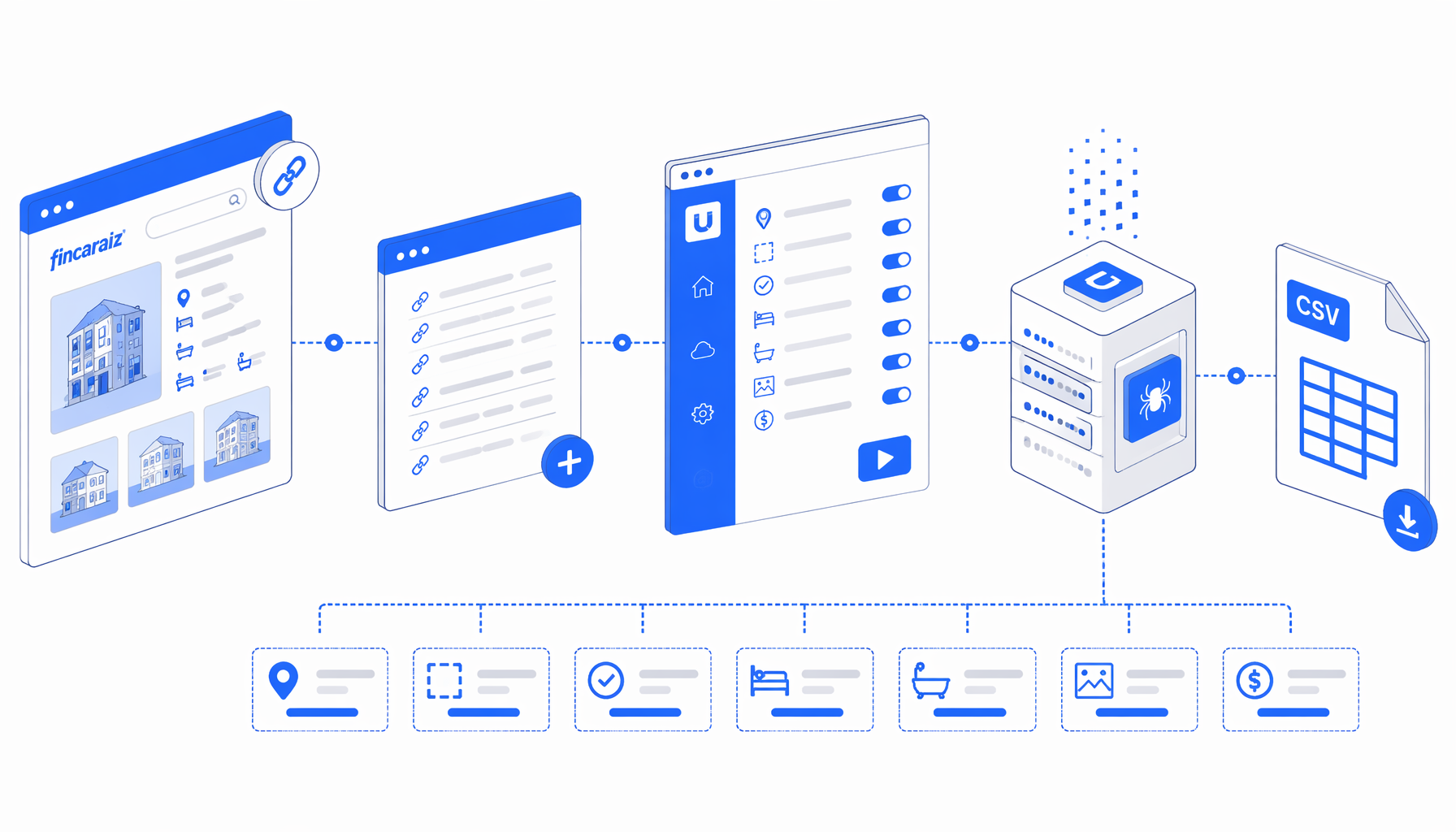
This Fincaraiz scraper tutorial shows how to scrape Finca Raiz property details from known detail-page URLs into CSV with the Fincaraiz Property Scraper for Detail Pages for UScraper. You will import the workflow, replace sample URLs, set the export path, run a validation batch, and check location, area, rooms, bathrooms, status, image, description, and price.
Before you start
Prerequisites for scraping Finca Raiz property details
You need UScraper installed as a local desktop app, two or three Fincaraiz project or property detail URLs for a test run, and a folder where the CSV can be written. Start with known URLs, not a broad search page. This template is designed to enrich detail pages after you already know which properties or projects you want to inspect.
Use the Fincaraiz Property Scraper for Detail Pages as the download path for this guide. The template page carries the current hosted JSON file, import details, column list, and product CTA. This article explains the runbook, waits, and validation checks.
This guide covers visible public detail pages only. It does not cover account dashboards, lead forms, CAPTCHA bypassing, login-only data, or private seller information.
Browser visibility is not the same as reuse permission. If the site shows verification, unavailable pages, login requirements, or access warnings, pause the run and review the collection plan.
