This InfoJobs scraper tutorial shows how to turn approved InfoJobs Spain job detail URLs into a structured CSV with the InfoJobs Details Scraper template for UScraper. You will import the workflow, replace the sample URLs, choose the export path, run a small batch, and validate the result before scaling.
Before you start
Prerequisites, scope, and policy checks
You need UScraper installed as a local desktop app, a short list of InfoJobs offer detail URLs, and a folder where the CSV can be written. Start with two to five URLs, not a full market crawl. The goal is to prove that your row shape is correct before you collect more job data.
This tutorial covers public job detail pages that your team is allowed to review. It does not cover account pages, employer dashboards, private candidate data, applications, login flows, or CAPTCHA bypassing. Before running recurring exports, review the InfoJobs site policies, the current InfoJobs robots.txt, and your own legal basis for collecting job data.
A scraper is a collection method, not a permission model. Keep the batch deliberate, document why the data is being collected, and stop when the site asks for verification.
Workflow anatomy
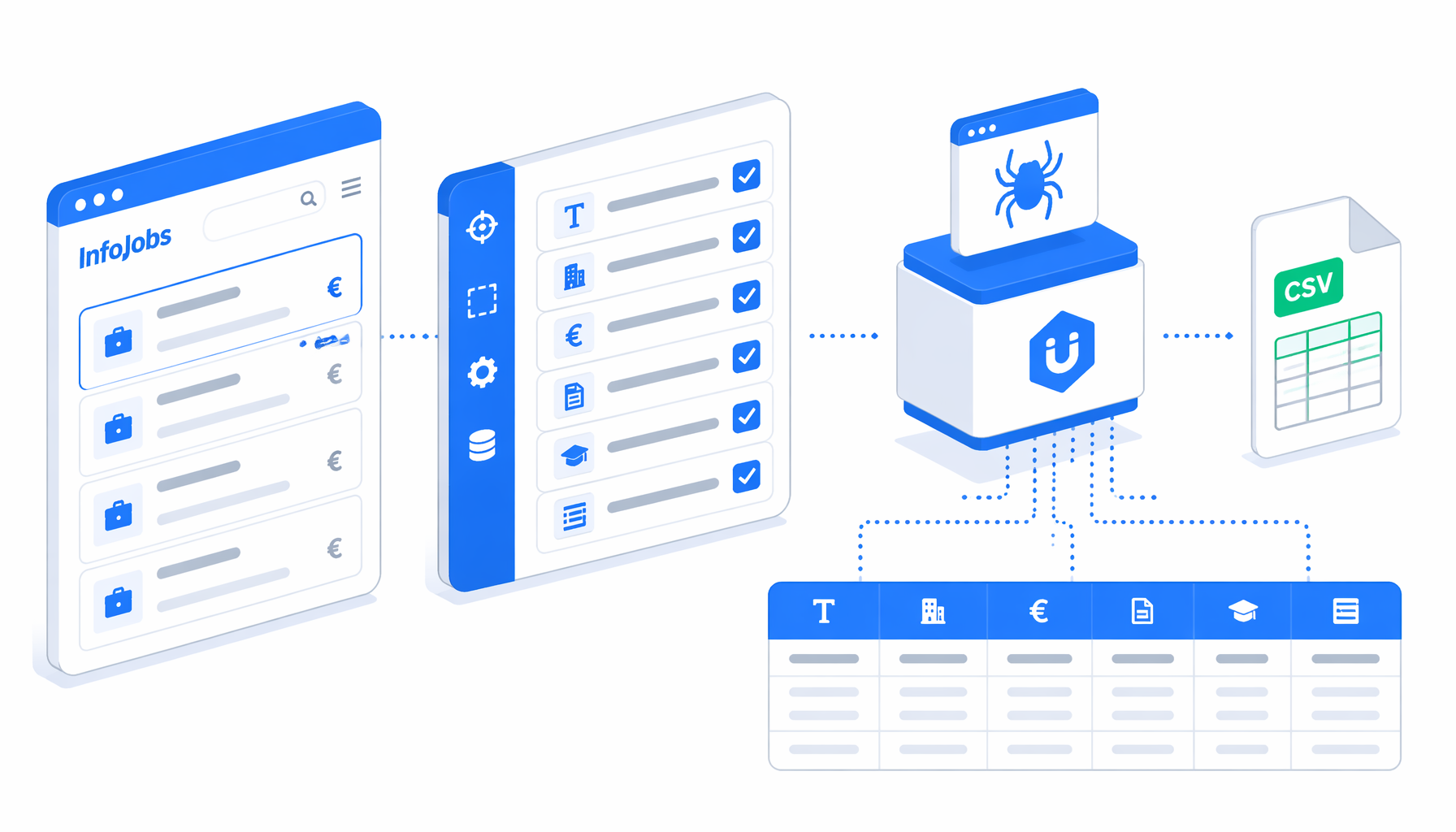
How the InfoJobs job details scraper works
The workflow is intentionally direct: Set Window Size -> Navigate -> Wait for Page Load -> Element Exists -> Sleep -> Structured Export -> Loop Continue. The Navigate block owns the input list. The condition block checks for robot/CAPTCHA selectors and a confirmed heading. Both branches continue to the same Structured Export block, so every URL produces an auditable row.
