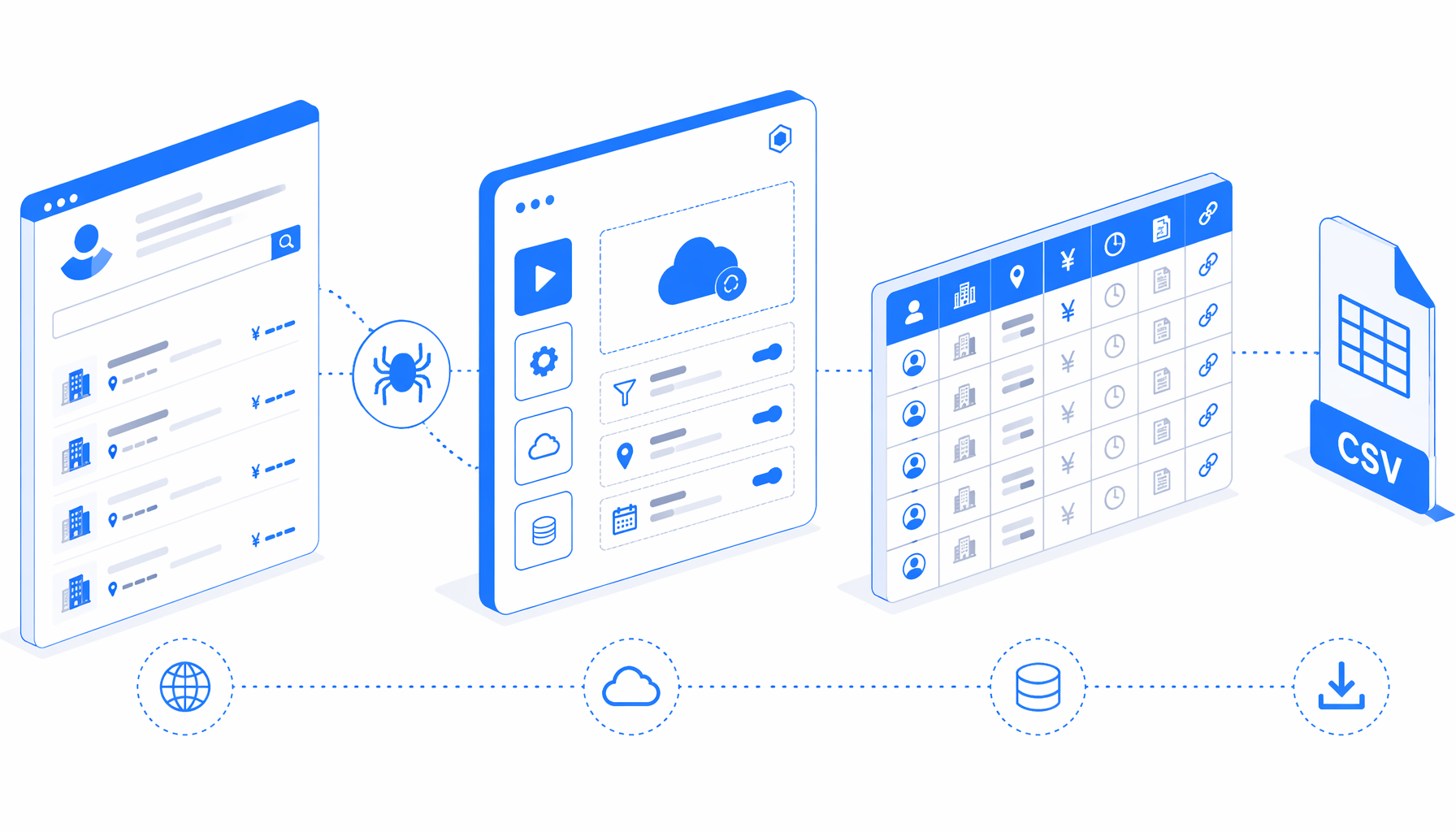
This tutorial shows how to scrape Hello Work job listings into CSV with UScraper. You will import the workflow, edit the keyword, confirm the export path, validate the first page, and decide when a no-code template, Python scraper, hosted tool, or official API is the right path.
Before you start
Prerequisites and source checks
You need UScraper installed as a local desktop app, the free Hello Work workflow JSON, one narrow search keyword, and a local folder where CSV files can be written. The bundled workflow uses the sample keyword 営業, selects full-time and part-time job categories, and writes to hellowork-job-listings-cloud-only-scraper.csv.
Download the maintained workflow from the Hello Work Job Listings Scraper template instead of rebuilding every block by hand. The template page is the download path; this post is the operating runbook.
Before scraping, review the current Hello Work site policy, the official job search page, and the official Hello Work API catalog entry. The API route matters because some projects need approved, machine-readable access instead of browser extraction.
Technical access is not permission. Keep the run narrow, collect only fields you need, avoid access-control bypassing, and get legal review before commercial reuse or redistribution.
