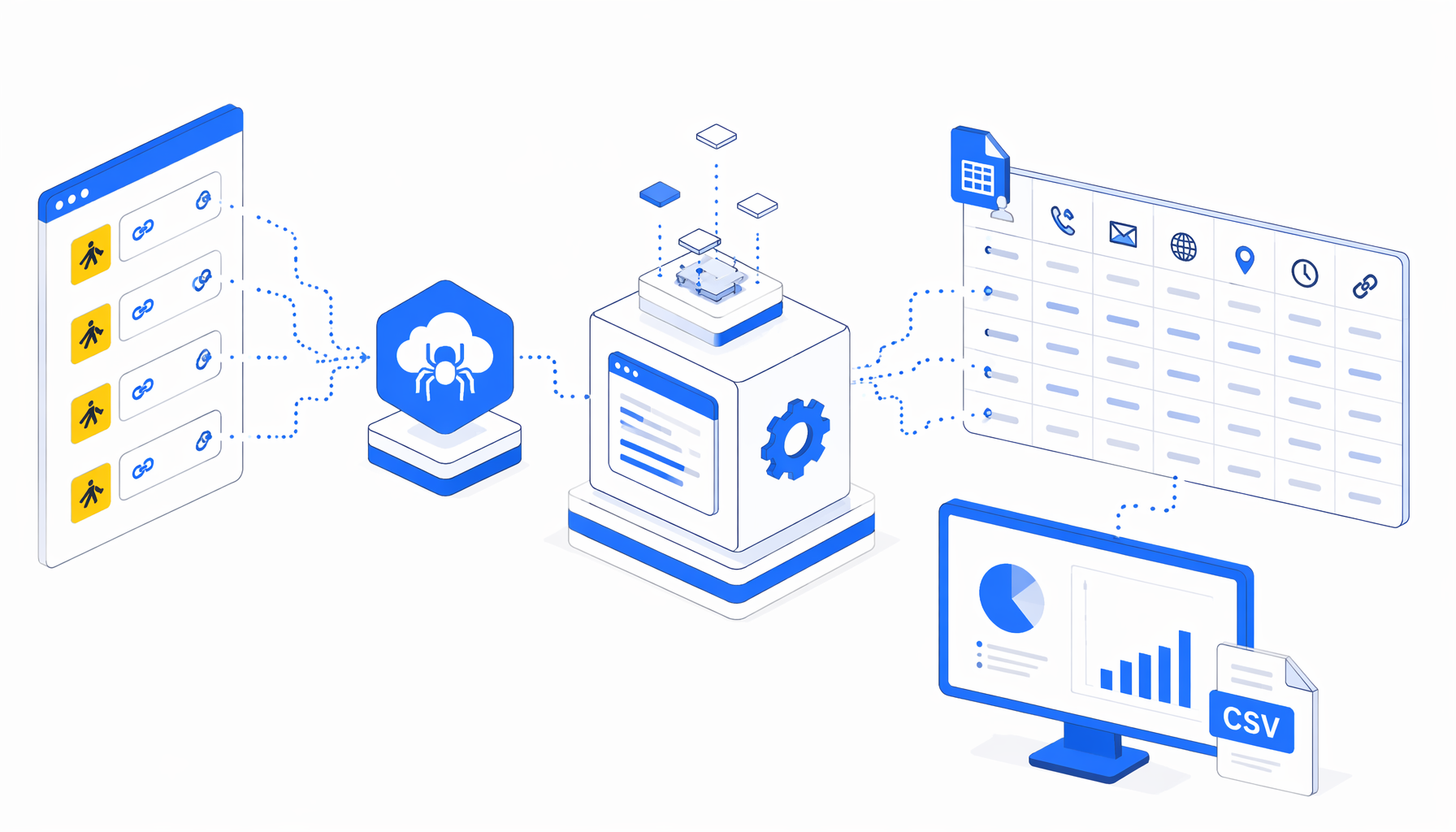
A Gelbe Seiten scraper by URLs is useful when a team already has reviewed business detail links and needs a spreadsheet, not more browser tabs. The Gelbe Seiten Scraper by Detail URLs turns prepared /gsbiz/ pages into a local CSV with business names, contact fields, address, hours, photos, source URLs, and scrape time.
Problem
Why Gelbe Seiten research gets messy fast
Manual German business-directory research looks simple until the sample grows. One analyst copies a phone number. Another saves the website but forgets the address. A newsroom keeps screenshots but loses the source URL. An SEO team collects category names, then has to explain the sample.
