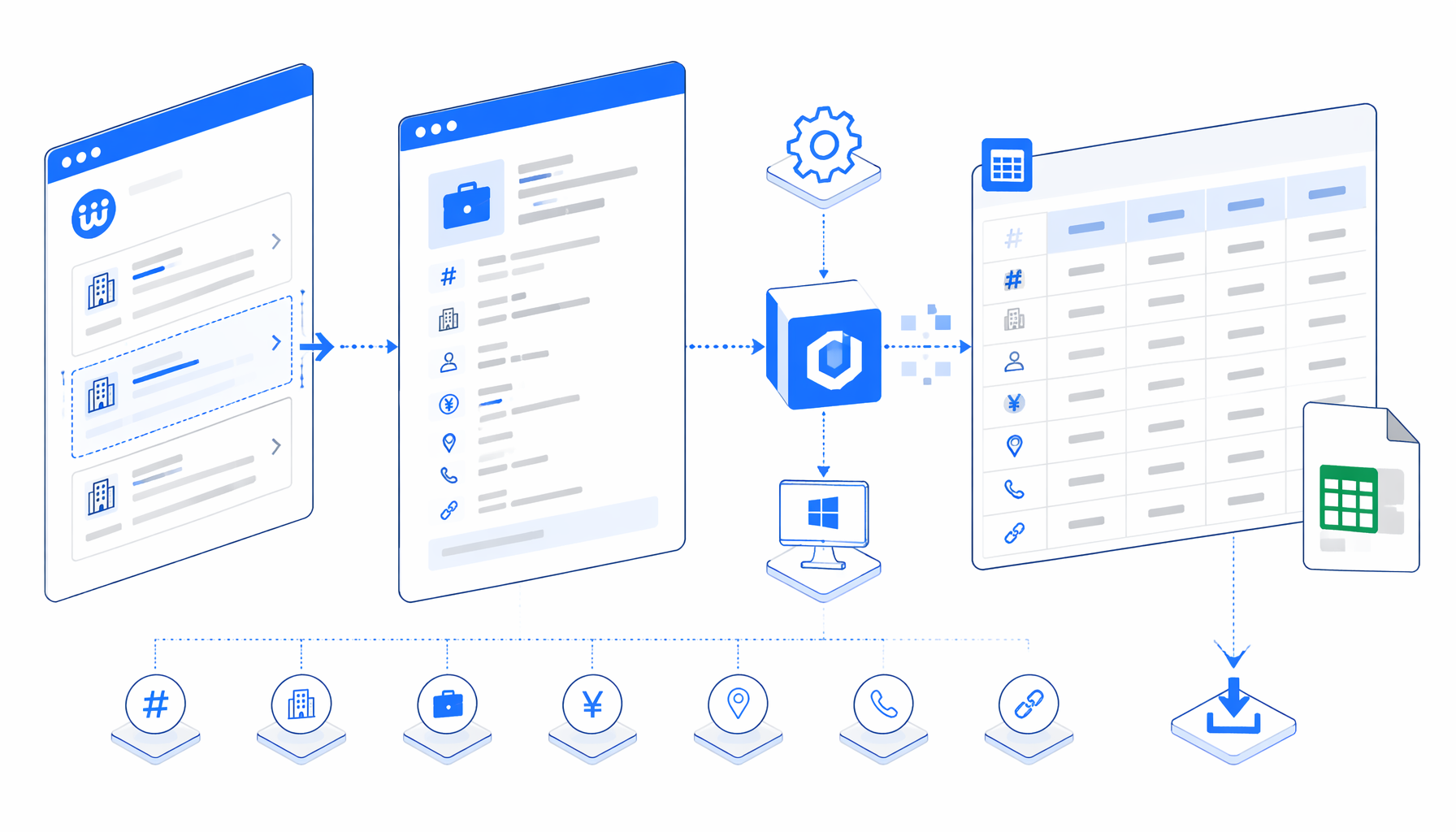
This tutorial explains how to scrape Hello Work job detail pages into CSV with the Hello Work Job Details Scraper for UScraper. The workflow starts from detail-page URLs, not keyword search results, and writes one reviewed row per URL.
Before you start
Prerequisites and source choices
You need UScraper installed as a local desktop app, the current Hello Work Job Details Scraper template, and Hello Work detail-page URLs you are allowed to process. The URLs usually include a kJNo job number parameter; the template loads each page, extracts visible fields, and continues through the list.
Before automation, review the official Hello Work Internet Service, the job and applicant information provision service, and the e-Gov API catalog entry for Hello Work job information. The official API route may be better if you are eligible for a governed XML feed; this post focuses on browser detail URLs and supervised CSV review.