Workflow shape
What the Hello Work job scraper does
The JSON export is the source of truth. In plain English, the workflow opens Hello Work, waits for the page, injects a small search helper, waits for result controls, marks each visible job row, exports named fields, marks the active Next control, and loops while pagination continues.
| Workflow stage | What happens | What to verify |
|---|---|---|
| Navigate | Opens the Hello Work job search entry page | Page loads in the expected language and region context. |
| Search setup | Sets keyword 営業 and selected job categories | Replace the keyword and confirm filters before production runs. |
| Row detection | Marks result blocks that include job number, occupation, content, or employer labels | Stop if the page shows an error, no results, or an unexpected layout. |
| Structured Export | Appends one CSV row per marked listing | Confirm headers, filename, save folder, and append mode. |
| Pagination | Finds Next / 次へ, clicks it, waits, and repeats | Watch that page content changes and rows are not duplicated. |
The output is listing-level data, not a full job-detail crawl. Use it for sourcing research, regional hiring snapshots, wage-band review, employer monitoring, and deciding which detail pages deserve manual follow-up.
Runbook
How to scrape Hello Work job listings to CSV
Import the template
Open the Hello Work template page, download the JSON workflow, and import it into UScraper. Keep a clean copy so you can restore the original selectors later.
Edit the search block
In the first JavaScript block, replace 営業 with the approved keyword. Change employment-type checkboxes only when the project scope calls for different filters.
Set the export path
Open Structured Export and confirm hellowork-job-listings-cloud-only-scraper.csv, headers enabled, append mode, and the local save folder.
Run one result page
Start with a narrow search. Compare several exported rows against the browser before allowing the pagination loop to continue.
Validate before scaling
Check occupation, employer, workplace, job content, wage, hours, job number, job-sheet URL, and detail URL. Fix blanks before a larger run.
Continue the Next loop
Let the workflow append more pages only after the first page is correct. Stop if page numbers repeat, rows duplicate, or Hello Work changes layout.
Output
CSV fields to validate
There is no static CSV sample bundled with this article. Use the export shape below plus your first validation run as the sample for the keyword and filters you actually used.
| CSV column | Meaning | QA check |
|---|---|---|
職種 | Occupation or role title | Should match the visible listing title area. |
求人区分 | Job category badge or listing type | Confirm full-time, part-time, or related label assumptions. |
事業所名 | Employer or office name | Watch for missing employer text on compact layouts. |
就業場所 | Workplace location | Compare against the browser for multiline addresses. |
仕事の内容 | Job content summary | Long text may need cleanup after export. |
雇用形態 | Employment form | Validate when the listing mixes badge and label text. |
賃金_手当等を含む | Wage text including allowances | Keep as text unless you normalize yen amounts later. |
求人番号 | Hello Work job number | Use this as a primary dedupe key. |
求人票URL / 詳細ページURL | Job sheet and detail links | Open a few rows to confirm links resolve. |
For spreadsheet work, keep the raw Japanese headers until QA is finished. Rename columns later in a copied file so the raw export remains traceable to the workflow definition.
Alternatives
UScraper vs Python, Octoparse, and the Hello Work API
| Path | Best for | Trade-off |
|---|---|---|
| UScraper template | No-code CSV exports, visible workflow edits, local review | Selectors still need maintenance when Hello Work changes markup. |
| Python Selenium or BeautifulSoup scraper | Developer-owned pipelines and custom parsing | Requires code upkeep, dependency management, and careful throttling. |
| Octoparse Hello Work template | Hosted extraction and cloud scheduling workflows | Less suited when the operator wants a local desktop workflow and editable export blocks. |
| Official Hello Work API | Approved machine-readable access for eligible use cases | Requires following the official API rules and may not fit ad hoc browser research. |
If your search is "hellowork scraping python", use this article as a field checklist even if you code the scraper yourself. If your search is "hello work api scraper", start with the official API documentation first, then use browser scraping only when it is appropriate for the project.
Confirm the search produced visible result rows, then rerun one page. Empty files usually mean the row-marking JavaScript did not find the expected labels or the page was not finished loading.
FAQ
Hello Work scraping FAQ
Is it legal to scrape Hello Work job listings?
Public job-search pages can still be governed by site policy, copyright, privacy law, database rights, and employment-data rules. Review the current source rules, avoid bypassing access controls, keep runs modest, and get legal review before commercial reuse.
Does this replace the official Hello Work API?
No. The official Hello Work job information API is a separate route for approved data use cases. This tutorial covers a browser-based CSV workflow for visible search-result pages and should be used only where that approach is permitted.
What does the Hello Work scraper export?
It exports listing-level fields including occupation, job category, employer, workplace, job content, employment form, openings, wages, hours, holidays, public range, job number, job-sheet URL, and detail-page URL.
Why are some Hello Work CSV cells blank?
Blank cells usually mean the page layout, label text, loading state, keyword result type, or selector assumptions differ from the sample workflow. Run one page first, compare against the browser, then adjust waits or field extraction rules.
Where should I go next?
Use the Hello Work template as the download path, browse related scrapers in the UScraper template library, or scan more tutorials on the UScraper blog.