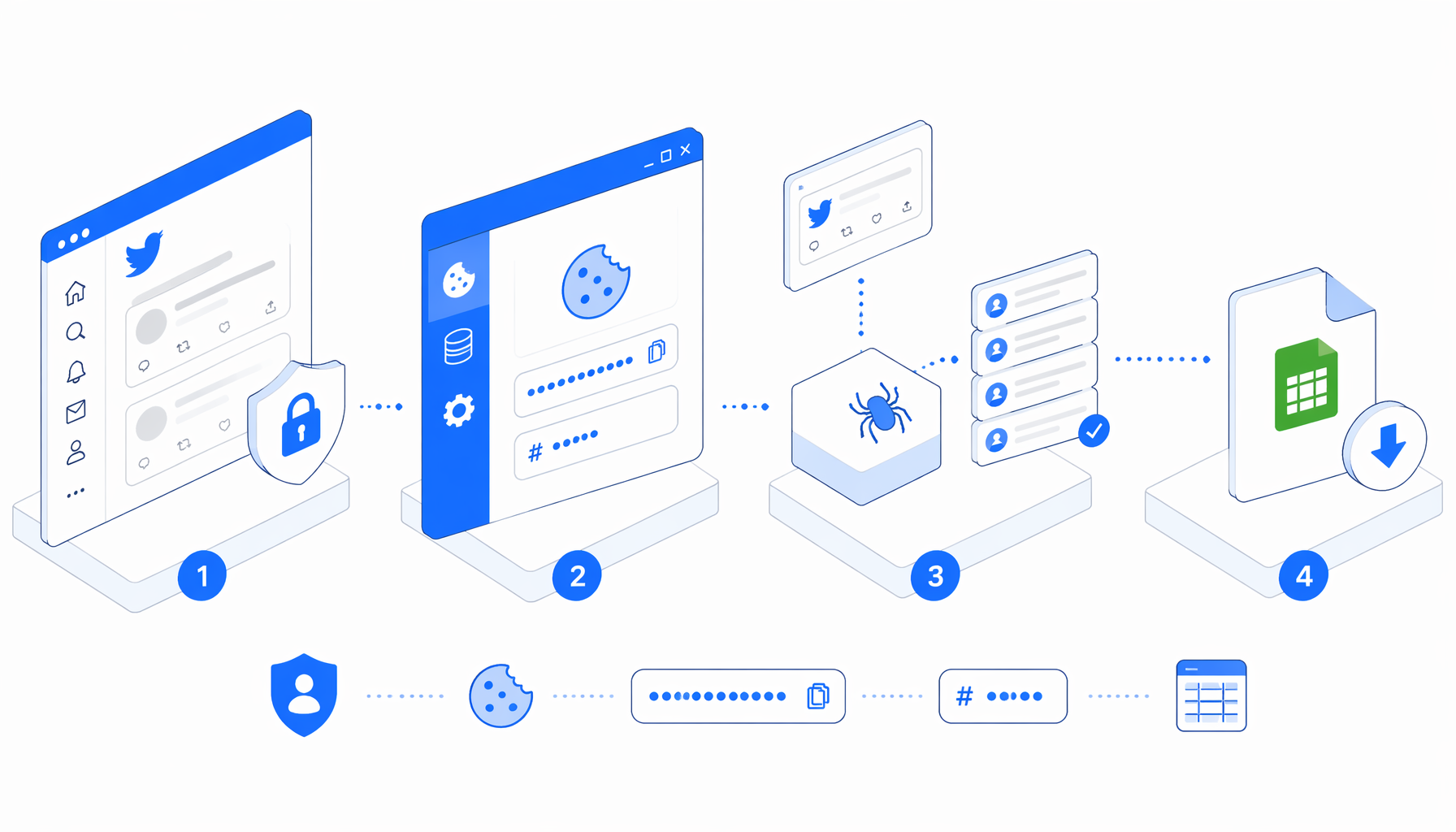
This tutorial explains how to get Twitter cookies from an authorized X/Twitter browser session, why the auth_token and ct0 cookies show up in many scraper setup guides, and how to export a local CSV with the Twitter Cookies Extractor template in UScraper. Use it for your own accounts, QA environments, migration checks, or approved internal automation setup.
Context
Why Twitter cookies matter for scraper setup
Many developers search for scrape Twitter without API key when they are testing internal workflows, researching public posts, or trying to run tools such as twscrape, Twikit, Scweet, or other browser-session based clients. Those projects often support cookie-based sessions because X's website already knows who you are after login, and some libraries can reuse that authenticated state.