Treat public job pages as governed data. Keep runs modest, avoid login-only or applicant data, do not bypass CAPTCHA or access controls, and ask counsel before redistribution.
Export shape
What the Hello Work job scraper exports
The JSON export is the authoritative workflow definition. In plain English:
Set Window Size -> Navigate URLs -> Wait for Page Load -> Wait for #container
-> Inject JavaScript label helpers -> Structured Export -> Sleep -> Loop Continue
The Navigate block works like multi-URL input: replace or extend navigate.urls with current detail pages, then each URL is loaded, parsed, appended, and followed by the next URL.
| Output group | CSV columns | Validation note |
|---|---|---|
| Job identity | 求人番号, 求人職種, 雇用形態, URL | Confirm the job number and preserve the source URL. |
| Employer profile | 事業所番号, 事業所名, 産業分類, 法人番号, 代表者名 | Match employers and deduplicate rows. |
| Work details | 仕事内容, 就業場所, 基本給_a | Compare against the browser because sections vary. |
| Contact and web | ホームページ, 所在地, 電話番号, FAX, Eメール | Exports only when visible on the page. |
| Scale check | Append-mode CSV with headers | No bundled CSV sample; your first live run is the sample. |
{
"project": {
"name": "Hello Work Job Details Scraper",
"description": "Extracts Hello Work job detail data from supplied detail-page URLs."
},
"blocks": [
{ "title": "Navigate", "config": { "tags": ["multi-url"] } },
{ "title": "Wait for Element", "config": { "selector": "#container" } },
{
"title": "Structured Export",
"config": {
"fileName": "hellowork-job-listings-url-scraper.csv",
"fileMode": "append",
"columns": ["求人番号", "事業所名", "求人職種", "URL"]
}
},
{ "title": "Loop Continue" }
]
}
Runbook
How to scrape Hello Work job details to CSV
Replace the sample URLs
Replace the examples with current detail-page URLs. Avoid search pages and saved-result pages.
Set the export folder
Confirm hellowork-job-listings-url-scraper.csv, keep headers enabled, and choose a project folder.
Run one to five URLs
Watch for expired postings, blank fields, slow loads, verification screens, and encoding issues.
Validate before scaling
Compare rows with the browser. Once they match, rerun a larger approved URL list.
Use a fresh dated filename for final output, then store the original URL list beside the CSV so reviewers can reproduce the run.
Quality checks
Validate the export before scaling
Pick rows from the beginning, middle, and end of the CSV. Open each source URL, compare the page against 求人番号, 事業所名, 求人職種, 仕事内容, 就業場所, 基本給_a, contact fields, and URL, then decide whether blanks are expected.
| Symptom | Likely cause | Fix |
|---|---|---|
| Many columns are blank | Expired or deleted detail URL, verification screen, or page did not reach #container | Replace stale URLs, solve visible challenges manually, then rerun a small batch. |
| Job number exists but other fields are empty | Template fell back to kJNo from the URL | Confirm whether the posting still opens normally in the browser. |
| Duplicate rows appear | Same URL was included twice or append mode reused an old file | Deduplicate by URL and use a fresh dated export file. |
| A field moved or exports the label only | Hello Work layout changed or the specific posting uses a different section pattern | Inspect the page, update the JavaScript label map, and validate again. |
Alternatives
Hello Work API tutorial notes and scraper alternatives
A scraper is not always the right first choice. If your organization qualifies for the official Hello Work job information service, the API may be cleaner than browser extraction. If your team already runs a hosted stack, an Octoparse or Apify actor may fit better.
| Path | Best fit | Trade-off |
|---|---|---|
| Official Hello Work API | Eligible teams needing a governed XML feed | Requires the official provision route and API setup. |
| UScraper template | Analysts with reviewed detail URLs and local CSV needs | You maintain URL quality and selector checks. |
| Octoparse Hello Work template | Teams already using Octoparse templates or cloud runs | Convenient, but compare subscription, custody, and workflow fit. |
| Python or Selenium script | Developers needing tests or custom scheduling | Flexible, but you own dependencies and parser maintenance. |
For a practical hello work vs octoparse decision, start with workflow custody. UScraper is strongest when the person validating the CSV should also see the browser and block graph. The official API is preferred when governance and eligibility line up.
FAQ
FAQ
Browser visibility is not blanket permission. Terms, robots guidance, copyright, privacy law, employment-data rules, and local regulations may still apply. Use approved URLs and get legal review before commercial use.