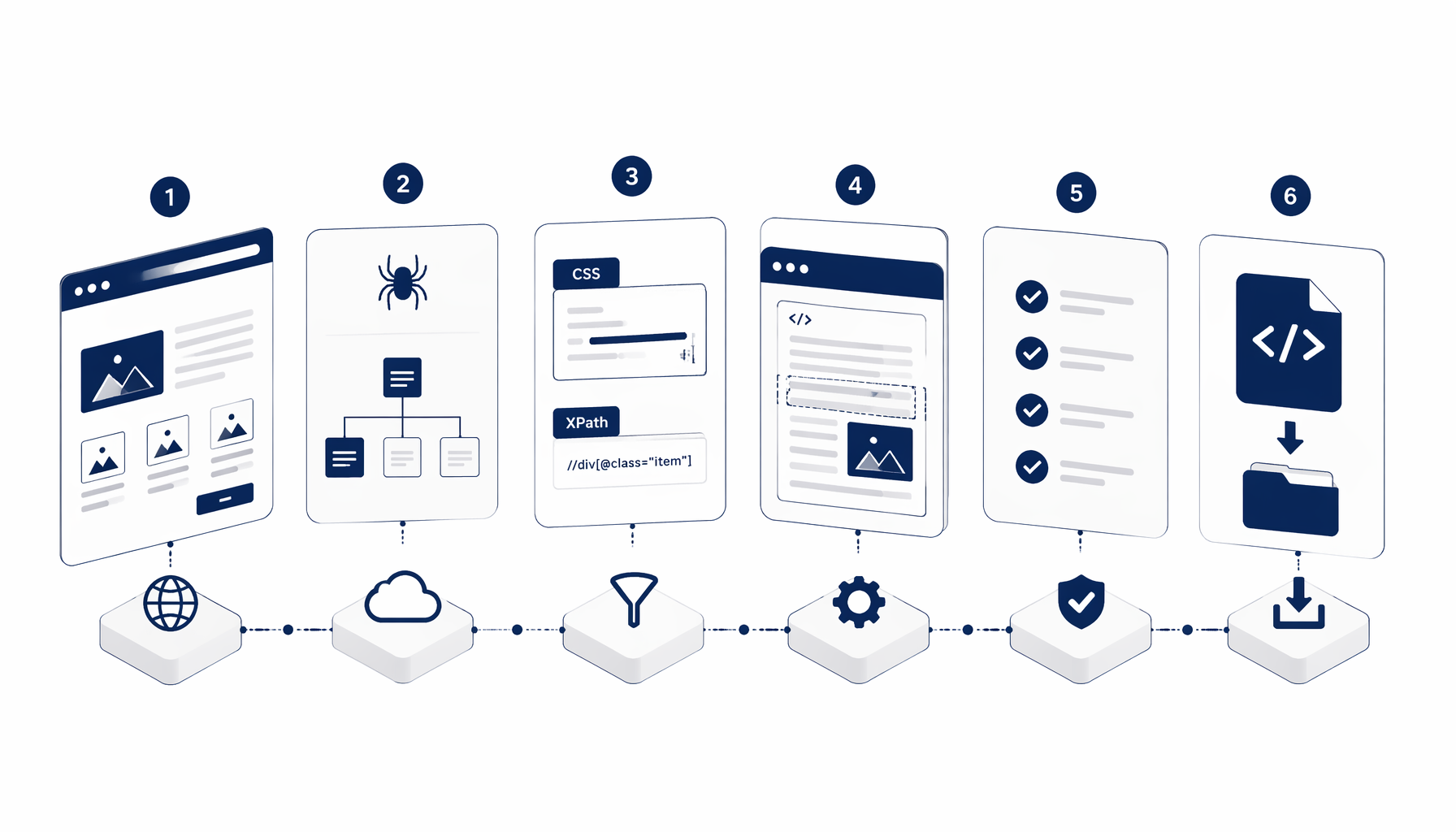
Turning a rendered page into structured snippets—whether you code it or automate visually—is the same discipline: fetch, parse, locate nodes, then verify you grabbed the layer users rely on. This tutorial connects textbook stacks (Beautiful Soup, Scrapy, Cheerio, Playwright) to the fastest click-path on Desktop: import HTML Web Scraper when you want extraction without maintaining bespoke glue scripts.
Before you start
Prerequisites and honest scope
You should be comfortable opening Chrome DevTools, copying selectors, and reasoning about latency (pages rarely yield stable markup at millisecond zero). This guide stays informational: we compare mainstream stacks with docs-first references—Beautiful Soup, Requests, Scrapy, Cheerio, and Playwright for Python—then anchor the no-code path on UScraper.