Workflow shape
What the Fincaraiz property scraper does
The JSON export is the authoritative workflow definition. In plain English, the flow is:
Set Window Size -> Navigate -> Wait for Page Load
-> Inject JavaScript -> Wait for Element
-> Structured Export -> Loop Continue
Navigate contains the input URL list. Replace the two sample Fincaraiz project URLs with the detail pages you are allowed to process. Wait for Page Load lets the browser settle, Inject JavaScript tries to close common cookie banners, and Wait for Element watches for table tbody tr. Structured Export then reads each table row.
That row behavior matters. A single Fincaraiz project page can include multiple unit types in its "Tipos" table, so one page may produce several CSV rows. Shared fields repeat on each row, while area, rooms, bathrooms, and price vary by unit.
fincaraiz-detalles-scraper.csvColumn
vivienda
Property or project heading.
Column
vivienda_url
Source detail URL.
Column
ubicacion
Primary location text.
Column
imagen_url
Primary image URL.
Column
descripcion
Cleaned description.
Column
estrato
Displayed stratum.
Column
estado
Visible status label.
Column
area_total
Total area.
Column
area_privada
Private area.
Column
habitaciones
Bedroom count.
Column
banos
Bathroom count.
Column
precio
Displayed price.
Runbook
How to scrape Fincaraiz property details to CSV
Import the template
Open Fincaraiz Property Scraper for Detail Pages, download the JSON workflow, and import it into UScraper.
Replace sample URLs
Edit the Navigate block and paste the Fincaraiz project or property detail URLs your team has approved. Keep one URL per source page and remove tracking parameters when possible.
Confirm page access
Open one URL manually in the same browser session. Resolve normal cookie prompts and stop if you see verification, a login wall, or a page you are not permitted to process.
Set the CSV destination
In Structured Export, review fincaraiz-detalles-scraper.csv, headers, append mode, and the local save folder for the project or client.
Run and validate
Run two or three URLs first. Compare exported rows against the browser before adding more detail pages to the Navigate list.
After the first run, open the CSV beside the browser. Each input URL should produce zero rows if the table was absent, one row for one unit type, or multiple rows for several unit types. Clear the old CSV before reruns because append mode preserves test rows.
Output QA
Validate the Fincaraiz CSV before analysis
A Finca Raiz property scraper is only useful when every row is traceable. Use vivienda_url as the audit key, then validate identity, location, table fields, and price.
| Check | What to compare | Why it matters |
|---|---|---|
| Page identity | vivienda, vivienda_url | Confirms the row belongs to the intended page. |
| Location | ubicacion, descripcion | Supports city, neighborhood, and project QA. |
| Unit attributes | area_total, area_privada, habitaciones, banos | Confirms table rows were read correctly. |
| Status and stratum | estado, estrato | Helps filter comparable inventory. |
| Price and media | precio, imagen_url | Keeps unusual rows auditable. |
Common issues usually come from page state or layout drift:
| Symptom | Likely cause | Fix |
|---|---|---|
| No row for a URL | The table did not appear, the page redirected, or a prompt interrupted loading | Open the URL manually and rerun one page. |
| Multiple rows for one URL | The detail page has multiple unit types in the Tipos table | Expected behavior. Group by vivienda_url when analyzing projects. |
| Blank description or location | Labels moved, content loaded late, or the page lacks the field | Confirm the field appears in the browser before changing waits. |
| Image URL is missing | The gallery lazy-loaded late or used a different image path | Inspect the page image and update the selector. |
| Duplicate rows | Append mode wrote several test runs into the same file | Clear the CSV or dedupe by URL, area, rooms, and price. |
Alternatives
UScraper vs Octoparse, Apify, Python, and Fincaraiz APIs
If you searched for Octoparse Fincaraiz alternative, Fincaraiz scraper Python, or Finca Raiz scraper API, choose by custody, scale, and maintenance.
| Approach | Best fit | Trade-off |
|---|---|---|
| UScraper template | Supervised local CSV export from a reviewed detail URL list | You maintain waits and selectors when pages change. |
| Octoparse-style templates | Visual no-code users already managing jobs in that platform | Limits and template behavior depend on the vendor workspace. |
| Apify actors | Cloud scheduling, datasets, and API-driven ingestion | Pricing, run settings, and output schema vary by actor. |
| Python scraper | Engineering-owned pipelines, tests, retries, and storage | Requires code maintenance and monitoring. |
| Approved API route | Contractual access and stable integration for permitted use cases | May require authorization and may not expose every public detail-page field. |
UScraper is strongest when an analyst needs to see the browser, keep the export local, and produce a spreadsheet without scraper code. Hosted tools are stronger when scheduling, API access, and managed infrastructure matter more than local review.
For adjacent workflows, browse the UScraper template library, the UScraper blog, or pair this tutorial with a listing-page scraper to build the input URL list first.
FAQ
Fincaraiz property scraper FAQ
Fincaraiz pages may be publicly viewable, but automated collection can still be limited by site terms, robots rules, copyright, database rights, privacy law, and real-estate regulations. Keep runs modest and get legal review before commercial reuse.
Next step
Download the Fincaraiz property details scraper
Download the current JSON from Fincaraiz Property Scraper for Detail Pages, import it into UScraper, and keep this tutorial open during validation. Start with a short URL list, confirm the CSV rows, then expand after the core fields match the source pages.