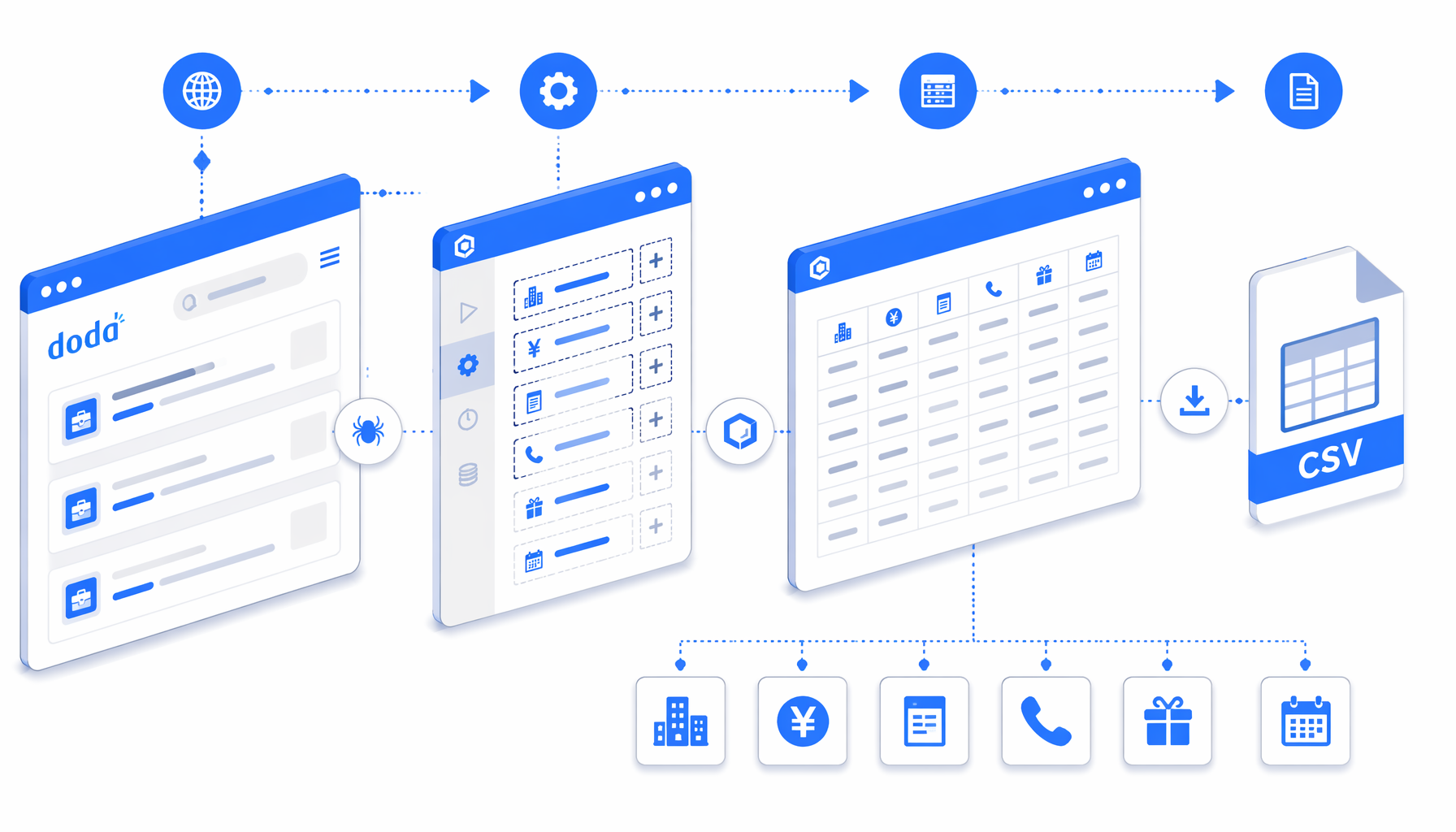
This tutorial shows how to scrape Doda job detail pages into CSV with the Doda Job Detail Scraper for UScraper. You will import the workflow, replace the sample URL, choose a local export path, run a short validation batch, and check company, salary, requirements, benefits, posting dates, and source URL fields before scaling.
Before you start
Prerequisites and policy checks
You need UScraper installed as a local desktop app, the Doda Job Detail Scraper template, and a list of Doda job detail URLs you are allowed to process. This is a detail-page tutorial, not a keyword crawler. If you still need URLs, collect a small reviewed list first, then feed those links into this template.
Review Doda's current terms of use and robots.txt before automation. Robots files and terms can change, and visible web pages are not the same thing as permission for automated collection, storage, redistribution, or commercial use. This guide does not cover login-only data, applicant information, private dashboards, CAPTCHA bypassing, or access-control workarounds.
Treat employment data as operationally sensitive. Keep runs modest, preserve the source URL, document why each export is needed, and ask for legal review before using scraped job content in commercial datasets.
