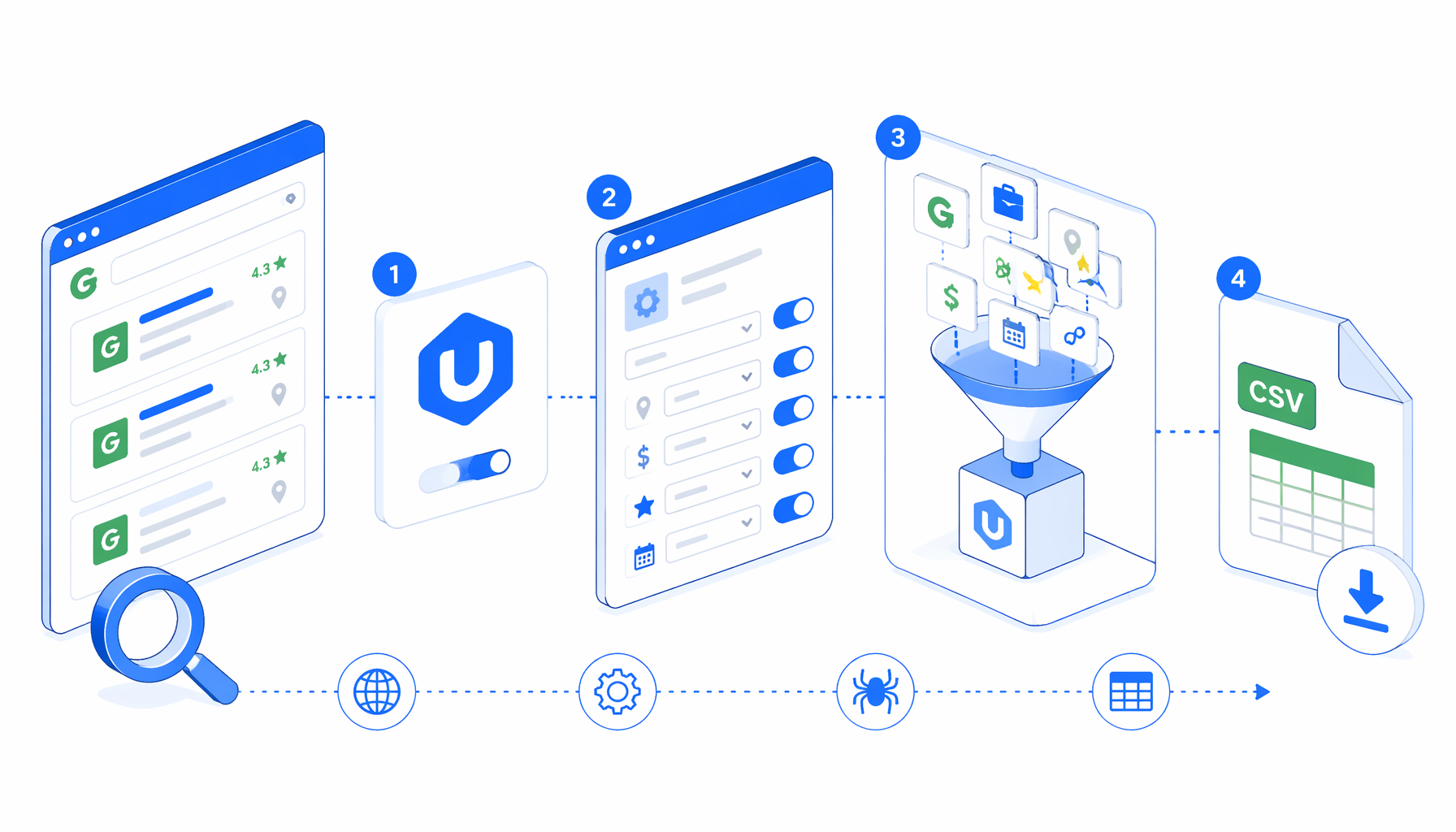
This tutorial shows how to scrape Glassdoor jobs into CSV with the Glassdoor Job Scraper template for UScraper. You will import the workflow, choose a search URL, set the export path, validate the result, and troubleshoot blocked or empty runs.
Before you start
Prerequisites and policy checks
You need UScraper installed as a local desktop app, permission to process the target pages, and a folder where the CSV can be saved. Start with the bundled business analyst search. That first run tells you whether Glassdoor is accessible and whether the current layout still matches the template.
Before collecting data, review the official Glassdoor job search, robots.txt, and terms history pages. Browser visibility does not mean every automated use is allowed. Keep volume modest, avoid private or login-only data, do not bypass access controls, and get legal review before commercial use.
Use this workflow as a supervised research tool, not as a way to force past CAPTCHA, Cloudflare, sign-in walls, or other access-control screens.
Workflow anatomy
What the Glassdoor job scraper template does
The companion JSON is the source of truth. It sets the browser window to 1920 by 1080, opens a Glassdoor search URL, waits for the page body, handles overlays, scrolls for listings, and loops through available Load More or Show More Jobs controls. After pagination, JavaScript creates hidden .uscraper-job-row elements, and Structured Export reads them into a CSV.