Foundations
What extracting HTML actually means
Downloading HTML only proves you have bytes on disk. Extracting implies targeting meaningful fragments—outer markup for archiving, innerHTML for nested widgets, or normalized text for analytics—without hauling entire templates full of tracking scripts. Specialists distinguish:
| Phase | Question it answers | Typical tooling |
|---|---|---|
| Fetch | Did we retrieve the authoritative document? | HTTP libraries, headless browsers |
| Parse | Can we traverse nodes safely? | Beautiful Soup, lxml, Cheerio |
| Select | Which subtree maps to our metric? | CSS selectors, XPath |
| Render parity | Does automation match user-visible DOM? | Playwright, Puppeteer, Selenium |
Beginners often skip the last row and wonder why code differs from DevTools—more on that below.
Transport vs renderer
Static responses versus JavaScript-heavy DOMs
Fetch with Requests, httpx, or Node fetch when HTML arrives fully populated—or when you only need <meta> tags and SSR payloads. Pair responses with parsers (Beautiful Soup quick patterns, Cheerio) for efficient iteration.
- Pros: Lightweight, cheap at scale, trivial to unit test.
- Cons: Misses client-rendered islands, infinite-scroll injections, and several bot-calming workflows.
Parser lanes
Beautiful Soup, Scrapy, and Cheerio in one glance
| Lane | Sweet spot | Companion reading |
|---|---|---|
| Beautiful Soup | Rapid prototypes, notebooks, glue scripts | Official Beautiful Soup docs |
| Scrapy | Crawling pipelines, retries, scheduling | Scrapy tutorial, selector reference |
| Cheerio | Server-side DOM slicing with jQuery ergonomics | Cheerio project site |
Performance-sensitive shops sometimes benchmark parsers (BeautifulSoup vs lxml comparisons); choose readability first, optimize once profiling proves pain.
Targeting nodes
CSS selectors versus XPath
CSS shines when classes communicate intent—.price-display span. XPath earns its keep when you need predicates such as “third td in each row containing $” or mixed-namespace feeds. MDN’s XPath primer pairs nicely with Scrapy’s unified selector API so you can prototype both styles without rewriting spiders.
Debugging habit: copy candidate selectors from DevTools, paste into a REPL, assert counts (
len(nodes)) before wiring CSV exports—silent zero-match bugs waste hours.
No-code execution
Run HTML extraction with UScraper on Desktop
Skip bespoke plumbing when your deliverable is dependable innerHTML captures from pages you already trust manually. The HTML Web Scraper template ships JSON describing a Navigate block pointing at your seed URL, a Sleep block giving deferred assets time to settle, and an Extract HTML block targeting selector html with innerHtml enabled—exactly the blueprint echoed in the canonical export bundle (navigate → sleep → extract-html edges).
Download the JSON blueprint
Open HTML Web Scraper in the template library and save the linked workflow definition—the same structure our docs mirror when describing blocks and connectors.
Import into UScraper
Bring the JSON onto your Desktop workstation so blocks render visually; confirm connectors chain Navigate → Sleep → Extract HTML before editing parameters.
Tune waits and selectors
Swap html for tighter wrappers when you only need article bodies; lengthen sleeps if spinners mask content—mirror what you observe in DevTools.
Dry-run with logging
Execute once, inspect captured markup on disk, and diff against View Source to prove you grabbed hydrated DOM, not empty shells.
Promote to repeatable exports
Snapshot selector choices in internal docs so teammates reproduce runs months later without reverse-engineering your clicks.
Quality gates
Validate output and troubleshoot confidently
Compare extracted snippets against Elements rather than View Source whenever SPAs hydrate client-side. Empty fragments usually signal premature scraping, brittle selectors, or shadow DOM boundaries—threads on Stack Overflow’s web-scraping tag catalogue dozens of variants.
Local automation versus managed scrape clouds
| Dimension | UScraper desktop flows | Managed APIs such as ScraperAPI or Zyte |
|---|---|---|
| Custody | Files remain on hardware you control | Processing typically traverses vendor infra |
| Networking | You configure pacing and VPN strategy | Proxy pools abstract rotation complexity |
| Ops burden | You observe crashes firsthand | Dashboards surface quota burn quickly |
Neither column eliminates legal homework—pick tooling after policy alignment.
FAQ
Frequently asked questions
Laws and platform rules vary by country and site. Many practitioners limit automated collection to data they could manually copy, avoid authenticated areas without permission, respect robots.txt where applicable, and throttle requests. Review each site's terms of service and consult counsel for regulated industries—technical ability never substitutes for compliance.
Related links and next steps
- Grab the workflow JSON from HTML Web Scraper—fastest path from reading to running on Desktop.
- Explore sibling blueprints inside Templates when your next export needs tables instead of raw markup.
- Browse Blog for additional tutorials that pair conceptual framing with concrete automation recipes.
When your snippets line up with DevTools and every selector has an owner, you have an HTML extraction practice that survives the next redesign—not just a one-off script tied to today’s class names.