The JSON export is the authoritative workflow definition. It uses append mode, includes headers, writes infojobs_detalles_scraper.csv, and extracts from JobPosting JSON-LD where possible before falling back to visible page text or safe URL-derived values.
| Workflow block | What it does | Validation point |
|---|---|---|
| Set Window Size | Opens the browser viewport at 1920 by 1080 | Keeps selectors and visible sections consistent. |
| Navigate | Opens each InfoJobs detail URL in the provided list | One input URL should map to one CSV row. |
| Element Exists | Checks robot widgets and heading selectors | Explains why a row is normal or fallback-only. |
| Structured Export | Writes 17 named columns in append mode | Confirm headers and save folder before batching. |
| Loop Continue | Advances through the multi-URL list | Prevents manual copy-paste between pages. |
API or scraper
InfoJobs API vs scraper: when each path fits
InfoJobs publishes developer documentation for API access, including a public offer list endpoint at GET /offer and an offer detail endpoint at GET /offer/{offerId}. The developer quick start also describes registering an application and using credentials for API access. If your use case is an approved app, stable integration, or repeated product workflow, start with the InfoJobs developer documentation.
A scraper fits a different job: supervised research from a small, known set of browser-visible detail pages. It is useful when an analyst already has the URLs, wants a CSV snapshot, and needs to inspect the rendered page state while extracting. It is not the right path for bypassing access controls or replacing an approved API integration.
| Need | Better fit | Why |
|---|---|---|
| Approved application integration | InfoJobs API | Documented endpoints, credentials, and response contracts. |
| One-off spreadsheet from known URLs | UScraper template | Browser-visible QA, local CSV output, no custom code. |
| Hosted scheduling and infrastructure | Cloud scraper provider | Useful when custody and usage-based pricing are acceptable. |
| Commercial redistribution | Legal/API review first | Rights and data reuse matter more than extraction mechanics. |
Runbook
How to scrape InfoJobs job details to CSV
Import the template
Open the InfoJobs job details scraper, download the JSON workflow, and import it into UScraper.
Replace the sample URLs
In Navigate, replace the two bundled InfoJobs URLs with approved job detail pages. Keep a copy of the source URL list beside the export for auditability.
Keep the verification branch
Leave the Element Exists check in place. It looks for CAPTCHA or robot-check signals and prevents blocked pages from being mistaken for normal extraction failures.
Set the CSV destination
In Structured Export, confirm infojobs_detalles_scraper.csv, headers, append mode, and a project-specific save folder.
Run one page, then batch
Run one URL, compare the CSV against the browser, then continue with the rest of the list only after the fields match your expectations.
Output
What the InfoJobs CSV includes
The export shape is Spanish because it mirrors the workflow columns: empleo, empresa, ubicacion, modalidad, salario, and related detail fields. That makes the file easy to map back to the original InfoJobs page while still being spreadsheet-friendly.
infojobs_detalles_scraper.csvColumn
extraction_status
ok, captcha_or_robot_check_detected, or loaded_but_job_selectors_not_confirmed.
Column
empleo
Job title from JobPosting data, page heading, or URL-derived fallback.
Column
empleo_url
Full source URL opened by the browser.
Column
empresa
Hiring organization name when available.
Column
ubicacion
Location from structured data, visible text, or fallback city path.
Column
salario
Salary text or structured salary range when exposed.
Column
tipo_de_contrato
Contract or employment type.
Column
descripcion
Cleaned job description text.
Sample rows
2 of many
| extraction_status | empleo | empleo_url | empresa | ubicacion | salario | tipo_de_contrato | descripcion |
|---|---|---|---|---|---|---|---|
| ok | Mozo conductor lavador vehiculos | ... | Empresa de movilidad | Malaga, Andalucia, ES | 18.000 - 21.000 EUR | Contrato indefinido | Funciones principales del puesto... |
| captcha_or_robot_check_detected | LAVADOR CONDUCTOR VEHICULOS MADRID | ... | Madrid |
After exporting, sort by empleo_url and check for duplicates. Then filter extraction_status. Rows marked ok can move into analysis. Rows marked captcha_or_robot_check_detected should be reviewed manually or excluded from the dataset.
Troubleshooting
Common issues and fixes
| Symptom | Likely cause | Fix |
|---|---|---|
| Empty company or salary | InfoJobs did not expose that field on the page | Keep the row, but do not treat optional fields as required. |
| Only fallback title and city | Robot check or incomplete page load | Review the browser tab, slow the run, and retry a single URL. |
| Duplicate rows | Same URL was run twice in append mode | Start a fresh CSV before the final batch. |
| Description text looks truncated | Page module changed or loaded late | Add a longer wait or update the Structured Export selector. |
| API and scraper values differ | API schema and rendered page do not expose identical fields | Pick one source of truth per report and document it. |
FAQ
InfoJobs scraping FAQ
InfoJobs job pages can contain public job information, but automated access may still be restricted by platform terms, robots rules, copyright, database rights, privacy law, and employment-data rules. Review the current policies, keep volume modest, avoid bypassing access controls, and get legal advice before commercial reuse.
Next step
Download the workflow and run a smoke test
Use the InfoJobs Details Scraper template as the maintained download path, then run the bundled URLs once before replacing them. For more no-code extraction workflows, browse the UScraper template library or review related tutorials in the UScraper blog.