Workflow anatomy
What the Doda job detail scraper does
The JSON export is the authoritative workflow definition. In plain English, the flow is:
Navigate -> Wait for Page Load -> Wait for body
-> Inject JavaScript helpers -> Structured Export -> Loop Continue
Navigate holds the Doda detail URLs. The wait blocks make sure the page has loaded enough for extraction. The JavaScript helper block cleans whitespace, detects ended postings, reads labeled fields, extracts nearby sections, and finds contact, address, homepage, prefecture, city, email, and phone values when they are visible. Structured Export writes the configured columns into doda_job_detail_scraper.csv with headers enabled and append mode on. Loop Continue advances the next URL.
This design matters because individual Doda job detail pages do not need pagination. Your scale lever is the URL list, not a "next page" button. A clean input list produces cleaner output: one detail URL per line, no duplicates, no short links, no stale saved search URLs, and no pages that fail manual review.
| Output group | Columns in the workflow | Why it matters |
|---|---|---|
| Employer identity | 企業名, 事業概要, 所在地, HP | Group roles by company and enrich employer research. |
| Location | 郵便番号, 都道府県, 市町村, 勤務地 | Normalize postings by region, city, and workplace context. |
| Contact fields | 連絡先, 電話番号, メールアドレス | Capture visible recruiting contact details when present. |
| Job detail | 仕事内容, 対象となる方, 雇用形態, 給与 | Compare duties, requirements, employment type, and pay language. |
| Conditions | 待遇_福利厚生, 休日_休暇, 掲載予定期間, 更新日 | Track benefits, holidays, posting windows, and freshness. |
| Audit | ラベル, タグ, URL | Preserve the role label, page tags, ended-posting marker, and source URL. |
Runbook
How to scrape Doda job details to CSV
Replace the sample URL
Open Navigate and replace the sample Doda detail page with active job URLs your team has approved for collection. Keep one URL per input item.
Choose the export folder
In Structured Export, confirm doda_job_detail_scraper.csv, keep headers enabled, leave append mode on for batches, and choose a project-specific local folder.
Run a short validation batch
Start with one to five postings. Watch for ended pages, verification screens, slow loads, or fields that remain blank because the live layout changed.
Review before scaling
Open the CSV beside the browser, compare exported cells against live pages, then expand the URL list only after the first rows look correct.
Do not treat the first export as production data. Sort the CSV by URL, check duplicate links, and confirm Japanese text opens correctly in your spreadsheet tool. If you rerun into the same file, clear old rows or use a dated filename so test output does not mix with the final dataset.
Validation
Validate the Doda CSV export
Validation is where most scraping mistakes get caught. Pick one row from the beginning, middle, and end of the CSV. Open each source URL, compare the employer name, role label, salary, requirements, benefits, location, and update date, then decide whether blank fields are acceptable for that posting type.
| Symptom | Likely cause | Fix |
|---|---|---|
ラベル shows an ended-posting marker | The URL is expired or no longer serves an active job detail page | Remove stale links, refresh the URL source, and rerun only active postings. |
| Company or salary is blank | Doda changed a label, hid a field, or the page did not render the section | Inspect the page, adjust the matching label or wait, and retest one URL. |
| Contact fields are empty | The posting does not expose phone, email, or contact text | Treat contact columns as optional; do not infer missing values from other sources. |
| Rows are duplicated | The same URL was supplied twice or an append run reused an old CSV | Dedupe by URL and start production exports with a clean file. |
| Spreadsheet text looks garbled | The CSV was opened with the wrong encoding | Import as UTF-8, then save a spreadsheet copy for downstream teams. |
Alternatives
Doda scraper alternatives: Python, Octoparse, Apify, and data feeds
The right Doda scraper alternative depends on how much control, infrastructure, and data custody you need. UScraper is strongest when a non-engineering team wants a supervised local CSV and can inspect the browser output before sharing it. A Doda scraper Python project is better when engineers need tests, versioned parsing logic, or database writes. Hosted platforms make sense when scheduling and managed execution matter more than local custody.
| Approach | Best fit | Trade-off |
|---|---|---|
| UScraper template | Reviewed detail URLs, local CSV exports, visible browser QA | You maintain selectors and pacing when Doda changes layout. |
| Python script | Custom parsing, validation tests, enrichment, internal pipelines | Requires code ownership, monitoring, and access-policy review. |
| Octoparse Doda templates | No-code hosted template workflows | Vendor runtime, pricing, and parser behavior are external. |
| Apify Doda actor | API-oriented runs and cloud automation | Better for programmatic jobs, but data passes through hosted infrastructure. |
| JobDataFeeds Doda feed | Purchased job-posting data access | Fit depends on coverage, licensing, freshness, and budget. |
If you are comparing Octoparse vs Apify Doda scraper options, decide first whether the output must stay in a local desktop workflow or whether a hosted actor/API is acceptable. For a small audit-ready CSV from known detail URLs, start with UScraper. For recurring engineering pipelines, evaluate API contracts, run logs, retries, cost, and redistribution rights.
FAQ
Doda job detail scraper FAQ
Doda job pages may be visible in a browser, but automated collection can still be limited by Doda terms, robots guidance, copyright, privacy law, employment-data rules, and local regulations. Review the current rules, use approved URLs, avoid access-control bypassing, and get legal review before commercial use.
Next step
Download the Doda job detail scraper template
Download the JSON from Doda Job Detail Scraper, import it into UScraper, and keep this tutorial open for the first validation pass. For adjacent workflows, browse the UScraper template library or read more tutorials on the UScraper blog.