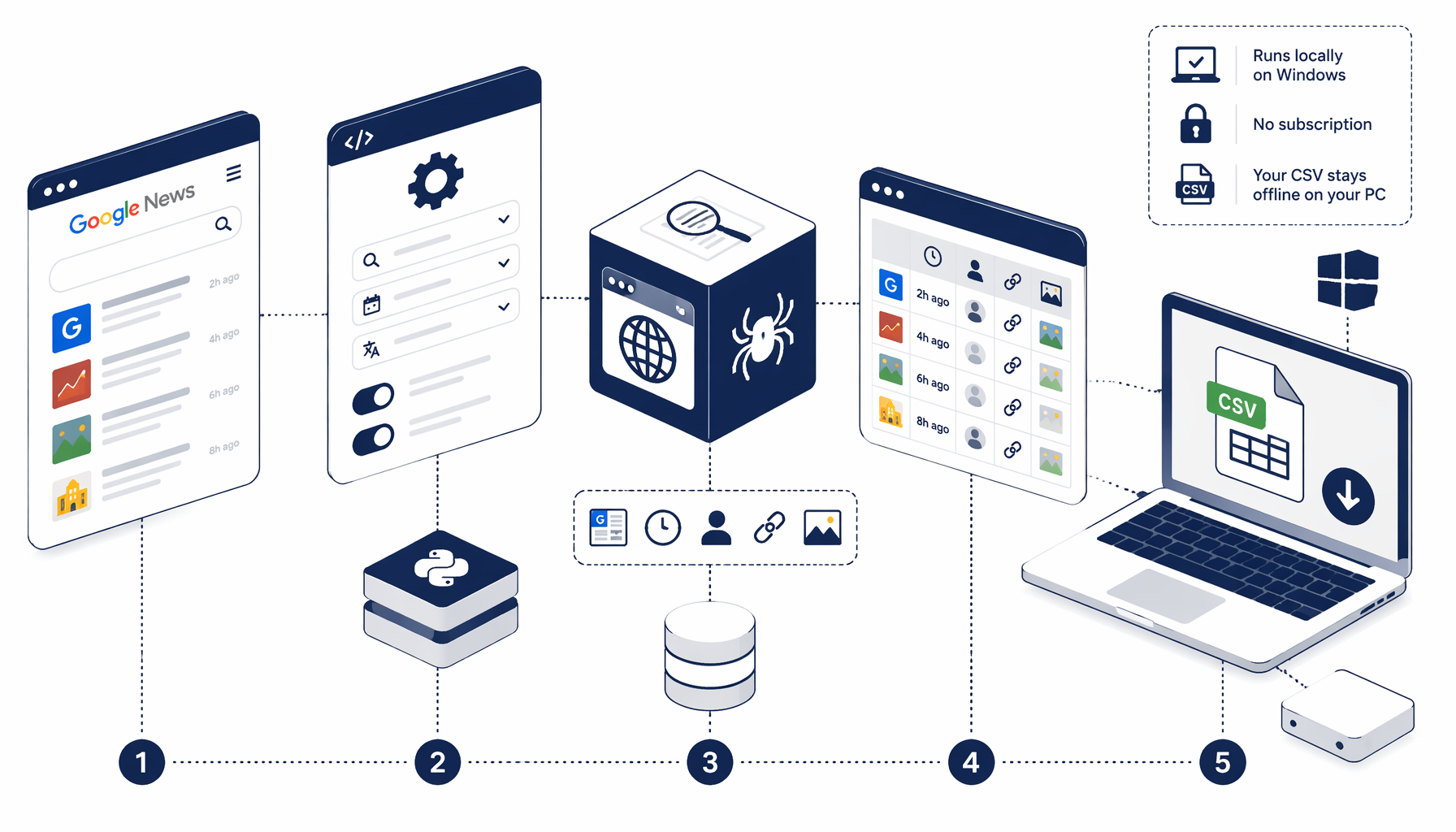
This tutorial explains how to collect Google News keyword topic cards—headline text, timestamps, bylines, outbound article URLs, and thumbnail sources—into google-news-keyword.csv using Structured Export inside Google News Keyword Scraper on Desktop. You will understand why teams still parse Google News RSS search parameters for lightweight alerting, why DOM automation mirrors news.google.com the way analysts read it, and when hosted stacks such as Apify Google News actors or SerpApi Google News make sense versus offline desktop custody championed throughout Blog guidance.
Baseline
Prerequisites, Google News realism, and policy guardrails
You need UScraper running on Desktop (Windows 10+ or macOS M1 or later), familiarity with Chromium DevTools, patience for carousel markup churn, humility about personalization effects (signed-in layouts differ!), disk space for append-mode CSV rehearsals, bandwidth that tolerates sleeps without hammering Google's edge, willingness to reconcile policies from Publisher Center Help, and workloads that resemble focused editorial QA—not bulk resale of scraped stories.
Horizontal rules intentionally break pacing while you jot compliance notes referencing counsel.
What you are extracting (versus RSS-only stacks)
RSS keyword URLs remain a pragmatic choice when you crave XML stability; community writeups—including Octoparse’s Google News walkthrough, ScrapingBee’s RSS versus HTML scrape guide, and scrapfly overview of Google News APIs—map where each approach shines.
This template instead targets live topic HTML rendered in the feed you skim during morning scans. That fidelity matches stakeholder screenshots but inherits layout drift parity with scripted Beautiful Soup notebooks (example DEV tutorial).
| Column | Structured Export intent bundled with Google News Keyword Scraper |
|---|---|
| Title | Primary headline text wired through anchored links |
| Time | Relative / absolute timestamps parsed from time elements |
| Author | Outlet or byline snippets exposed as .bInasb text |
| Link | Canonical article URL derived from href on headline anchors |
| Image | Featured art URL via first matching img src |
Export shape takeaway: Structured Export attaches rowSelector: "c-wiz", includes headers once, defaults to fileMode append, and persists google-news-keyword.csv beside other Desktop artefacts you govern—no intermediary cloud bucket unless you deliberately add uploads.
