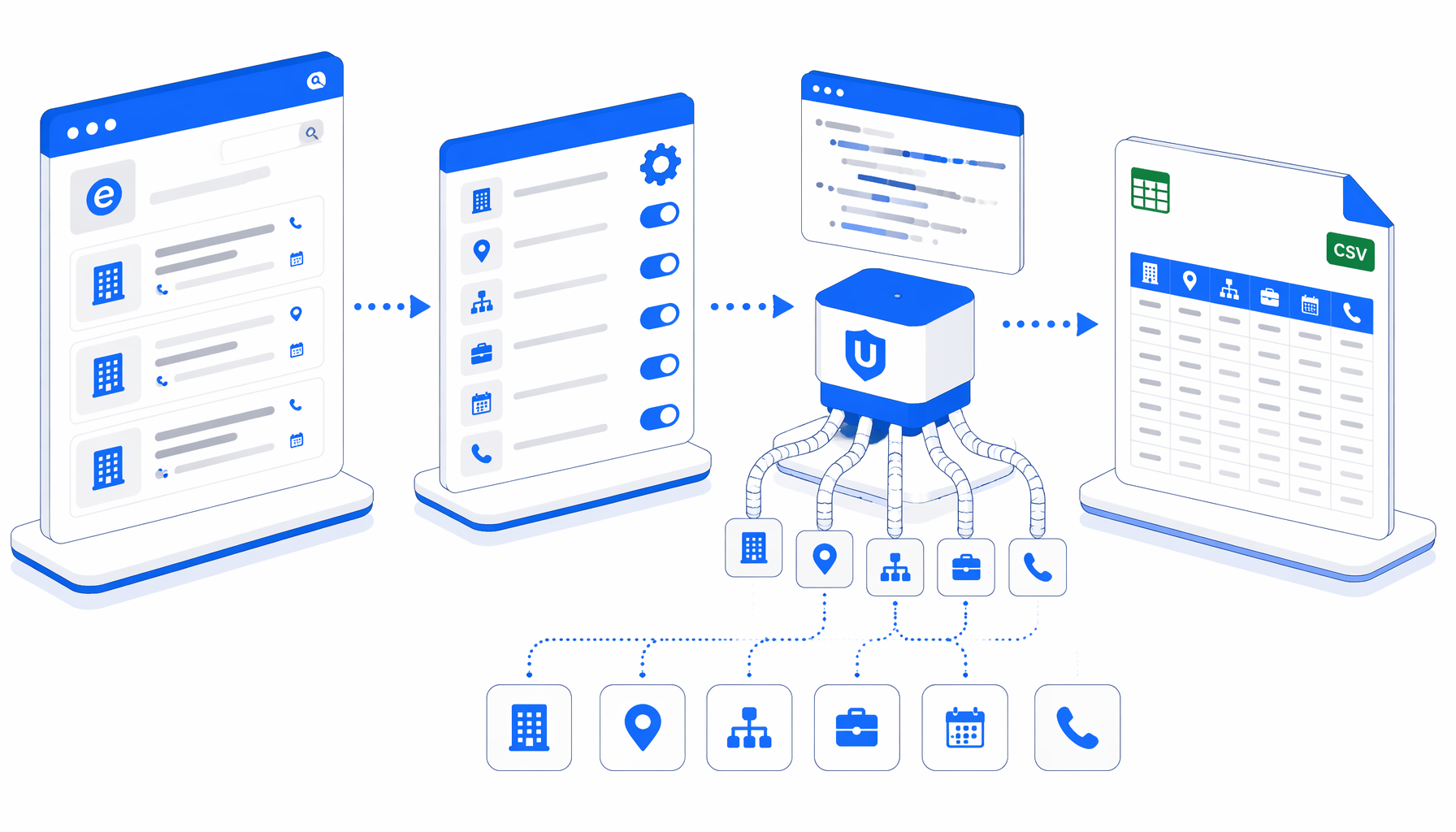
This tutorial shows how to scrape eInforma company details from approved detail-page URLs into CSV with the eInforma Details Scraper for UScraper. You will import the workflow, replace the sample URLs, set the export path, validate the columns, and handle the common issues that show up on Spanish company profile pages.
Before you start
Prerequisites and scope
You need UScraper installed as a local desktop app, a short list of eInforma company detail URLs you are allowed to process, and a local folder for the CSV export. Start with three to five URLs. eInforma pages can vary by access state, company type, visible labels, and verification prompts, so a small validation run is safer than pasting a large list first.
This guide is for supervised research exports from pages you can inspect in a browser. It does not cover login-only records, paid reports, CAPTCHA bypassing, private account screens, or redistribution of licensed company datasets. Review eInforma's Condiciones de Uso before automation. If your use case needs contracted enrichment, stable quotas, or backend integration, compare this workflow with the official API Empresas documentation and the developer portal.
Technical access is not the same thing as permission. Keep batches modest, keep the source URL in every row, and stop when the site shows access controls or manual verification.