That is the pain behind searches like how to scrape Gelbe Seiten, gelbe seiten details scraper, and gelbe seiten scraper by urls. The task is often not broad crawling. The team already has detail-page links from a listing scraper, manual search, client file, or QA queue. The job is turning known pages into consistent rows.
A business-directory export is useful only when every row can be traced back to the source URL, collection time, and review scope that produced it.
Personas
Who uses Gelbe Seiten detail-page exports?
| Persona | Pain | CSV outcome |
|---|---|---|
| Researchers | Browser notes make it hard to compare businesses across cities or categories. | Export names, categories, phone, website, address, opening hours, and source URLs for analysis. |
| Newsrooms | Reporting needs a documented sample, not copied snippets. | Preserve URLs, visible contact fields, category breadcrumbs, and scrape time for verification. |
| SEO teams | Local briefs need real directory language for services, categories, and locations. | Review title, branche, breadcrumb, description, and website fields in one file. |
| Monitoring teams | Rechecking saved pages manually misses removals and changed contact details. | Re-run the same URL list and compare fresh rows against older exports. |
This is where a local desktop app helps. The operator can see the browser, validate a small batch, adjust waits if pages load slowly, and keep the CSV in a known project folder.
Workflow
How the Gelbe Seiten details scraper turns URLs into rows
The template follows a Cloud-by-URLs style workflow through UScraper's desktop automation canvas. The Navigate block holds detail URLs. Each page loads, waits, checks for removed listings, expands common contact controls, then writes one structured row through Structured Export.
Set window size -> Navigate URL list -> Wait for page
-> skip missing listings -> expand visible sections
-> Structured Export -> Loop Continue
The export is wider than a listing-page scrape because detail pages expose richer fields.
| Export field | Why it matters | QA note |
|---|---|---|
titel | Business or practice name used as the row identity. | Compare the first rows against the visible page heading. |
branche, breadcrumb | Category and service signals for grouping. | Category wording can vary by listing type. |
telefonnummer, fax, e_mail, website | Contact fields for review and enrichment. | Blank cells can mean the profile does not publish the field. |
adresse | Street, postal code, and city for NAP checks. | Normalize before CRM or BI imports. |
url, scrapen_zeit | Audit trail for source and run timing. | Keep these columns in every handoff file. |
Examples
Concrete Gelbe Seiten scraper use cases
Build a local research sample
Collect reviewed detail URLs for one city and category, run the template, then filter rows by category, website availability, opening status, and source URL.
Audit client directory listings
Compare exported business names, phone numbers, websites, and addresses against the client's CRM or local SEO sheet to spot stale NAP data.
Support a newsroom check
Use the CSV as an evidence index. Pair rows with screenshots and notes so every claim can be traced to a Gelbe Seiten source page.
Prepare an SEO content brief
Review branch labels, breadcrumbs, descriptions, and business websites to understand local service vocabulary before writing landing pages.
These workflows depend on restraint. A URL-based scraper is strongest after discovery, when the team has already decided which pages belong in the sample. If you still need to discover listings by keyword and location, start with a listing workflow or browse the broader UScraper template library.
Decision
Gelbe Seiten scraper API vs desktop CSV workflow
Searches for gelbe seiten scraper api, best gelbe seiten scraper, or octoparse gelbe seiten alternative usually come from teams choosing between cloud extraction, hosted actors, browser extensions, custom code, and local spreadsheet workflows.
| Route | Best fit | Trade-off |
|---|---|---|
| Hosted scraper API | Recurring cloud jobs, programmatic delivery, and integrations. | Vendor custody, usage pricing, retries, and parser behavior need review. |
| Custom script | Engineering teams that need parser ownership. | Flexible, but maintenance, consent handling, and QA become a software project. |
| UScraper template | Analyst-led URL batches, visible browser review, and local CSV output. | Best for supervised research, not unattended high-volume crawling. |
For many use-case teams, the deciding question is not "which tool can collect the most rows?" It is "which workflow gives us a file we can explain?" A desktop run makes sense when the operator wants to see page state, validate fields early, and hand off a CSV with source links intact.
FAQ
Gelbe Seiten scraper FAQ
Research teams, newsrooms, SEO teams, directory auditors, and monitoring teams use a URL-based Gelbe Seiten details scraper when they already have reviewed business detail URLs and need a consistent CSV export.
Next step
Start with the URL-based Gelbe Seiten template
Use the Gelbe Seiten Scraper by Detail URLs when your team has a controlled list of business detail pages and needs a structured CSV for research, monitoring, local SEO review, or editorial verification. Run a small batch first, verify the output, then expand only after the rows match what you see in the browser. For more scraping workflows, visit the UScraper blog or browse all UScraper templates.