filename, save folder, append mode, and columns | Defines the authoritative CSV shape from the JSON export. |
| Loop Continue | Advances the multi-URL loop | Produces one appended row per configured company URL. |
ipros_co.csvColumn
page_url
The IPROS company detail URL opened for this row.
Column
company_name
Company name from the page heading, title, or known fallback row.
Column
established
Established or founded date when visible.
Column
capital
Capital amount shown on the company profile.
Column
employees
Employee count when IPROS provides it.
Column
postal_code
Japanese postal code parsed from visible page text.
Column
address
Company address, cleaned where possible.
Column
phone
Telephone number from labeled text or pattern matching.
Column
official_site
External official website link exposed by IPROS.
Column
last_updated
Last updated date when shown.
Column
logo_url
Company logo image URL.
Column
company_overview
Profile, PR, or meta description text.
Column
business_description
Business description or operations field.
Column
products_services
Visible product and service snippets.
Column
products_services_list_url
IPROS product or category list URL.
Column
catalog_list_url
IPROS catalog list URL for the company.
The JSON export is the source of truth: this article explains intent, while the workflow carries block IDs, selectors, file mode, and fallback logic.
{
"project": {
"name": "IPROS Company Search Results Scraper"
},
"blocks": [
{ "title": "Navigate", "config": { "urls": ["https://mono.ipros.com/company/detail/2030518/"] } },
{ "title": "Wait for Page Load", "config": { "timeout": 30 } },
{ "title": "Inject JavaScript", "config": { "waitForCompletion": true } },
{
"title": "Structured Export",
"config": {
"fileName": "ipros_co.csv",
"includeHeaders": true,
"fileMode": "append",
"columns": ["page_url", "company_name", "address", "phone", "official_site"]
}
}
]
}
Runbook
How to scrape IPROS company data to CSV
Collect approved company URLs
Search IPROS or IPROS GMS, open relevant profiles, and keep only detail URLs you are allowed to process.
Import the template
Open the IPROS company scraper template, download the JSON, and import it into UScraper.
Replace sample URLs
Open Navigate and replace sample URLs with your reviewed IPROS company detail pages. Keep the first batch small.
Confirm the export folder
In Structured Export, set the save location for ipros_co.csv. Leave headers and append mode enabled for repeatable batches.
Run one page first
Run a single URL, open the CSV, and compare the row against the browser page before enabling the full loop.
Run the batch and audit
Run the remaining URLs, dedupe by page_url, inspect blanks, and save the source URL list beside the export.
After the first batch, sort by page_url. One unique company URL should produce one row. Duplicates usually mean the URL appeared twice or append mode reused an old file.
Validation
Validate IPROS scraping results before scaling
Treat validation as part of the workflow. IPROS profiles can include missing fields, redirected official-site links, translated snippets, or blocked responses that look normal at first.
| Symptom | Likely cause | Fix |
|---|---|---|
Empty company_name | Page did not load, heading moved, or IPROS returned an access page | Inspect the browser, extend waits, and rerun one URL. |
| Address or phone is blank | Field is missing or the label changed | Check manually and update lookup only for visible fields. |
| Official site is an IPROS redirect | IPROS uses an external-link handoff before the destination site | Keep the redirect URL for traceability or resolve it in a separate enrichment step. |
| Rows append to an old file | Append mode reused a previous CSV | Clear the file, rename the export, or use a dated project folder. |
| Product snippets look incomplete | The company profile has long product lists or lazy-loaded sections | Treat the summary as a lead-research cue, then use product or catalog pages for deeper extraction. |
Alternatives
IPROS Octoparse alternative and code options
If you searched for an IPROS Octoparse alternative, compare the run model first. Octoparse publishes separate IPROS templates for company and product search results. Code-first teams can build with Scrapy or Playwright, but they own selectors, throttling, storage, and maintenance.
| Option | Best fit | Trade-off |
|---|---|---|
| UScraper local desktop app | Supervised IPROS exports, local CSV custody, editable no-code blocks | You manage pacing, validation, and selector checks. |
| Octoparse IPROS template | Hosted no-code scraping with a familiar template marketplace | Less emphasis on local file custody and direct workflow ownership. |
| Scrapy or Playwright | Engineering-owned crawlers, tests, pipelines, and integrations | Requires code, deployment, monitoring, and maintenance. |
Broad searches such as "IPROS scraping tools" still need a concrete plan: gather approved detail URLs, run a small local export, validate the CSV, then scale carefully.
FAQ
IPROS scraper FAQ
Public visibility does not automatically make automation unrestricted. Review IPROS terms, robots guidance, copyright, database rights, privacy rules, and local regulations. Use approved URLs, keep volume modest, and get legal review before commercial reuse.
Next step
Download the IPROS company scraper template
When ready, download the JSON from IPROS Company Search Results Scraper and keep this tutorial open for QA. For adjacent workflows, browse all UScraper templates or use the UScraper blog for more local CSV export tutorials.