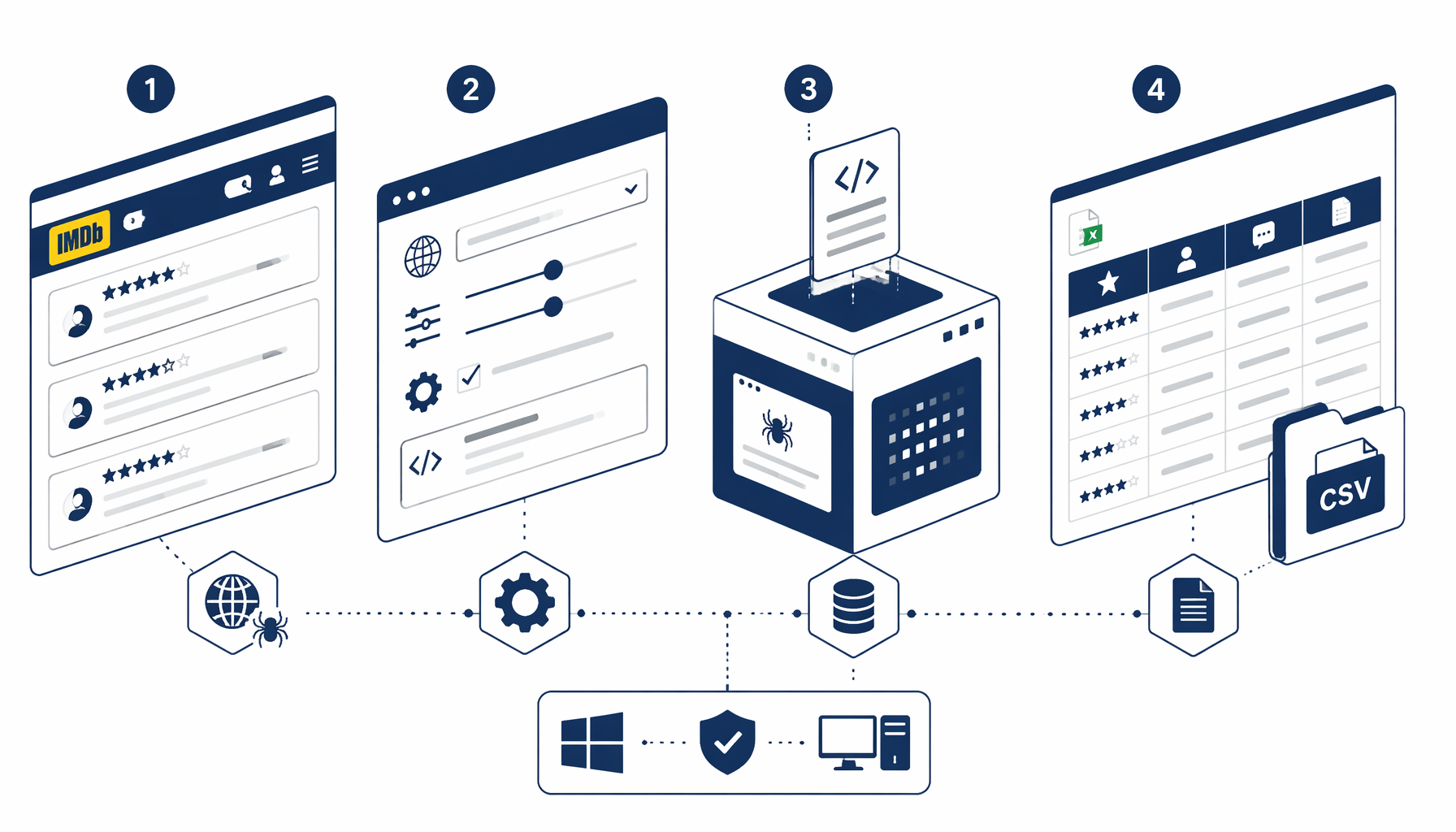
If you want IMDb title reviews in a workbook—rating, short review summary, full review body, and author labels—without maintaining a Puppeteer repo, this tutorial explains the moving parts behind the bundled graph: pagination behaviour, selector hygiene, CSV validation, and when licensed data is the smarter path. When you already know UScraper, jump straight to the IMDb User Reviews Scraper template, import the JSON, and align selectors against your locale.
Before you start
Prerequisites, policy context, and audience
Treat this guide as informational: supply a reviews URL you may access and automate politely, disk space for a growing CSV, and patience for DOM drift—typical for analysts comparing titles or researchers prototyping sentiment views.