The stock search targets business analyst jobs in the United States. You can edit the Navigate block for another role or location. Glassdoor URLs often encode location and keyword details, so copy the final browser URL instead of hand-building it.
| Block group | What it does | What to verify |
|---|---|---|
| Entry and load | Sets window size, navigates, waits for body | The page reaches the real job search view, not a prompt or block page. |
| Interaction | Closes common overlays and marks load-more controls | No consent or sign-in overlay covers the results list. |
| Pagination loop | Clicks Load More or Show More Jobs until unavailable | New cards appear after each click and the loop stops cleanly. |
| Data extraction | Normalizes cards and embedded data into stable rows | At least one .uscraper-job-row exists before export. |
| Structured export | Appends rows to glassdoor-scraper.csv | Headers, file mode, and save folder are correct. |
Runbook
How to scrape Glassdoor jobs to CSV
Run the bundled search once
Keep the default business analyst search for the first pass. It gives you a known baseline before you change keyword, location, or export settings.
Replace the search URL
Use Glassdoor search in your browser, apply role and location filters, then paste the final URL into the Navigate block.
Set the export folder
In Structured Export, change the save folder from the bundled local path to your project folder and keep glassdoor-scraper.csv easy to find.
Validate before scaling
Run one search, open the CSV, compare rows with the browser, then repeat for another keyword or location.
Edit selectors only after the page loads, the loop stops, and the output file appears.
Output
CSV export columns from the workflow
The bundle does not include a sample CSV, so the export shape comes from the JSON definition. The workflow writes headers and uses append mode. If you rerun the same search, archive or clear the old CSV first.
glassdoor-scraper.csvColumn
keyword
Search keyword context.
Column
location
Search location context.
Column
rating
Visible employer rating.
Column
company
Employer name.
Column
job_title
Visible job title.
Column
place
Job location text.
Column
salary
Visible salary text.
Column
post_date
Posting age.
Column
job_description
Cleaned description or snippet.
Column
keyword_backup
Backup keyword label.
Column
job_url
Listing URL.
For recruiting research, validate company, job_title, place, and job_url first. Treat salary as optional because many listings do not expose a range. For monitoring, keep post_date and job_url together.
Quality control
Validate the Glassdoor job export
Open the CSV beside the browser and check the first, middle, and last visible rows. A good run has a non-empty company, job title, place, and URL for most rows. Empty salary or rating cells can be normal. Empty titles or a single diagnostic row means the run needs attention.
| Symptom | Likely cause | Fix |
|---|---|---|
Only one NO_RESULTS_OR_BLOCKED row | Login wall, CAPTCHA, Cloudflare check, no results, or layout drift | Open the page manually, resolve legitimate prompts, reduce volume, or stop the run. |
| Repeated rows | The CSV was in append mode across duplicate runs | Clear the file or save to a new folder before rerunning. |
Missing job_url | Listing links changed or cards rendered without anchor tags | Inspect one card and update the link selector only after access is confirmed. |
Blank salary | Salary was not visible for that listing | Leave it blank; do not infer salary values from unrelated pages. |
| Wrong keyword or location context | The Navigate URL changed but labels stayed default | Update the keyword and location defaults in the extraction step. |
Alternatives
Glassdoor scraper vs API and hosted tools
A local desktop workflow is strongest when you need a supervised CSV export, visible browser QA, and no-code edits. A Glassdoor jobs API or licensed data provider is stronger for contractual access, stable schemas, scheduled feeds, SLAs, or redistribution rights. Hosted scraper platforms can help with queues, but data usually passes through a vendor cloud.
| Option | Good fit | Trade-off |
|---|---|---|
| UScraper template | Reviewable Glassdoor jobs to CSV from a local workflow | Best for supervised batches, not unattended high-volume crawling. |
| Glassdoor jobs API or data provider | Production feeds, contracts, dashboards, and repeat delivery | Requires provider terms, pricing, and integration work. |
| Custom Python or JavaScript scraper | Engineering teams needing full control | Requires selector maintenance, retries, storage, monitoring, and compliance review. |
| Hosted no-code scraper | Managed infrastructure and scheduled runs | Vendor custody and usage-based pricing may matter. |
If you are comparing "best Glassdoor scraper" options, decide on custody and permission first. For a quick research spreadsheet, the UScraper template library keeps the workflow inspectable. For a production hiring product or resale dataset, use an approved data path.
FAQ
Frequently asked questions
Glassdoor job pages may be visible in a browser, but automated collection can still be restricted by terms, robots directives, copyright, database rights, privacy law, and employment-data rules. Review current policies, avoid private or login-only data, keep runs modest, and get legal advice before commercial use.
Next step
Download the Glassdoor job scraper template
Download the JSON from Glassdoor Job Scraper, run the bundled search once, and validate the CSV. For neighboring workflows, browse all UScraper templates or the UScraper blog.