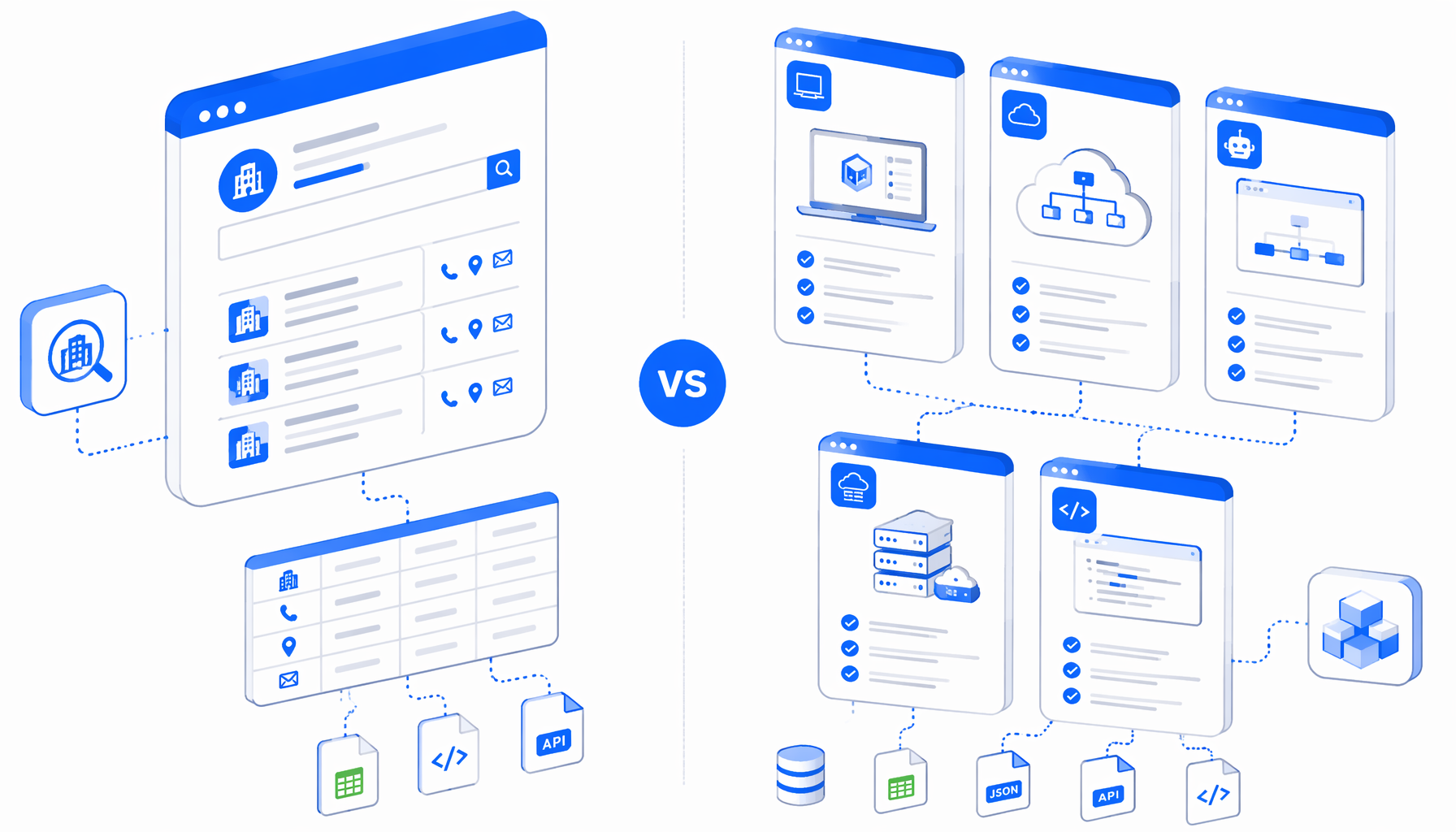
The best IPROS company scraper depends on where the browser runs, who maintains selectors, how pricing is metered, and whether the deliverable is a clean CSV or an API pipeline. This guide compares Octoparse, Apify, SaaS scrapers, browser extensions, scripts, and UScraper's IPROS Company Search Results Scraper.
Comparison frame
What an IPROS company scraper has to solve
IPROS company pages combine supplier identity, contact details, product context, catalog links, and business descriptions in one research surface. A useful IPROS company search scraper needs to preserve source URL, company name, address, phone number, official site, profile text, product/service snippets, and related category or catalog URLs in a format your team can verify.
Searches such as scrape IPROS company data, how to scrape IPROS, and Octoparse IPROS alternative usually split into four paths: no-code SaaS templates, actor marketplaces, general scraping tools, and code frameworks such as Crawlee or Scrapy.
