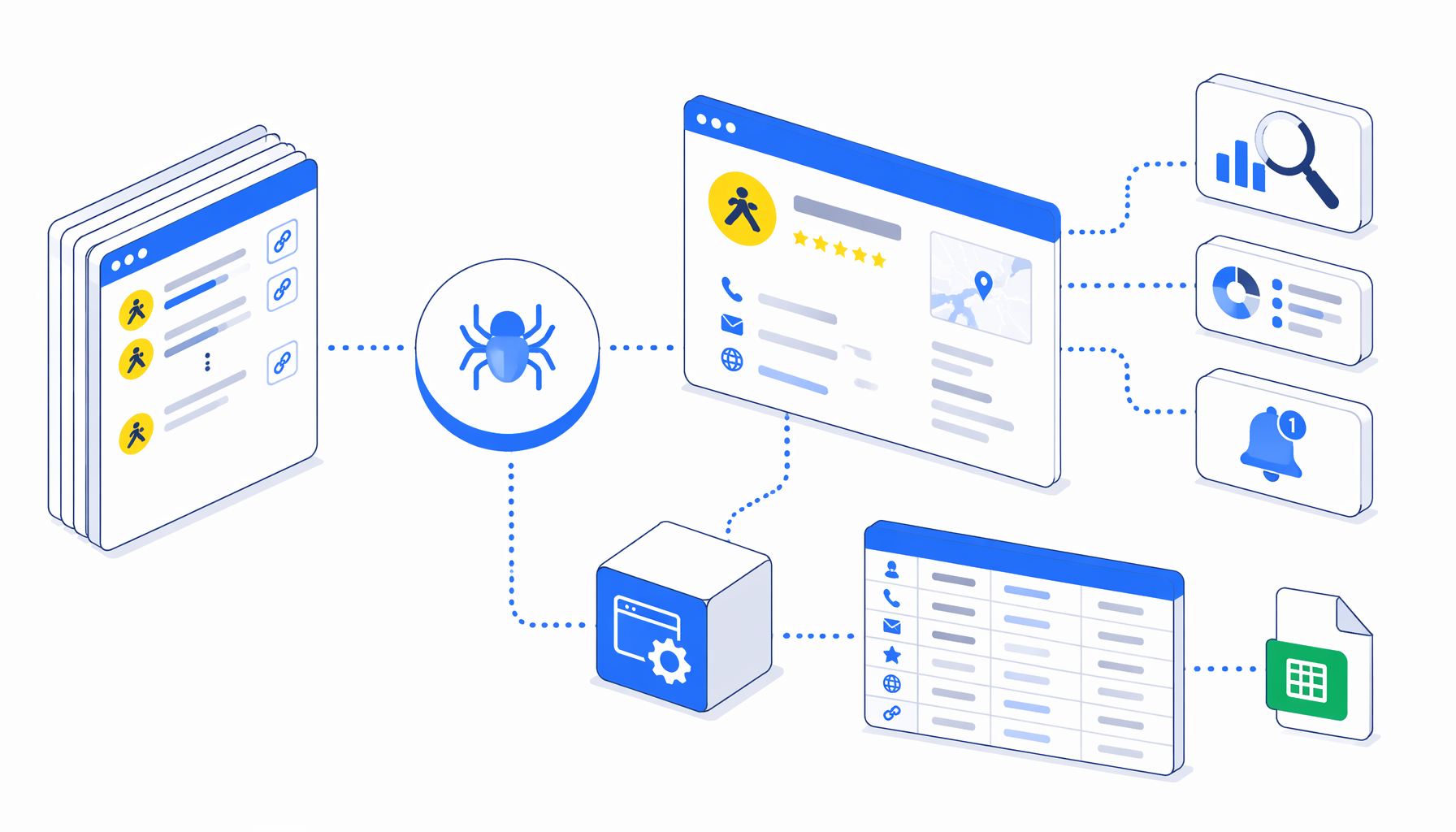
Gelbe Seiten lead extraction is useful when a team already knows which business profiles matter and needs a clean, auditable spreadsheet. The Gelbe Seiten Scraper by URLs template turns approved Gelbe Seiten /gsbiz/ detail URLs into a local CSV with names, ratings, contacts, websites, opening hours, descriptions, and source URLs.
Use-case frame
How to scrape Gelbe Seiten when the URL list is already known
Many "how to scrape Gelbe Seiten" projects do not start with a blank search box. They start after a person has already built a shortlist: clinics near a service area, local competitors, campaign prospects, or businesses found through another listing workflow.
At that point, keyword search and pagination are not the main problem. Repeatability is. Copying company names, phones, websites, and opening hours by hand creates inconsistent notes. Screenshots are hard to filter. Bookmarks do not show which profiles have email addresses, low review counts, missing websites, or strong category fit.
The URL-based template is built for that second step. You supply known Gelbe Seiten detail URLs. UScraper opens each one, waits for the company heading, extracts fields from the page body, appends a CSV row, and moves to the next URL.
The value is not "scrape everything." It is turning a controlled page list into auditable rows.