Workflow anatomy
What the eInforma details scraper does
The companion JSON is intentionally simple: Navigate -> Wait for Page Load -> Wait for Text -> Sleep -> Structured Export -> Loop Continue. Navigate owns the list of detail-page URLs. The wait blocks confirm that the page has rendered and that the word Identificación appears in the body. Structured Export reads the visible page text and appends the selected fields. Loop Continue advances to the next URL.
The JSON export is the authoritative sample of the workflow definition. There is no bundled CSV sample, so your first dry run is part of setup and quality control.
| CSV column | What it represents | Validation check |
|---|---|---|
detail_url | The exact company detail page opened by the workflow | Open it from the CSV and confirm the row source. |
DENOMINACIÓN | Company name or denomination from the profile heading | Compare against the visible h2 or denomination area. |
DOMICILIO_SOCIAL | Registered address text when exposed | Check that it stops before page, update, or balance sections. |
ANTIGÜEDAD | Company age, normalized where possible | Confirm that years were captured as a number. |
ACTIVIDAD_CNAE | Visible CNAE activity text | Watch for wording changes around CNAE 2009 or 2025 labels. |
FORMA_JURÍDICA | Legal form displayed on the profile | Keep it as text for spreadsheet filtering. |
FECHA_DE_CONSTITUCIÓN | Incorporation date, normalized to YYYY-MM-DD when possible | Spot-check day and month order against the browser. |
TELÉFONOS | Phone values shown in the public profile area | Treat blanks as valid when no phone is visible. |
Runbook
How to scrape eInforma company profiles to CSV
Collect detail URLs
Start from eInforma URLs you are allowed to review. You can collect them manually, from the eInforma search page, from a reviewed list, or from the companion eInforma Listing Scraper.
Replace sample inputs
In the Navigate block, replace the bundled sample URLs with your approved ficha-empresa detail URLs. Keep full URLs because IDs and query parameters identify the target page.
Set the export folder
In Structured Export, confirm einforma-detalles-scraper.csv, headers, append mode, and a project-specific save location.
Run, inspect, then scale
Run one URL first, compare the CSV row against the browser, then let Loop Continue process the remaining inputs only after the columns look correct.
After the first run, sort by detail_url. One detail URL should create one row. If duplicate rows appear, the same URL was supplied twice, the workflow was rerun in append mode, or a previous partial run was resumed after export.
Quality control
Validate the export before using it
Treat validation as part of the scraping workflow. Open the CSV beside the browser and check one row from the beginning, middle, and end of the run. eInforma company pages are structured, but label-based extraction still needs review because public profile pages can change without notice.
| Symptom | Likely cause | Fix |
|---|---|---|
| Empty company name | The page did not finish rendering or no h2 was visible | Extend the wait, handle prompts, and rerun one URL. |
| Blank address | The company profile did not expose DOMICILIO SOCIAL or the page layout changed | Verify the live page and update the label boundary rules. |
| Wrong incorporation date | The date appeared in narrative text instead of the standard label block | Compare against the page and adjust the fallback date parser. |
| Empty phone field | No public phone was shown, or phones loaded behind a different module | Treat blanks as normal unless the browser visibly shows a phone. |
| All fields blank except URL | CAPTCHA, login, paid access, or verification screen interrupted extraction | Stop the run and continue only when your access and use case permit it. |
Alternatives
eInforma scraper vs API vs hosted tools
UScraper is useful when the job is a supervised, no-code CSV export from visible pages and an analyst wants to inspect the browser as the data is collected. The official eInforma API is better for production systems that need credentials, documented endpoints, contracted access, and predictable integration behavior.
Hosted tools occupy a different lane. Octoparse lists no-code eInforma detail and listing templates, while Apify offers an eInforma Spain Company Scraper actor and API examples for NIF/CIF or company-name workflows. Those can be convenient for cloud runs, but they also introduce vendor runtime, vendor pricing, and data custody decisions. Choose based on the work, not the tool category.
| Approach | Best fit | Trade-off |
|---|---|---|
| UScraper local desktop template | Small or recurring CSV exports from reviewed URLs | You maintain selectors when the page changes. |
| Official eInforma API | Contracted enrichment and backend integration | Requires API access, credentials, and implementation work. |
| Hosted scraper actor or template | Cloud scheduling and managed infrastructure | Inputs and outputs pass through a third-party platform. |
| Open-source scraper script | Developer-controlled experiments | You own setup, maintenance, rate control, and compliance review. |
FAQ
eInforma scraping FAQ
Automated collection depends on permission, jurisdiction, data type, access method, and intended use. Review eInforma terms, database rights, access controls, and applicable privacy law before running automation. Do not bypass CAPTCHA, login, paid access, or technical restrictions.
Next step
Download the eInforma details scraper template
When you are ready to run the tutorial, download the JSON from eInforma Details Scraper and keep this article open while you validate the first export. For adjacent company-data workflows, browse the UScraper template library or the UScraper blog.