That does not make cookies a magic API key. A cookie string is closer to a temporary session credential. It can expire, be revoked after a password change, fail after two-factor verification, or become invalid when X changes web flows. It can also grant real access to the account behind it, so it belongs in a password manager, secrets vault, or tightly controlled local folder, not in chat logs or shared spreadsheets.
The practical goal is not "stealth." The practical goal is a repeatable, authorized way to inspect which JavaScript-readable cookies exist after login and save that diagnostic state locally.
UScraper's related template is intentionally narrow. It opens X advanced search, handles the visible login branch when needed, waits for the page, and writes one row into get-twitter-cookies.csv. It does not scrape tweets, followers, profiles, or search results.
Prerequisites
What you need before exporting cookies
Use a clean setup so the result is easier to trust:
- A UScraper local desktop app installation.
- An X/Twitter account you own or have written authorization to administer.
- Any required two-factor device, email inbox, or verification method nearby.
- A private local folder for the CSV export.
- A clear reason for the cookie export: QA, session validation, authorized scraping setup, or library configuration testing.
The cookie fields people ask about
The exact cookie set can change, and not every cookie is available to JavaScript. These names explain the usual setup language you will see in open-source scraper documentation.
| Field | What it usually means | How to handle it |
|---|---|---|
auth_token | A web session token associated with a logged-in X account. | Treat as sensitive. Rotate if exposed. Never publish it. |
ct0 | A CSRF-related token often paired with authenticated web requests. | Keep it with the same session as auth_token; do not mix accounts. |
cookie_string | The semicolon-delimited cookies visible through document.cookie. | Store locally, encrypt where possible, and delete old exports. |
cookie_count | A quick diagnostic count of visible cookie pairs. | Use it to spot blank exports, not as proof that login succeeded. |
login_state | UScraper's best-effort page text check. | Validate manually when it reports login_required_or_failed. |
Workflow
How to get Twitter cookies with UScraper
Download the template
Open the Get Twitter Cookies template from the templates library and import the JSON workflow into UScraper.
Review the login placeholders
Replace REPLACE_WITH_X_USERNAME and REPLACE_WITH_X_PASSWORD with credentials for an authorized account, or remove those steps if you prefer to log in manually during the run.
Set the export folder
In Structured Export, choose the local save location where get-twitter-cookies.csv should be created. Use a private folder, not a shared sync directory.
Run and complete verification
Start the workflow. If X asks for 2FA, CAPTCHA, email confirmation, or suspicious-login review, pause and complete only the verification you are authorized to complete.
Validate the CSV
Open the CSV and check current_url, login_state, cookie_count, and cookie_string. A blank string or low count means the session may not expose the cookies you expected.
The template has two branches. If the username field appears, UScraper follows the login path, enters the editable placeholders, clicks through, waits, and exports. If the username field is absent, the workflow assumes the browser may already be logged in and exports the current session state immediately.
What the export looks like
The bundled workflow writes a single diagnostic record, not a paginated data set. The authoritative JSON defines the output columns this way:
{
"fileName": "get-twitter-cookies.csv",
"columns": [
{ "name": "extracted_at", "selector": "new Date().toISOString()" },
{ "name": "current_url", "selector": "window.location.href" },
{ "name": "login_state", "selector": "document.body.innerText.includes('Happening now.') || document.body.innerText.includes('Email or username') ? 'login_required_or_failed' : 'possibly_logged_in'" },
{ "name": "cookie_string", "selector": "document.cookie || ''" },
{ "name": "cookie_count", "selector": "String((document.cookie || '').split(';').filter(Boolean).length)" }
]
}
After export, inspect the file before passing values into any downstream tool. If your target library expects auth_token and ct0, confirm both names are present in the same cookie_string. If one is missing, rerunning faster will not help; you likely need a fresh manual login, a different browser session, or a library setup path that accepts a full saved browser profile instead of document.cookie.
Validation
Common issues and fixes
It may be HTTPOnly, expired, tied to another browser profile, or absent because the login did not finish. Complete the visible login flow, refresh the page, and rerun the export. If it still does not appear in document.cookie, do not try to bypass the browser protection.
When not to use cookies
Use X's official developer platform when you need stable production access, team governance, documented rate limits, auditability, or long-running integrations. Cookie exports are better suited to controlled diagnostics and short-lived setup tests. They are brittle by design because they depend on browser session state, page markup, and account trust signals.
For a broader workflow, start in the UScraper blog for tutorials, then use the template library to find importable building blocks. For this specific task, the download path is the Twitter Cookies Extractor template.