This Immobiliare scraper tutorial shows how to scrape Immobiliare detail listings into CSV with UScraper. You will import the Immobiliare listing scraper template, replace sample detail URLs, set the export path, validate rows, and decide when an official API or hosted provider is a better fit.
Before you start
Prerequisites for Immobiliare data extraction
You need UScraper installed as a local desktop app, a folder for exports, and Immobiliare.it detail URLs that you are allowed to review. This template is built for detail pages, not bulk search-page discovery. If your goal is "how to get property listings" from a city search page, first collect or approve the detail URLs, then normalize those pages into CSV.
The maintained download path is the Immobiliare listing scraper template. Keep this article open as the runbook, then browse the UScraper template library for related real estate and marketplace workflows.
Before running automation, review Immobiliare's current terms, robots.txt, and official Immobiliare Insights API route.
Keep runs modest, do not bypass CAPTCHA or access controls, avoid account-only data, and get legal review before using scraped real estate data for commercial resale, automated outreach, or model training.
Workflow shape
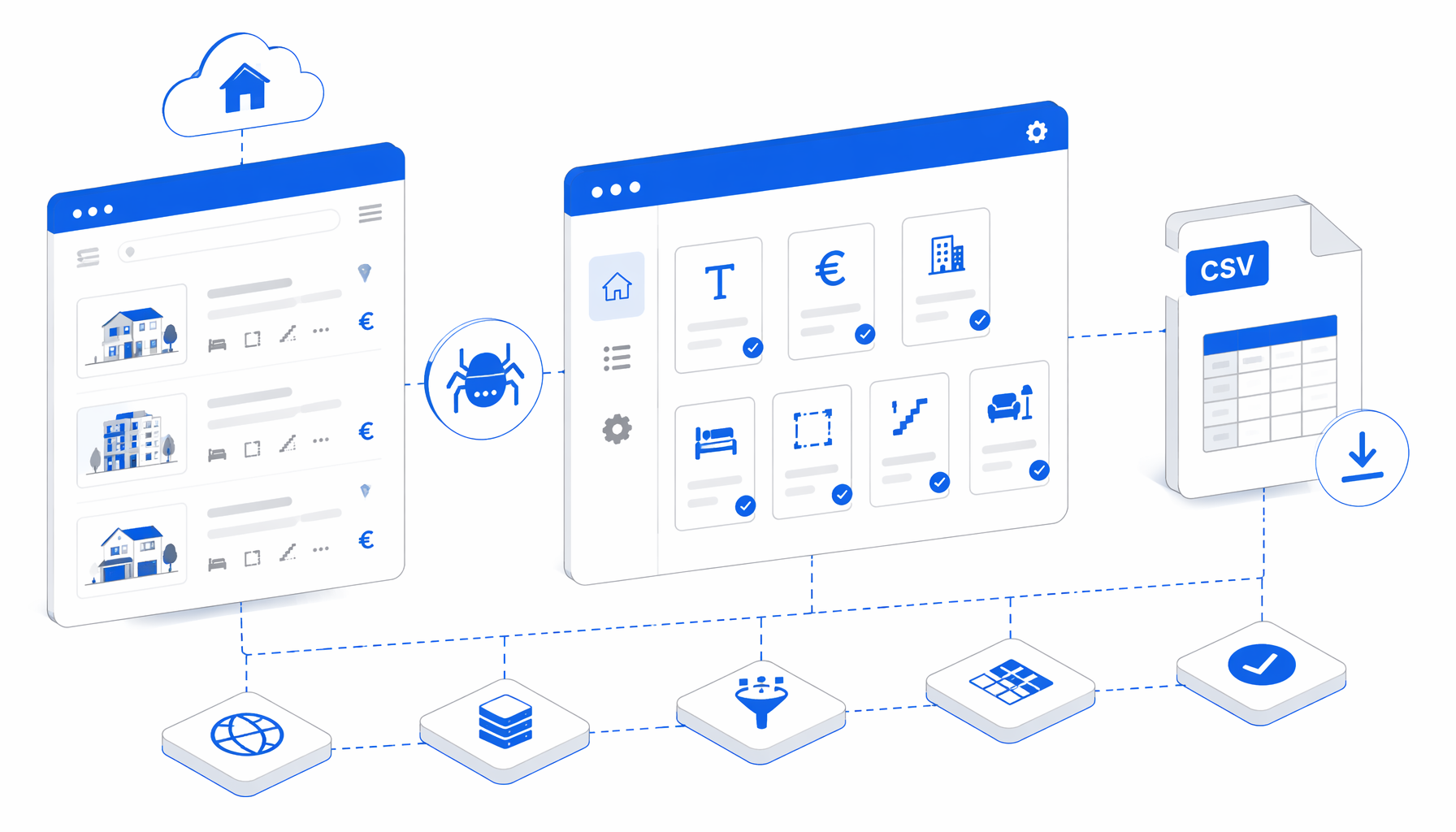
How the Immobiliare listing scraper works
The JSON export is the authoritative workflow definition. The bundle opens three sample Immobiliare detail URLs, waits up to 45 seconds, sleeps for two seconds, injects JavaScript, and then writes one structured row from window.__USCRAPER_IMMOBILIARE_DATA.
The important design choice is scope. Autonomous checks against Immobiliare search and listing pages did not return an accessible listing DOM because anti-bot blocking produced empty or blocked pages. For that reason, this template uses a multi-URL detail-page loop. The three bundled sample URLs can fall back to preview values; your own URLs should be validated live.
