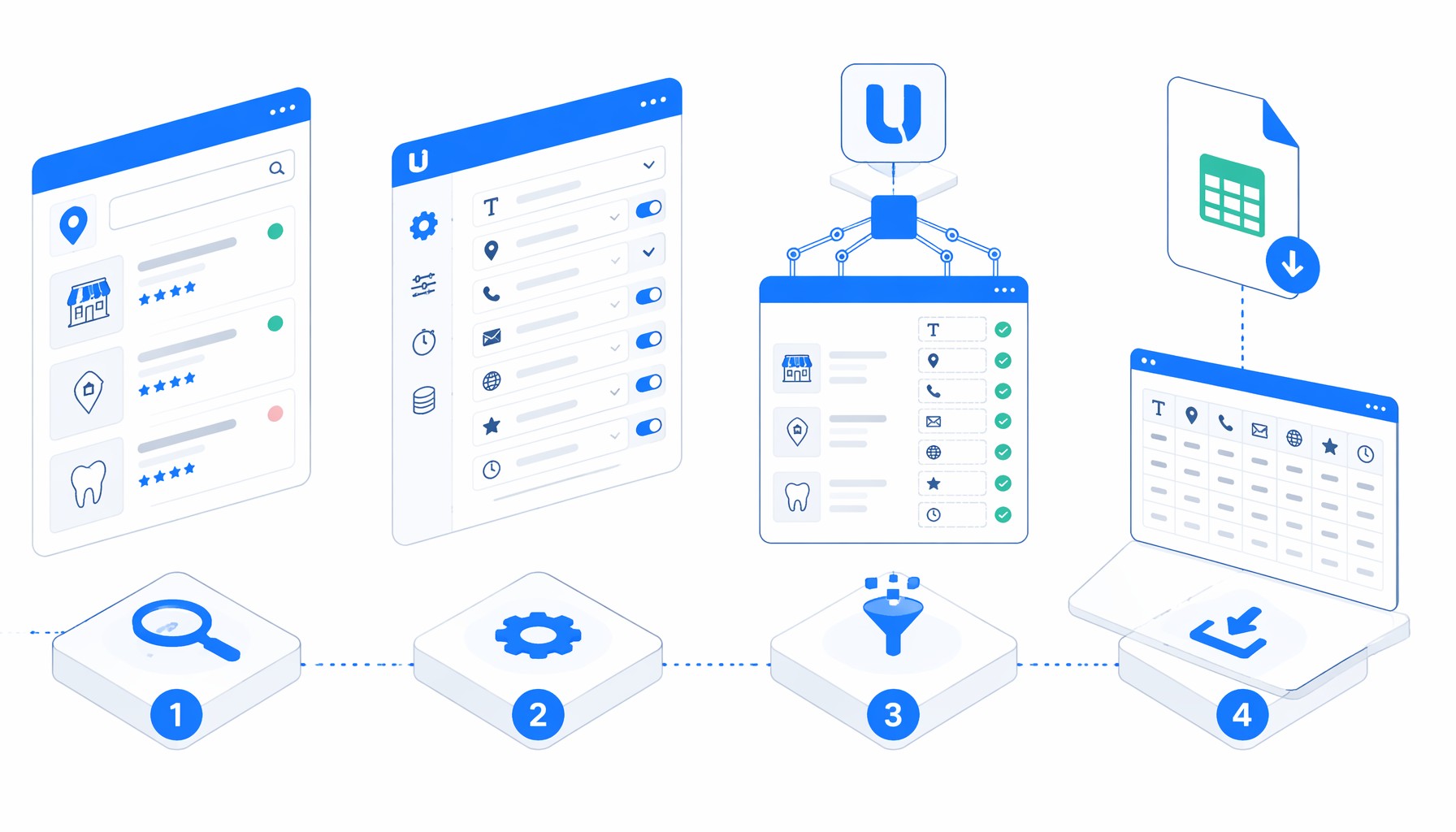
This tutorial shows how to scrape Das Örtliche leads from approved detail URLs into CSV with the Das Örtliche Lead Scraper template for UScraper. You will prepare the source URLs, import the workflow, set the export path, run a small validation batch, and fix the common blank-field issues before scaling.
Before you start
Prerequisites, scope, and policy checks
You need UScraper installed as a local desktop app, a small list of Das Örtliche detail URLs you are allowed to process, and a folder where the CSV can be saved. Start with five to ten records, not a full city scrape. German directory pages can vary by category, listing type, consent state, availability, and whether a business exposes optional contact fields.
Use the official advanced search page to narrow a keyword and location manually before you collect detail URLs. Review the current robots.txt and terms of use before automation. This article is a workflow tutorial, not legal advice; contact data can trigger privacy, database, anti-spam, and commercial-use obligations.
