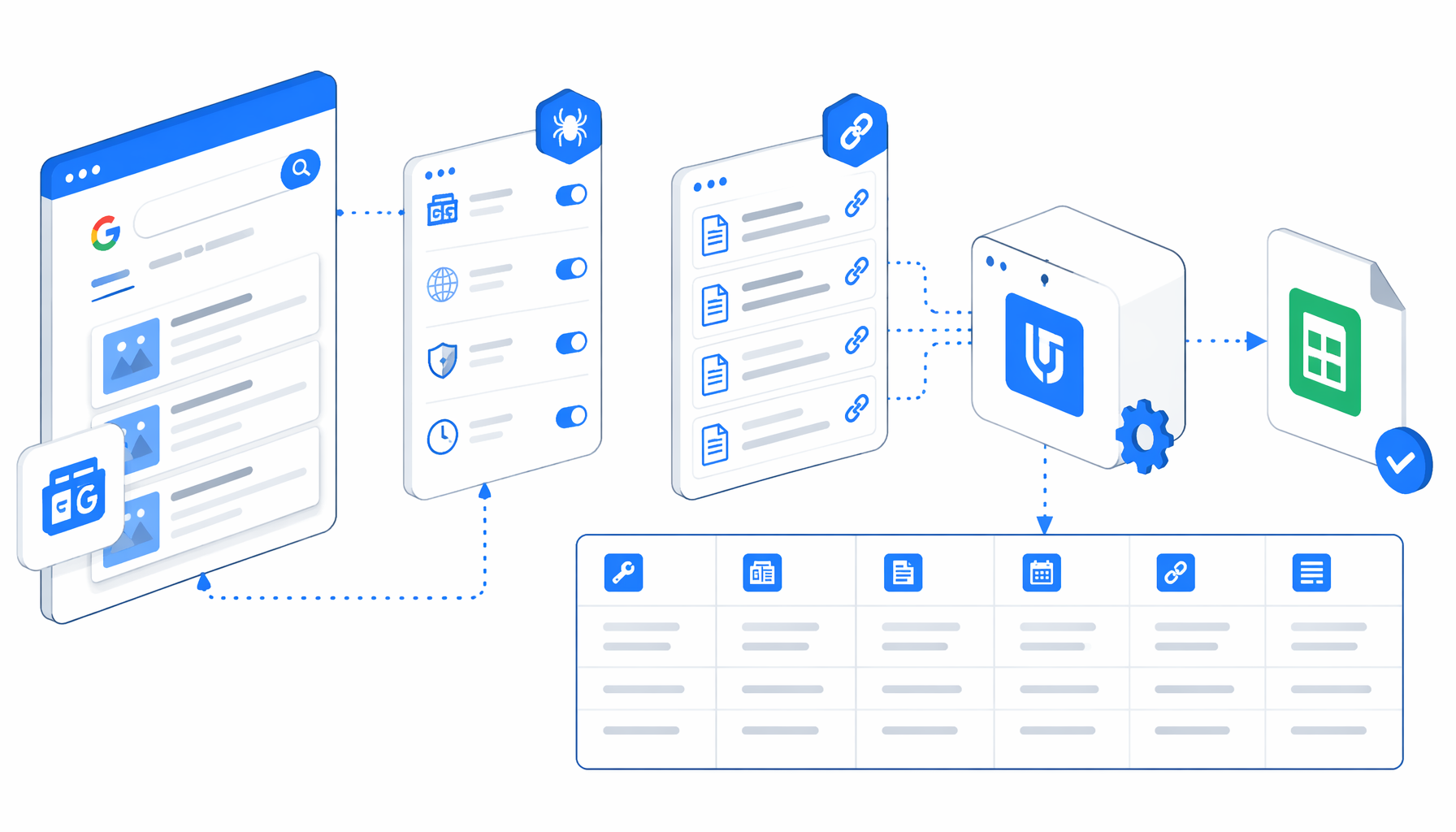
This tutorial shows how to scrape Google News article URLs into CSV with the Google News Scraper by URL template for UScraper. You will prepare a reviewed URL list, import the workflow, set the export path, run a small batch, and validate article text before using the file.
Before you start
Prerequisites, scope, and policy checks
You need UScraper installed as a local desktop app, the Google News Scraper by URL template, a reviewed article URL list, and a folder for CSV exports. Start with five to ten URLs because news pages vary by publisher, language, cookie state, paywall rules, and browser profile.
This is not a Google News discovery crawler. It starts after you already have article URLs from Google News, RSS, Google Alerts, or an internal tracker. Review the links first, then export only the article pages that belong in your dataset.
Technical access is not the same as permission. Do not bypass login walls, paywalls, verification checks, robots rules, publisher terms, or internal data policies.