CSV
15
Detail URLs
1 row
Local
| Workflow block | Purpose | What to verify |
|---|---|---|
| Navigate | Opens each Immobiliare detail URL in the multi-input loop | Replace the three samples with approved listing URLs. |
| Wait and sleep | Gives the page and browser checks time to settle | Continue only when a real listing page is visible. |
| Inject JavaScript | Reads DOM, meta tags, JSON-LD, and feature text into one object | Check for blocked-page detection and fallback behavior. |
| Structured Export | Appends the selected columns to scraper-immobiliare.csv | Confirm headers, append mode, filename, and save folder. |
| Loop Continue | Advances to the next input URL | Watch for repeated URLs or old rows after reruns. |
Runbook
How to scrape Immobiliare listings to CSV
Import the template
Open the Immobiliare listing scraper template, download the JSON, and import it into UScraper.
Replace sample URLs
In the Navigate block, replace the three bundled detail URLs with Immobiliare.it listing URLs from your approved research set.
Run one detail page
Start with one URL. Keep the browser visible and confirm that title, price, agency, rooms, and surface appear.
Confirm the export path
In Structured Export, keep scraper-immobiliare.csv or rename it for the project. Confirm headers, append mode, and the local folder.
Validate the first row
Compare the CSV with the page for titolo, prezzo, agenzia, locale, superficie, and amenity flags.
Scale cautiously
Add more URLs only after the first row passes QA. Stop when the browser shows a challenge, blank page, login wall, or unexpected content.
Because file mode is append, reruns add rows to the same CSV. For clean QA, create a dated export folder or clear the test CSV before repeating a URL list.
Output
CSV fields from Immobiliare detail pages
There is no bundled CSV sample, so read the export summary and JSON definition together. The summary explains intent; the imported JSON defines blocks, selectors, JavaScript expressions, filename, and loop.
| CSV field | What it captures | Validation check |
|---|---|---|
tipo_immobili, posizione | Property category and location text | Confirm the location is not a generic page label. |
titolo, URL_immobili | Listing title and canonical detail URL | Open the URL and match it to the title. |
prezzo, descrizione, agenzia | Price, description, and agency or advertiser text | Expect blanks when the page hides or delays a field. |
locale, superficie, bagno, piano | Rooms, surface, bathrooms, and floor | Compare against the feature chips on the listing page. |
ascensore, balcone, terrazza, cantina | Amenity flags inferred from visible text | Treat these as page-visible signals, not verified property facts. |
{
"project": {
"name": "Immobiliare Listing Scraper Cloud Only",
"description": "Extracts Immobiliare detail fields from provided listing URLs."
},
"blocks": [
{ "title": "Navigate", "config": { "urls": ["https://www.immobiliare.it/annunci/121222336/"] } },
{ "title": "Wait for Page Load", "config": { "timeout": 45 } },
{ "title": "Inject JavaScript", "config": { "waitForCompletion": true, "timeout": 10 } },
{
"title": "Structured Export",
"config": {
"fileName": "scraper-immobiliare.csv",
"includeHeaders": true,
"fileMode": "append",
"columns": ["tipo_immobili", "posizione", "titolo", "URL_immobili", "prezzo", "agenzia", "locale", "superficie", "bagno", "piano", "ascensore", "balcone", "terrazza", "cantina"]
}
}
]
}
Troubleshooting
Common issues in an Immobiliare scraper tutorial
Stop the run. The workflow is not meant to bypass access controls. Reduce scope, review permission, and use official or licensed routes for production access.
Alternatives
Octoparse Immobiliare alternative, Python scraper, or API?
Searches for octoparse immobiliare alternative, immobiliare python scraper, and scrape immobiliare listings usually point to these models.
| Approach | Best for | Trade-off |
|---|---|---|
| UScraper template | Supervised CSV exports, editable blocks, local custody, analyst QA | You still maintain selectors and source-policy checks. |
| Hosted scraper or cloud actor | Scheduling, managed retries, team dashboards, larger batches | Usually subscription based and routes data through a third party. |
| Python or Selenium scraper | Developer-owned parsing and custom enrichment | Requires code maintenance, browser debugging, and anti-bot handling decisions. |
| Official or licensed data route | Contracted access, stable integration, production reuse | Access, fields, pricing, and reuse terms depend on the provider. |
For a small research export, start with the Immobiliare listing scraper template. For broader real estate scraping patterns, use the UScraper blog to compare workflows and the template library to find sibling scrapers.
FAQ
FAQ
Is it legal to scrape Immobiliare.it listings?
Immobiliare.it listings may be visible in a browser, but automated collection can still be restricted by terms, robots directives, access controls, database rights, privacy law, and local real estate rules. Do not bypass challenges, login walls, or technical restrictions, and get legal review before commercial reuse.
Does this tutorial use the Immobiliare API?
No. This tutorial uses rendered Immobiliare.it detail pages and a local CSV export. Evaluate the official API or licensed data routes when you need approved programmatic access, contractual rights, stable schemas, or production integration.
What does the Immobiliare listing scraper export?
The workflow writes scraper-immobiliare.csv with tipo_immobili, posizione, titolo, URL_immobili, prezzo, descrizione, agenzia, locale, superficie, bagno, piano, ascensore, balcone, terrazza, and cantina.
Why did the CSV contain fallback values?
The bundle includes fallback values for three sample URLs because autonomous tests against Immobiliare search and listing pages returned blocked or empty listing DOM. Replace the sample URLs with your own approved detail pages, run one URL, and validate live fields before scaling.
Is UScraper an Octoparse Immobiliare alternative?
UScraper can be an Octoparse Immobiliare alternative when you want an editable local desktop app workflow and CSV custody. Hosted cloud scrapers may be better for scheduling, vendor-managed retries, and large batches.