This tutorial shows how to scrape Gelbe Seiten detail URLs into CSV with the Gelbe Seiten Scraper by Detail URLs for UScraper. You will prepare /gsbiz/ URLs, import the workflow, set the export path, run a small validation batch, and fix the most common empty-row issues.
Before you start
Prerequisites for a Gelbe Seiten scraper tutorial
You need UScraper installed as a local desktop app, a short list of current Gelbe Seiten business detail URLs, and a folder where the CSV should be saved. The related template starts with sample https://www.gelbeseiten.de/gsbiz/... URLs. Treat them as placeholders and replace them with fresh detail links from a reviewed listing export, internal research queue, or manually checked search result.
This guide is for supervised business research, directory audits, enrichment checks, and CSV review. It is not a guide to bypass logins, rate limits, CAPTCHA challenges, access controls, or consent walls. Before running automation, check the current Gelbe Seiten robots.txt, the current site terms, and your legal basis for collecting or using contact data.
Technical access is not the same as permission. German business contact data can still create privacy, competition, and outreach compliance obligations, especially if the CSV is used for marketing.
Workflow anatomy
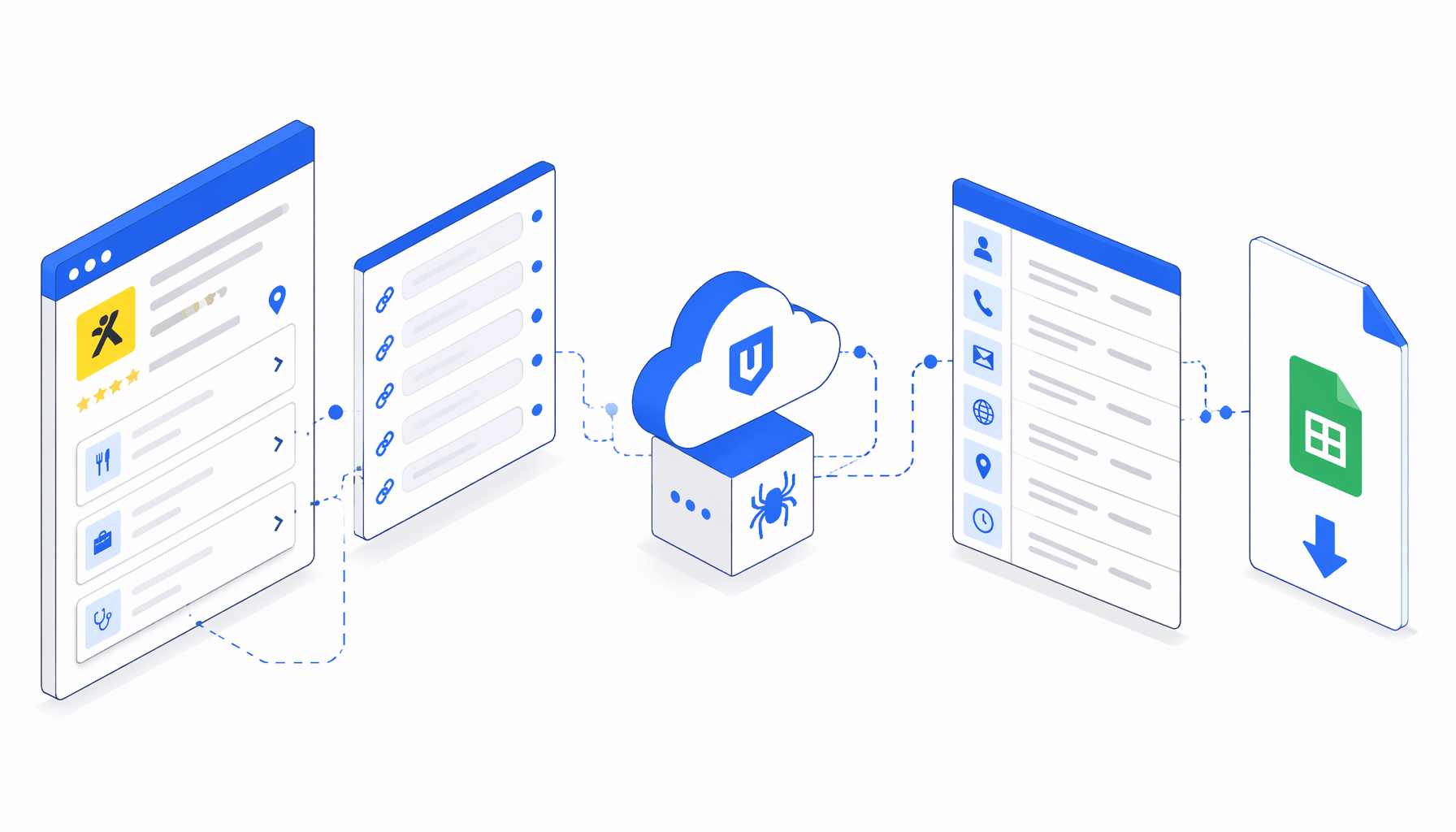
How the Gelbe Seiten details scraper workflow works
The template is modeled around a Cloud-by-URLs pattern: you provide the exact detail URLs, and the workflow focuses on loading and extracting from those pages rather than discovering new search results. That makes it useful when your URL list has already been reviewed and you want a clean Gelbe Seiten to CSV export.