Anchor policy with IMDb Conditions of Use, using IMDb data in third-party software, and the IMDb developer hub before redistribution. Selector threads on Stack Overflow illustrate mechanics; contracts still win.
Field map
Columns the structured export pass targets
The IMDb reviews export JSON configures a Structured Export node that grabs one logical review per user-review-item row (name may change—confirm in DevTools). In the blueprint we shipped, column intent maps roughly as follows:
| Column | Typical DOM signal | Practical notes |
|---|---|---|
| Rating | Numeric or star-derived text near the headline | Styled spans often carry hashed classes; fall back to visible text stripped of glyphs. |
| Review | Short summary badge (review-summary) | Great for skim columns in Excel dashboards. |
| Content | Overflow body snippet (review-overflow) | Pair with moderation rules if you circulate quotes externally—length and spoilers vary. |
| Author | Linked display name (author-link) | Useful for deduping accidental re-scrape cycles. |
The JSON also wires waits, scroll helpers that surface more rows, lightweight DOM tagging so batches do not collide, element exists branches, and load-more clicks—spacing that reduces bot-friction spikes.
Pick your path
Three ways teams capture IMDb review text
Best when you need analyst-friendly CSV on Desktop without provisioning headless fleets.
Pros: Visual mapping, CSV append locally, skips per-row cloud metering for modest batches.
Cons: Selector babysitting; deep historical pulls still need patient pacing.
Import the IMDb Reviews template JSON and point navigation at the exact title review surface you verified in Chrome.
Execution
Run the IMDb reviews export end-to-end
Tune, dry-run, then loop
Pin a reviews URL, import the bundled graph from imdb_reviews_export, and walk the nodes slowly the first night: confirm each Structured Export grabs non-zero rows before you trust scroll loops.
Import the template JSON
Download the published workflow into UScraper so navigation, sleeps, Structured Export definitions, DOM helpers, and stop conditions land intact.
Swap in your title reviews URL
Replace placeholder navigation targets with the public reviews page that matches your study—double-check locales (www.imdb.com vs regional hosts) because markup diverges subtly.
Recalibrate selectors
Hover a review card inside DevTools, confirm review-summary, review-overflow, and author anchors resolve per row; adjust row scope if IMDb nests sponsored modules differently.
Dry-run a single wave
Export one batch only, inspect trailing commas, spoiler warnings, truncated bodies, then validate counts against what you scrolled into view manually.
Enable append mode responsibly
Keep headers once, append subsequent passes, archive timestamped filenames when you rerun weekly sentiment snapshots for the same slug.
Throughput discipline: emulate human cadence. Bursting dozens of synchronous scroll cycles triggers throttles—not because your scraper lacked cleverness but because infra teams rightly defend edge caches.
Validation
Validate, dedupe, and escalate issues
Spot-check joins between rating magnitude and textual tone; mismatch often means the rating selector latched onto a spoiler scoreboard or aggregate widget. Maintain a hash of (author, summary snippet) pairs in Python or DuckDB dedupe scripts so iterative loops do not inflate volumes.
When exports read zero rows, assume selectors first; only afterward consider throttling if the DOM genuinely matches your saved selectors.
Local scraping vs hosted scraper APIs
| Dimension | UScraper on Desktop | Hosted actors / APIs |
|---|---|---|
| Data custody | Stays on-disk beside your project folders | Routed through vendor cloud unless self-hosted runners |
| Cost curve | Fits desktop license budgeting | Credits accrue per run or concurrency |
| Engineering load | Maintain DOM contracts visually | Maintain JSON configs and quotas |
| Best for | Controlled internal analyses, teaching flows | Huge fan-out fleets with managed proxies |
Local tooling does not waive platform rules—stay within what counsel and policies allow.
FAQ
Frequently asked questions
IMDb Conditions of Use and help articles describe limits on automated extraction and reuse. Even when reviews look public, copying them at scale, redistributing text, or training models can hit copyright, contract, and regional privacy rules. Many teams keep exports small, slow, and non-public; they document purpose and stop if a site objects. This article is educational—verify current IMDb policies and talk to counsel before commercial use.
Related links and next steps
- Start from IMDb User Reviews Scraper — CSV Export whenever you simply need the authoritative JSON blueprint and changelog notes beside the executable graph.
- Continue exploring Browse all templates—marketplace comparisons sit next to speciality scrapers inside the library index.
- Return to UScraper Blog for neighbouring tutorials on disciplined exports across other platforms.
When CSV rows match manual spot checks, you have repeatable sentiment inputs on disks you control—without metered cloud scrape lanes.