Truncated authoritative excerpt—download the shipping JSON beside Google News Keyword Scraper for connectors and durations:
{
"version": "1.0.0",
"project": {
"name": "Google News Keyword Scraper"
},
"blocks": [
{
"block_id": "navigate-1776659250645",
"block_type": "process",
"title": "Navigate",
"config": {
"url": "https://example.com"
}
},
{
"block_id": "sleep-1776659441095",
"block_type": "process",
"title": "Sleep",
"config": {
"duration": 5
}
},
{
"block_id": "inject-javascript-1776660473414",
"block_type": "process",
"title": "Inject JavaScript",
"config": {
"jsCode": "document.querySelectorAll('c-wiz').forEach(el => el.setAttribute('data-processed', 'true'));",
"waitForCompletion": true,
"timeout": 10
}
},
{
"block_id": "structured-export-1776659534813",
"block_type": "process",
"title": "Structured Export",
"config": {
"fileName": "google-news-keyword.csv",
"columns": [
{ "name": "Title", "selector": ".JtKRv", "attribute": "text" },
{ "name": "Time", "selector": "time", "attribute": "text" },
{ "name": "Author", "selector": ".bInasb", "attribute": "text" },
{ "name": "Link", "selector": ".JtKRv", "attribute": "href" },
{ "name": "Image", "selector": "img", "attribute": "src" }
],
"rowSelector": "c-wiz",
"includeHeaders": true,
"fileMode": "append"
}
},
{
"block_id": "scroll-1776660345456",
"block_type": "process",
"title": "Scroll",
"config": {
"amount": 100000
}
}
]
}
Choose your ingestion lane before touching selectors
Strength: CSV lineage stays beneath %USERPROFILE%, pacing mirrors how editors manually scroll news.google.com, and Google News Keyword Scraper ships the looping graph so you blueprint rather than reinvent connectors.
Trade-off: You maintain selector archaeology whenever Google rotates c-wiz shells—the same upkeep burden surfaced in OSS helpers like pygooglenews whenever Google tweaks feeds.
Hybrid idea: sanity-check selectors here before promoting rows into Looker dashboards backed by sanctioned APIs.
Validate rows before widening coverage
Operational editors treat Google News scraping like flight checklists—not heroics:
- Confirm
NavigateURLs reproduce the headline mix you scoped (topic pages differ from personalization bubbles). - Compare exported titles character-for-character against the UI to catch truncation quirks.
- Resolve outbound article URLs ethically before downstream crawling; some entries route through trackers.
- Hash dedupe nightly append batches so reruns cannot silently duplicate crisis coverage.
- Log sleep adjustments whenever WAN latency spikes—you want predictable pacing, not brute force.
Journalism teams often pair carousel exports with notebooks from Medium tutorials or YouTube walkthroughs referencing pygooglenews; UScraper simply keeps the fidelity inside the same Structured Export primitives those scripts imitate.
Operational flow
Run the CSV export reliably on Desktop
Grab JSON from Templates
Navigate to Google News Keyword Scraper on Templates, press download, import into UScraper so Navigate / Sleep / Inject / Structured Export / Scroll / Element Exists arcs appear without redraw.
Paste the authoritative topic URL
Replace the placeholder Navigate host with the encoded Google News query that mirrors stakeholder intent—omit abusive parameter soups and stay inside policy allowances.
Tune Sleep for your WAN personality
Increase dwell durations when shimmering placeholders appear; shortening sleep is cheaper until Google throttles the session outright.
Smoke-test Structured Export
Run one loop exporting google-news-keyword.csv, open it in Excel, verify header alignment and UTF-8 diacritics, then toggle append responsibly.
Iterate scroll + prune loops
Observe how Scroll distance and inject-mark-clean cycles strip already exported c-wiz bundles before Element Exists terminates the choreography.
Share Blog + Templates with teammates
Point newcomers at Blog for rationale and Google News Keyword Scraper for refreshed JSON anytime Google rotates markup microcopy.
Local UScraper versus hosted Google News services
| Dimension | UScraper + Google News Keyword Scraper | Typical hosted Google News API / actor |
|---|---|---|
| Data residency | Rows stay beneath your workstation | Routed through vendor regions / proxies |
| Cost curve | Desktop license plus selector TLC | Metered egress with quota dashboards |
| Schema stability | Your team tracks DOM drift | Vendors emit change logs alongside scrapes |
| Best for | Editorial decks, stakeholder CSV proofs | Fully automated alerting fleets |
FAQ
Frequently asked questions
Automating Google surfaces can violate Google Terms of Service, robots rules, publisher copyrights, scraping statutes, or privacy rules even when headlines look public. Use modest volume with human pacing, avoid bypassing login walls or paywalls, do not defeat CAPTCHAs, consult counsel before commercial resale, and keep evidence of consent where applicable. Running UScraper on your desktop does not remove those obligations.
Related links and next steps
- Anchor every experiment by importing
google_news_keyword_scraper_export.jsonfrom Google News Keyword Scraper so Navigate, Structured Export, and loop guards stay coherent. - Pair this guide with sibling posts across Blog and widen coverage using additional rows inside Templates when leadership requests parallel SERP monitors.
- When hosted APIs win the procurement battle, cite this tutorial's CSV artefacts as qualitative proof that dashboards deserve budget—your append-mode trail already exists.
Iterate locally, reconcile selectors weekly, escalate to vendors only once throughput outgrows deliberate desktop pacing anchored in Google News Keyword Scraper.