The bundled workflow follows this sequence:
Set browser size
The first block opens a large viewport so desktop page modules, contact controls, and detail sections render consistently.
Navigate through URLs
The Navigate block loops through the supplied Gelbe Seiten detail URLs. Replace the sample list before a real run.
Skip missing pages
A text check looks for the German missing-participant message and continues the loop instead of exporting an empty row.
Expand visible details
JavaScript clicks common consent, email, website, opening-hours, and show-more controls so more page fields are visible.
Export and append
Structured Export reads scoped selectors and JavaScript fallbacks from the page body, writes headers, and appends one row per valid URL.
Use direct /gsbiz/ detail URLs. If you need discovery first, use a listing workflow to collect search-result links, then feed the reviewed detail URLs into this scraper.
Output shape
Export Gelbe Seiten leads to CSV
The JSON export defines the workflow contract. It extracts contact and context fields from each valid detail page, including title, category, phone, fax, email, website, address, opening information, description, payment notes, photo references, breadcrumb, scrape timestamp, and source URL.
| Column | What it captures | Validation tip |
|---|---|---|
titel | Cleaned business, practice, or branch name | Compare against the H1 on the source detail page. |
telefonnummer | Phone from tel: links, schema markup, or text fallback | Spot-check country and area-code formatting. |
e_mail | Email after visible contact sections are expanded | Expect blanks where email is not published. |
website | External business website, excluding common directory and social domains | Confirm redirects before importing into CRM tools. |
adresse | Street, postal code, and city when available | Normalize city names before deduping. |
oeffnungszeiten | Published opening-hours text | Review multiline values in the CSV viewer. |
url | Source Gelbe Seiten detail URL | Keep this column for audit and recheck workflows. |
gelbe_seiten_details_scraper_cloud_final.csvColumn
titel
Cleaned profile title from the detail page.
Column
branche
Business category or branch text when published.
Column
telefonnummer
Telephone value from links, itemprop markup, or text fallback.
Column
e_mail
Email address after contact controls are expanded.
Column
website
External website URL for the business.
Column
adresse
Street, postal code, and city.
Sample rows
2 of many
| titel | branche | telefonnummer | e_mail | website | adresse |
|---|---|---|---|---|---|
| Mueller Zahntechnik GmbH | Zahntechnik | 030 1234567 | Musterstr. 12, 10115 Berlin | ||
| Schneider Elektro Service | Elektriker | 040 9876543 | Hafenweg 8, 20457 Hamburg |
Step by step
How to scrape Gelbe Seiten detail URLs with UScraper
First, download or open the Gelbe Seiten details scraper template from the UScraper template library. Import the JSON into the app and rename the project if you are running separate batches for different cities, categories, or clients.
Next, open the Navigate block and replace the sample URLs. Paste one detail URL per entry. If your source list came from a search-result scraper, remove duplicates before import and keep only direct detail pages. The template is not designed to parse search result pages inside this workflow.
Then check the Structured Export block. The stock filename is gelbe_seiten_details_scraper_cloud_final.csv, and the save folder is configured in the workflow JSON. Change the folder to a project-specific location before running real data. Keep append mode enabled when one batch should create one combined CSV; switch to a fresh filename when testing selector changes.
Run a small test. Open the first few source URLs in the browser view while the workflow runs and confirm that the page loads, the missing-page branch behaves correctly, and contact fields expand before export. After the run, open the CSV and verify five things: row count, non-empty title, source URL, phone or website availability, and whether email blanks are expected.
Finally, scale gradually. If the five-row sample is clean, add a larger URL list. If blanks appear, rerun one failing URL with the browser visible and inspect whether the page actually publishes the field, whether a consent prompt blocked the content, or whether Gelbe Seiten changed a selector.
Gelbe Seiten API vs scraper: which path fits?
A local scraper is useful when your immediate deliverable is a reviewed CSV, your team wants to inspect the browser run, and you have a finite list of URLs. It is also easier to adjust when one visible page field matters more than a fixed API schema.
A Gelbe Seiten API, managed scraping API, or cloud actor can be better when you are building a backend product, need scheduled delivery, want proxy and infrastructure management handled for you, or require a service-level contract. The trade-off is usually less local visibility into each page state and more dependence on the provider's schema, pricing, and queue behavior.
For many teams, the practical split is simple: use UScraper for supervised CSV exports and validation batches; use an API when Gelbe Seiten data becomes a production dependency.
Common issues and fixes
Blank fields usually mean the field was not published, a button did not expand, the page loaded slowly, or the layout changed. Rerun one URL, watch the browser, and confirm the value is visible before Structured Export runs.
Next steps
Download the template and keep the cluster connected
Use the Gelbe Seiten Scraper by Detail URLs when you already have reviewed business detail links and need a CSV. If you need discovery first, browse related directory templates such as Gelbe Seiten Listing Scraper, Das Telefonbuch Lead Scraper, Das Oertliche Lead Scraper, and the full UScraper template library.
For more walkthroughs, check the UScraper blog. Keep each workflow small enough to validate, preserve source URLs in the export, and treat the CSV as a research dataset that still needs review before sales, enrichment, or compliance-sensitive use.