The practical question is not "which tool can scrape IPROS?" It is "which workflow gives your team rows it can inspect, maintain, and afford to repeat?"
Side-by-side
IPROS scraper alternatives compared
| Option | Best fit | Hosting | Code needed | Output shape | Pricing model to check | Honest trade-off |
|---|---|---|---|---|---|---|
| UScraper + IPROS company template | Approved company detail URLs to CSV | Local desktop app | Low | CSV: 16 company fields | Template is free; app licensing applies | Strong local custody and visible workflow blocks |
| Octoparse IPROS Company template | Hosted no-code scraping and SaaS task management | Vendor cloud | Low | CSV, Excel, database-style exports | Subscription plan, task limits, cloud runs, add-ons | Convenient template path, but hosted data custody |
| Apify Store actors | Recurring jobs, datasets, APIs, custom actors | Apify cloud | Low to high | Dataset, JSON, CSV, API | Platform usage, actor rental, compute, storage | Strong infrastructure, but actor quality and pricing vary |
| ParseHub-style visual scraper | Generic point-and-click extraction | Vendor desktop/cloud mix | Low | CSV, JSON | Project limits, pages per run, speed, scheduling | Flexible, but IPROS maintenance remains yours |
| Web Scraper browser extension | Lightweight operator-led extraction | Browser plus optional cloud | Low | CSV, XLSX, JSON | Extension/cloud plan, scheduling, data limits | Fast for small jobs, weaker for governed workflows |
| Zapier plus scraping apps | Routing extracted data into Sheets, CRM, or alerts | Automation cloud | Low | App-triggered records | Zapier plan plus scraper app costs | Useful after extraction, not ideal for selector debugging |
| Crawlee or Scrapy scripts | Engineering-owned crawling and deployment | Your infrastructure | High | Whatever you build | Developer time, proxies, servers, maintenance | Maximum control, maximum upkeep |
This is not a universal ranking. A data platform team may prefer actors or scripts because APIs are the product. A sourcing analyst may prefer UScraper because they need a local CSV and a visual graph they can adjust.
UScraper fit
When UScraper is the better Octoparse IPROS alternative
UScraper is strongest when the workflow is local, visual, and CSV-first. The companion IPROS Company Search Results Scraper template opens configured company detail URLs, waits for the page, injects helper JavaScript, and appends one row per company page to ipros_co.csv.
The workflow exports page_url, company_name, established, capital, employees, postal_code, address, phone, official_site, last_updated, logo_url, company_overview, business_description, products_services, products_services_list_url, and catalog_list_url. Those fields give supplier researchers more audit context than a name-and-website list.
UScraper wins when exported rows should stay in a chosen local folder before spreadsheet, enrichment, or CRM prep.
Cloud tools win when jobs need remote scheduling, managed retries, shared dashboards, and remote storage.
It depends. Apify fits developer automation and datasets; Octoparse fits hosted visual scraping; UScraper fits local visual scraping and editable export columns.
Scripts win when engineers need parser tests, queues, custom storage, observability, and deployment rules.
Where competitors win
When Octoparse, Apify, ParseHub, or scripts make more sense
Choose Octoparse when hosted no-code task management is already approved. Choose Apify when the job belongs in a cloud automation stack with actors, datasets, APIs, and run history. Choose ParseHub, Web Scraper, or AI scraping tools for exploratory page-specific work. Choose Crawlee, Scrapy, or custom scripts when scraping is part of a product or internal data platform and engineers can own every breakage.
Use UScraper for spreadsheet-ready CSV. Use Apify or scripts when downstream systems need JSON, APIs, webhooks, queues, or database writes.
Compliance
Do not skip IPROS policy and access checks
Public visibility is not the same as permission for automated collection. Before you scrape IPROS company data, review current IPROS terms, robots rules, copyright or database rights, privacy obligations, and local law. Avoid restricted areas, login-only content, CAPTCHA bypasses, CloudFront blocks, aggressive pacing, and redistribution of data you are not allowed to use.
For lead research, keep the scope narrow: collect only needed fields, retain the source URL, verify a small batch manually, and stop if the workflow shows blocked pages.
FAQ
Use UScraper for local CSV, Octoparse for hosted no-code scraping, and Apify or scripts when cloud execution, APIs, and engineering control matter more.
Next step
Start with the local CSV workflow
If your requirement is an inspectable IPROS company search results scraper rather than a developer-run crawling platform, start with the free IPROS Company Search Results Scraper template. Run a small allowed batch, compare the CSV against the browser, and only then expand the URL list. For other marketplaces and search workflows, browse the UScraper template library or read more comparison articles in the UScraper blog.