This Immobiliare scraper tutorial shows how to scrape Immobiliare property detail pages into CSV with the Immobiliare Real Estate Detail Scraper template for UScraper. You will import the workflow, replace sample URLs, set the export path, validate the fields, and understand when an official API, Python scraper, or hosted cloud tool is a better fit.
Before you start
Prerequisites for an Immobiliare property detail scraper
You need UScraper installed as a local desktop app, the Immobiliare Real Estate Detail Scraper template, and a short list of Immobiliare.it property detail URLs you are allowed to process. The workflow is built for URLs like https://www.immobiliare.it/annunci/106718379/, not broad keyword crawling or map exploration.
Start with three to five listings from one city or agency. A small batch exposes consent prompts, unavailable listings, DataDome device checks, CAPTCHA pages, and selector drift before those issues contaminate a larger CSV.
Review Immobiliare's current terms, robots.txt, and official Immobiliare.it Insights API route before automation.
Technical access is not permission. Keep runs modest, collect only fields you need, stop when an access challenge appears, and use approved API or partner routes when you need stable rights to redistribute data.
Workflow shape
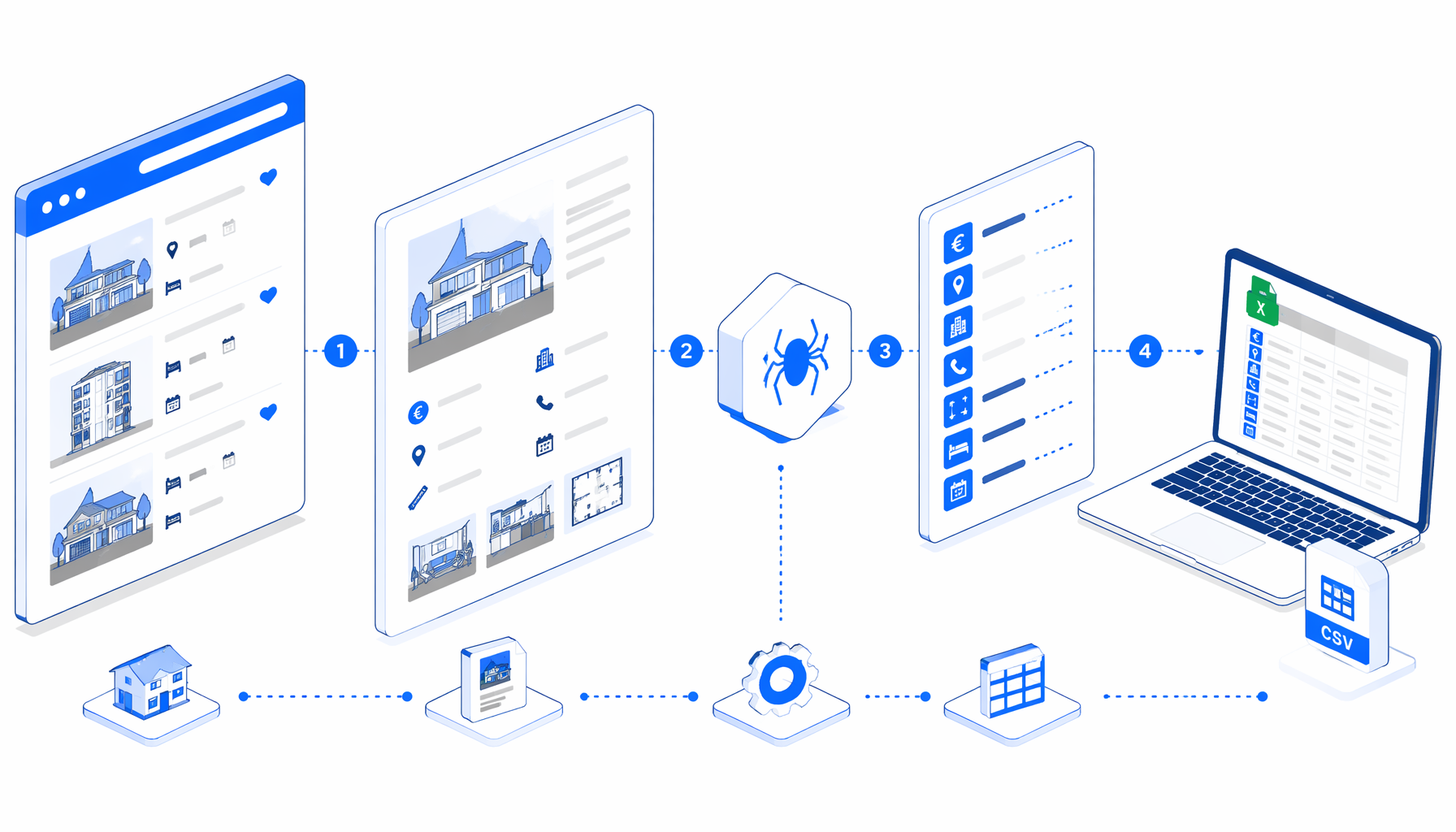
How the Immobiliare detail workflow works
The JSON export is the authoritative workflow definition. In plain English, the flow is:
Navigate -> Wait for Page Load -> Sleep -> Wait for body
-> Inject JavaScript -> Sleep -> Structured Export -> Loop Continue
Navigate stores the Immobiliare detail-page URL list. The wait blocks give the page time to render. Inject JavaScript clicks visible controls whose labels look like mostra, leggi, espandi, or continua, so longer descriptions have a better chance of being present before export. Structured Export reads from body, writes headers, and appends rows. Loop Continue advances to the next URL.
