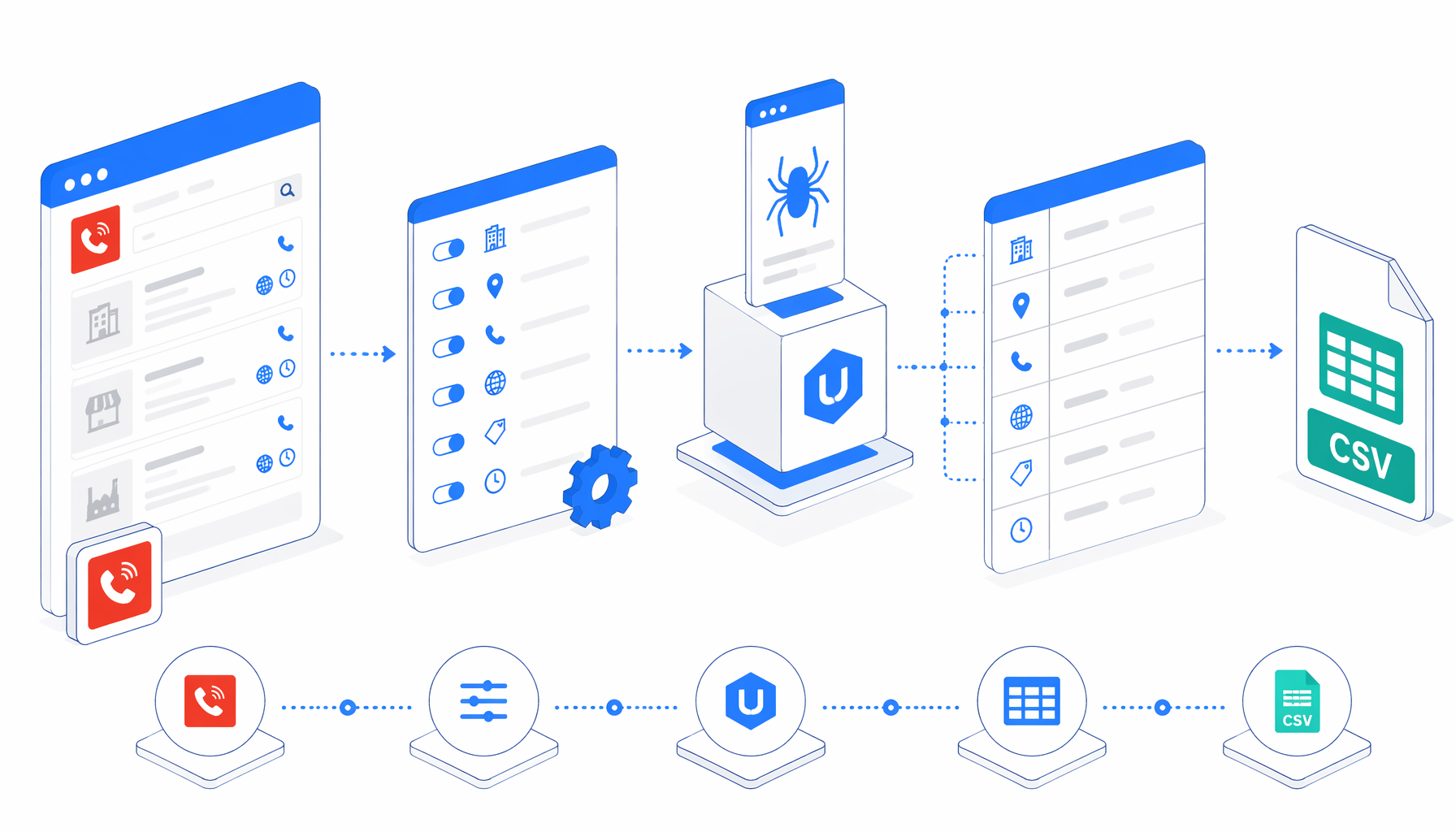
This tutorial shows how to scrape Das Telefonbuch leads into CSV with the Das Telefonbuch Lead Scraper template for UScraper. You will prepare URLs, import the workflow, validate rows, and fix common export issues.
Before you start
Prerequisites, scope, and policy checks
You need UScraper installed as a local desktop app, the Das Telefonbuch lead scraper template, and reviewed detail URLs your team is allowed to process. Start with five to ten records; the first run should prove the CSV shape.
Use the official site manually first. Das Telefonbuch has general directory search, phone directory search, and company search. This template is narrower: it works from known detail pages, so every row has a traceable source URL.
Review the live page, current robots.txt, and privacy policy before automation. Directory listings can include personal data, protected database content, and contact details.