Personas
Who uses Gelbe Seiten lead extraction?
| Persona | Pain | Useful CSV outcome |
|---|---|---|
| Market researchers | Local business evidence is scattered across profile pages. | Export category, address, city, rating, review count, website, and source URL for filtering. |
| Newsrooms | Stories about local service access, closures, or directory visibility need documented samples. | Preserve business name, location, contact fields, opening status, profile text, and the checked URL. |
| SEO teams | Local SEO audits need entity and profile-completeness signals across many businesses. | Compare industries, websites, contact availability, descriptions, and review signals in one sheet. |
| Monitoring teams | Known businesses need periodic checks, but manual revisits drift. | Re-run the same URL list and compare opening status, website, phone, email, and profile text. |
| Agencies | Client reports need evidence that can be cleaned, deduped, and attached to a deliverable. | Create a lead-ready CSV before CRM import, enrichment, or manual qualification. |
That is the gelbe seiten scraper by urls problem: defined directory pages in, structured rows out.
Workflow
How the template delivers structured export
The bundled JSON workflow is intentionally direct: Navigate -> Wait for Page Load -> Wait for Element -> Structured Export -> Loop Continue. Navigate contains the Gelbe Seiten URLs. The wait blocks reduce partial-page exports. Structured Export reads the visible page into fixed columns. Loop Continue advances the run.
| Workflow question | Export fields that answer it |
|---|---|
| Which business did we inspect? | titel, branche, lead_url |
| Where is it located? | adresse, plz, standort |
| What contact routes are visible? | e_mail, telefon, fax, website |
| What trust or activity signals appear? | bewertung, anzahl_der_bewertungen, oeffnungsstatus, oeffnungszeiten |
| What context supports review? | ueber_das_unternehmen, lead_url |
Because there is no CSV sample in the bundle, the JSON export is the source of truth. Before a real batch, run URLs you control, open the CSV, and compare key columns against the live page.
Scenarios
Concrete Gelbe Seiten scraper use cases
Research a local market
Build a sample in one city or service category, then export ratings, industries, addresses, websites, and profile text for spreadsheet analysis.
Support newsroom checks
Use the CSV as a working evidence table for local availability or directory visibility stories. Keep screenshots and editorial notes separately.
Audit local SEO profiles
Compare whether businesses expose websites, descriptions, phone numbers, emails, opening hours, and review signals. Missing fields can become audit findings.
Monitor known accounts
Re-run the same approved URL list and compare contact changes, website changes, opening status, and profile descriptions.
Prepare lead qualification
Export rows first, then dedupe, score, and review the businesses before outreach. Treat the CSV as a starting point, not an automatic contact list.
Alternatives
Gelbe Seiten scraper alternative: local CSV vs hosted tools
If you are comparing the best Gelbe Seiten scraper for a real workflow, the right choice depends on custody, scale, and operator control. Hosted scrapers, Apify actors, APIs, browser extensions, and custom scripts can all be valid. The trade-off is where the run happens and who controls the parser.
| Route | Good fit | Trade-off |
|---|---|---|
| UScraper URL template | Supervised batches from known Gelbe Seiten detail URLs where the deliverable is a local CSV. | Best for controlled research and QA, not unattended fleet-scale crawling. |
| Hosted actor or API | Scheduled runs, API delivery, managed retries, and cloud datasets. | Data, logs, and billing live in the vendor workflow. |
| Custom script | Engineering teams that need tests, queues, proxy strategy, and full parser ownership. | Highest flexibility, but also the highest maintenance burden. |
For a gelbe seiten scraper vs apify decision, ask whether your team needs an API-backed cloud job or a local desktop run that an analyst can see and validate. UScraper is strongest when the list is curated, the output is CSV, and the operator should stay close to the browser session.
Guardrails
Compliance and QA before scraping Gelbe Seiten
Read the official Gelbe Seiten robots.txt, terms, and privacy page before running automation. Google Search Central also explains that robots.txt is a way for site owners to manage crawler traffic, not a legal permission system by itself.
Use modest pacing, collect only fields needed for the stated purpose, avoid private or login-only data, and pause on consent, verification, or unexpected redirects. Directory data can still raise privacy, database-rights, outreach, and retention questions.
| QA habit | Why it matters |
|---|---|
| Save the input URLs | Proves which profiles were in scope. |
| Record the run date | Directory pages change, so old exports need context. |
| Test three rows first | Confirms selectors still match the live layout. |
| Inspect blank fields | Optional fields may be absent, hidden, or affected by layout changes. |
| Keep source URLs in every row | Makes later review and correction possible. |
Runbook
A practical runbook for repeatable exports
Approve the URL list, import the template from the UScraper template library, replace the sample URLs, confirm the CSV path, and run a small validation batch. Browse the UScraper blog for related workflows.
FAQ
Gelbe Seiten scraper use-case FAQ
Use it when researchers, newsrooms, SEO teams, agencies, or monitoring teams already have approved /gsbiz/ detail URLs and need a reviewable CSV with business names, contact fields, ratings, websites, descriptions, and source URLs.
Next step
Download the Gelbe Seiten scraper by URLs template
Use the Gelbe Seiten Scraper by URLs template when you have a defined Gelbe Seiten URL list and need a local CSV your team can inspect. Start with a validation run, confirm columns, then expand after the export matches the browser.