| Workflow block | Purpose | Validation check |
|---|---|---|
| Navigate | Holds the supplied Immobiliare detail URLs | Replace every bundled sample URL with approved inputs. |
| Waits | Gives page load and dynamic content time to settle | Stop on CAPTCHA, error, or blocked pages. |
| Inject JavaScript | Expands visible description-style controls | Confirm long descriptions are visible before export. |
| Structured Export | Appends the configured columns to CSV | Check filename, folder, headers, and append mode. |
| Loop Continue | Moves to the next URL in the list | One processed URL should create one property row. |
Runbook
How to scrape Immobiliare property details to CSV
Import the template
Open Immobiliare Real Estate Detail Scraper, download the workflow JSON, and import it into UScraper.
Replace the URL list
Open Navigate and replace the five sample /annunci/ links with the Immobiliare detail pages your team is allowed to process.
Confirm page access
Open one target URL in the same browser profile. Continue only when the real property page renders, not a CAPTCHA, consent wall, login wall, 403 page, or device-check page.
Set the export folder
In Structured Export, confirm crawler-dettagli-immobili-immobiliare.csv, headers, append mode, and a project-specific local save folder.
Run a validation batch
Run three to five URLs, then compare title, price, location, agency, phone, description, surface, rooms, floor, and availability against the browser.
Scale only after QA
Extend the URL list after access prompts, blank fields, duplicates, and selector changes are understood.
Append mode is useful for URL loops, but it also preserves test rows. Use a dated folder or clear the CSV before rerunning the same URL list.
Output
CSV output fields from Immobiliare detail pages
There is no bundled CSV sample for this template, so use the export shape and JSON workflow together. The JSON defines the columns and selectors; your first validation run proves the fields still match the current page layout.
crawler-dettagli-immobili-immobiliare.csvColumn
url_inserito
Processed Immobiliare detail URL.
Column
titolo_appartamento
Page H1, Open Graph title, or document title.
Column
prezzo
Visible price text or euro amount found in the page body.
Column
posizione
Address or location text from the listing header.
Column
agenzia
Advertiser or agency name.
Column
telefono_agenzia
Phone link or visible Italian phone pattern.
Column
agenzia_url
Agency profile URL when the page exposes one.
Column
contenuto_descrizione
Expanded description text or meta-description fallback.
Column
riferimento_e_data_annuncio
Reference and listing date text.
Column
superficie
Surface area field.
Column
locali
Room count or local field.
Column
piano
Floor information.
The full configured column set also includes titolo_descrizione, totale_piani_edificio, and disponibilita. Treat agency phone, agency URL, floor, total floors, and availability as optional because not every listing exposes those fields in the same way.
{
"fileName": "crawler-dettagli-immobili-immobiliare.csv",
"rowSelector": "body",
"fileMode": "append",
"columns": [
"url_inserito",
"titolo_appartamento",
"prezzo",
"posizione",
"agenzia",
"telefono_agenzia",
"agenzia_url",
"titolo_descrizione",
"contenuto_descrizione",
"riferimento_e_data_annuncio",
"superficie",
"locali",
"piano",
"totale_piani_edificio",
"disponibilita"
]
}
Tool choice
Immobiliare API alternative, Python scraper, or no-code template?
Searches for immobiliare api alternative, immobiliare python scraper, and best Immobiliare scraper mix different jobs. Choose based on permission, output format, maintenance ownership, and where the data is processed.
Use UScraper for selected Immobiliare detail URLs, local CSV output, analyst QA, and editable no-code blocks.
For this tutorial, the wedge is controlled detail-page CSV export: a researcher can watch the browser, inspect selectors, and keep the result in a local folder.
Troubleshooting
Common issues when scraping Immobiliare property pages
| Symptom | Likely cause | Fix |
|---|---|---|
| CSV has blank rows | The real listing page did not render, or access was blocked | Stop the batch and validate one accessible URL. |
| Price or title is missing | Immobiliare changed markup or served a partial page | Inspect the page and update the export selector. |
| Description is short | The expand button did not appear or did not click | Increase the wait, inspect the visible controls, and rerun one URL. |
| Agency phone is blank | The phone is hidden, gated, or absent for that listing | Treat it as optional and avoid account-only data. |
| Duplicate rows | Append mode kept rerun data or duplicate URLs were supplied | Dedupe by url_inserito and clear test rows before reruns. |
FAQ
Immobiliare scraper FAQ
Immobiliare detail pages may be visible in a browser, but automated collection can still be limited by platform terms, robots directives, agency rights, copyright, database rights, privacy rules, and local law. Review the current rules, keep runs modest, avoid bypassing access controls, and get legal review before commercial reuse.
Next step
Download the Immobiliare real estate detail scraper
Use Immobiliare Real Estate Detail Scraper as the download path, then keep this tutorial open during the first CSV validation pass. If you need source URLs first, start with the Immobiliare real estate listing scraper, then browse all UScraper templates or return to the UScraper blog for adjacent real estate workflows.