If your objective is sales outreach, document the source URL, purpose, lawful basis, suppression rules, opt-out handling, and retention period before importing rows into a CRM.
Input prep
Build a clean Das Telefonbuch URL list
The workflow expects detail URLs, not search keywords. Run your search in a browser, open matching records, and copy only the pages you plan to review. A clean input list has one region, one category, and a clear owner.
Avoid mixing unrelated searches in the first batch. Combining company detail pages, city searches, and reverse phone lookup pages makes validation harder because each page type can expose different fields.
Workflow anatomy
What the Das Telefonbuch scraper does
The JSON export is the authoritative workflow definition. In plain English, the template does this:
Navigate -> Wait for Page Load -> Inject JavaScript -> Sleep
-> Wait for Element -> Structured Export -> Loop Continue
Navigate contains the URL list. Wait blocks let the page render. JavaScript tries to dismiss consent prompts and reveal phone numbers. Structured Export writes one row, and Loop Continue advances to the next URL.
The workflow is URL-controlled. It does not crawl every result page or bypass account walls, which keeps the run easier to audit.
{
"project": {
"name": "Das Telefonbuch Lead Scraper",
"description": "Scrapes lead data from Das Telefonbuch detail URLs under adresse.dastelefonbuch.de."
},
"blocks": [
{"title": "Navigate", "config": {"urls": ["https://adresse.dastelefonbuch.de/Berlin/example-detail.html"]}},
{
"title": "Structured Export",
"config": {
"fileName": "das-telefonbuch-lead-scraper.csv",
"fileMode": "append",
"columns": ["firma_oder_person", "ort", "unternehmen_url", "...", "oeffnungszeit"]
}
}
]
}
Output map
CSV fields for Das Telefonbuch lead data
No CSV sample was bundled, so validate against the JSON definition and your first live export. Treat blank cells as review signals, not automatic failures.
| CSV column | What it captures | Validation check |
|---|---|---|
firma_oder_person | Category inferred from URL path or visible text | Confirm it matches the listing type. |
ort | City from address fields or URL path | Compare against the page address. |
unternehmen_url | Source detail URL | Use it as the audit trail for every row. |
name_des_unternehmens | Company or person name | Match the visible heading. |
adresse | Street, postal code, and city | Check formatting before CRM import. |
telefonnummer | Phone number when visible or revealed | Expect blanks when no number is exposed. |
offizielle_website | External website link when present | Exclude directory-owned links. |
branche | Industry or category text | Deduplicate categories before analysis. |
oeffnungszeit | Opening-hour or status text | Treat as volatile, because hours can change. |
Runbook
How to scrape Das Telefonbuch leads to CSV
Import the template
Open Das Telefonbuch Lead Scraper, download the JSON, and import it into UScraper.
Replace the sample URLs
In Navigate, replace the Berlin examples with approved adresse.dastelefonbuch.de detail URLs.
Confirm interaction blocks
Keep the consent and phone-reveal JavaScript step for the first run.
Set the export folder
Confirm das-telefonbuch-lead-scraper.csv, headers, append mode, and a project folder.
Run one URL first
Export one record, compare the CSV to the browser, then widen the URL list.
Validation
Validate the export before outreach
Open the CSV beside the source page and inspect rows from the beginning, middle, and end. Dedupe by source URL, phone number, and official website. Tag rows that need manual review.
| Symptom | Likely cause | Fix |
|---|---|---|
| Empty company name | Expected heading did not render | Rerun one URL and increase waits. |
| Blank phone number | No phone is exposed or reveal changed | Check the browser and update the interaction step. |
| Wrong website link | Redirect or internal links appeared first | Exclude directory-owned URLs. |
| Missing industry | Category markup moved or the URL pattern changed | Update the JavaScript column against the live detail page. |
| Duplicate rows | Append mode kept tests or duplicate URLs | Clear the CSV and dedupe inputs. |
Alternatives
UScraper vs Python, Octoparse, Apify, and hosted tools
If you are comparing Das Telefonbuch scraper options, decide where the browser runs and who maintains the workflow.
| Option | Good fit | Trade-off |
|---|---|---|
| UScraper template | Analysts who want local CSV output | You still validate selectors and policy fit. |
| Octoparse template | Hosted no-code scraping teams | Cloud execution and plan limits may matter. |
| Apify actor or Python API | API-driven hosted runs | Billing, maintenance, and data custody shift to the platform. |
| Python or Selenium script | Engineers who need complete control | You maintain browsers, waits, selectors, retries, and packaging. |
For adjacent German directory workflows, browse the UScraper template library or the UScraper blog.
Frequently asked questions
Public pages can still be restricted by site rules, robots directives, database rights, privacy law, direct marketing rules, and reuse context. Review the source, keep runs modest, and get legal review before outreach.