Workflow anatomy
What the Google News scraper by URL exports
The workflow is: Navigate -> Wait for Page Load -> Inject JavaScript -> Sleep -> Wait for Element -> Structured Export -> Loop Continue. Navigate owns the URL list, the JavaScript step attempts cookie cleanup, Structured Export writes the row, and Loop Continue advances to the next URL.
| CSV column | Extraction intent |
|---|---|
keyword | Reads query parameters, page metadata, or a fallback keyword. |
source | Uses site metadata or the hostname. |
title | Prefers Open Graph title, Twitter title, h1, or document title. |
publish_date | Looks for article publish metadata or time[datetime]. |
news_url | Uses canonical URL, Open Graph URL, or current URL for dedupe. |
news_text | Reads the longest likely article body or main content area. |
The JSON export is the authoritative sample. This excerpt shows the shape you are importing:
{
"project": { "name": "Google News Scraper by URL" },
"blocks": [
{ "title": "Navigate", "config": { "urls": ["https://example.com/news-article"] } },
{ "title": "Structured Export", "config": {
"fileName": "google_news_scraper_by_url.csv",
"includeHeaders": true,
"fileMode": "append",
"columns": ["keyword", "source", "title", "publish_date", "news_url", "news_text"]
} },
{ "title": "Loop Continue" }
]
}
Runbook
How to scrape Google News article URLs to CSV
Prepare a reviewed URL list
Collect links from Google News, RSS, alerts, or manual research. Remove duplicates and keep only URLs your team is allowed to process.
Import the template
Open Google News Scraper by URL, download the JSON workflow, and import it into UScraper.
Replace the sample URLs
Paste approved article URLs into Navigate. Keep the sample count small until the output is clean.
Set the export folder
Confirm google_news_scraper_by_url.csv, headers, append mode, and a project-specific save folder.
Run, inspect, then widen
Run one article, compare the CSV against the browser, then process the remaining URLs after the first row is correct.
After the first pass, sort by news_url. One URL should produce one row. If rows repeat, clear old test exports and dedupe the URL list.
Validation
Validate the CSV before using it
Publisher pages are less uniform than a single search-result page, so a clean run still needs review.
| Symptom | Likely cause | Fix |
|---|---|---|
Empty title | Page did not load or consent blocked rendering | Handle prompts, then rerun one URL. |
Blank publish_date | Publisher omitted date metadata | Accept the blank or add a publisher-specific selector. |
Short news_text | Content is delayed, blocked, paywalled, or in a custom container | Add a wait, or remove the URL if access is not permitted. |
| Duplicate rows | Append mode reused an old CSV or duplicate URLs were supplied | Clear test exports and dedupe by news_url. |
Stop when a publisher blocks the page, asks for verification, or requires subscription access. Continue only when permission is clear.
Alternatives
Google News RSS, APIs, and URL-list scraping
Google News RSS is often the first stop for teams searching "how to scrape Google News" because it can turn a keyword query into headline links. Third-party guides document language, region, and edition parameters, but those notes are unofficial and may change. Use RSS as discovery, not proof that article text can be copied.
Hosted Google News API alternatives can return normalized JSON and schedule recurring pulls. UScraper fits a different job: a supervised local desktop workflow where an analyst can see the browser, revise selectors, and export reviewed articles to CSV.
| Approach | Best for | Trade-off |
|---|---|---|
| Google News RSS | Finding candidate links | Unofficial behavior and limited article body extraction. |
| Hosted Google News API alternative | Programmatic JSON, quotas, scheduling, and team infrastructure | Data passes through vendor systems and pricing is usually usage-based. |
| UScraper by URL workflow | Reviewed article URLs, local CSV custody, and browser QA | Requires selector maintenance and validation. |
For more workflow options, browse the UScraper templates library or related tutorials on the UScraper blog.
FAQ
FAQ
Is it legal to scrape Google News article URLs?
Automated collection can be limited by Google rules, publisher terms, robots directives, copyright, privacy law, paywalls, and internal policies. Use modest batches and get legal review before resale, republication, or AI training.
Do I need a Google News API key?
No. The workflow opens the article URLs you provide in the local browser session. For managed JSON, quotas, or service-level commitments, compare hosted Google News API alternatives.
What does the Google News scraper by URL export?
It exports google_news_scraper_by_url.csv with keyword, source, title, publish_date, news_url, and news_text columns. Append mode adds one row per supplied URL.
Why are some news_text cells blank?
Blank text usually means blocked access, login requirements, delayed loading, unusual article markup, or selector drift. Inspect the page before scaling.
Where does the CSV file go?
The workflow saves google_news_scraper_by_url.csv to the Structured Export folder. It stays local unless you add an upload or sharing step.
How many Google News articles can I process?
Batch size depends on URL quality, page weight, network speed, consent prompts, paywalls, rate limits, and selector maintenance. Start small and scale gradually.