Compliance first: use records you have permission to access, do not bypass access controls, avoid aggressive repeated requests, and keep a note of why each dataset was collected.
Workflow anatomy
What the Das Örtliche lead scraper does
The companion template is intentionally controlled by detail URLs. It does not ask you to crawl every result page from a broad search. Instead, the workflow opens each URL in the Navigate block, waits for the page, pauses briefly for mixed detail content, verifies that a business heading exists, and then writes one structured row.
That flow matters because Das Örtliche detail pages can include optional or mixed contact text. Phone extraction uses JavaScript-backed parsing because the number can appear in tel links, known phone containers, or regular page text near labels such as "Telefon". The workflow also skips unavailable records when the expected heading is missing, so a 404 or expired listing does not become a misleading blank lead.
| Workflow block | Role in the tutorial | What to check |
|---|---|---|
| Navigate | Opens every supplied detail URL | Replace sample URLs with approved records. |
| Wait for Page Load | Lets the page settle | Keep the timeout before changing selectors. |
| Sleep | Adds a short delay for late-rendered content | Use this before adding more complex waits. |
| Element Exists | Confirms a valid detail record | Checks #detail_box1 .addressblock h1. |
| Structured Export | Writes the CSV row | Confirm filename, folder, headers, and append mode. |
| Loop Continue | Advances or skips | Keeps the run moving across valid and invalid URLs. |
Runbook
How to scrape Das Örtliche leads to CSV
Collect approved detail URLs
Search Das Örtliche by keyword and city, open the business detail records you are allowed to process, and save those URLs in a small starter list.
Replace the sample URL list
Open Navigate and paste your detail URLs. Preserve query parameters such as kw, ci, pagePos, and the detail identifier when present.
Set the export path
In Structured Export, confirm das-oertliche-lead-scraper.csv, headers, append mode, and a project-specific save folder.
Run one record, then batch
Run a single URL, compare the row against the browser, then run the rest of the list only after the CSV columns look right.
After the first run, sort the CSV by url. One detail URL should create one row. If a row repeats, the same URL was supplied twice or a run resumed after Structured Export had already appended data.
Output
Das Örtliche to CSV export fields
The JSON export is the authoritative workflow definition. It writes das-oertliche-lead-scraper.csv with headers enabled and append mode on. There was no bundled CSV sample, so treat the fields below as the expected export shape rather than guaranteed values on every listing.
| Column | Source idea | Validation note |
|---|---|---|
keyword | kw URL parameter or search input | Useful for grouping records by campaign. |
location | ci URL parameter or location input | Normalize city names before CRM import. |
page | pagePos URL parameter | Helps trace the original search page. |
url | Current browser URL | Use this as the source audit field. |
name | Detail-page business heading | Required for a usable lead row. |
industry | Visible theme or category link | May need cleanup when location text is included. |
address | Detail address block | Spot-check punctuation and postal code spacing. |
phone | Tel link, phone selector, or parsed page text | Verify numbers from mixed content carefully. |
email | Mailto link | Often blank when the listing does not show email. |
website | External website link | Use for enrichment and deduplication. |
rating | Visible rating phrase | Optional and layout-dependent. |
opening_status | Hours or open-status text | Optional and time-sensitive. |
Validation
Validate the export before using the leads
Open the CSV next to the browser and verify records from the beginning, middle, and end of the run. Do not judge the workflow from row count alone. A lead export can look complete while optional fields are quietly blank because the page did not expose email, the business has no website, or a layout module loaded after the export step.
| Symptom | Likely cause | Fix |
|---|---|---|
Empty name | Page did not reach a valid detail record | Reopen the URL, handle prompts, and rerun one page. |
| Many skipped URLs | Old detail URLs or changed page structure | Refresh the URL list from search results. |
Blank phone | Phone appears outside expected selectors | Check the page text and adjust the JavaScript parsing rule. |
Missing email or website | Listing does not publish that field | Keep it blank; do not infer contact values. |
| Repeated rows | Duplicate URL list or resumed append run | Deduplicate by url before CRM import. |
| Garbled characters | Spreadsheet opened UTF-8 incorrectly | Import the CSV as UTF-8 instead of double-clicking. |
Alternatives
UScraper vs Octoparse, Apify, and other Das Örtliche scrapers
If you are comparing the best Das Örtliche scraper options, decide first whether you need a local, supervised CSV run or managed cloud infrastructure. UScraper is strongest when you want a local desktop workflow, direct browser inspection, a CSV file you can validate immediately, and manual control over the exact detail URLs being processed.
Octoparse-style templates are useful when your team already works inside a hosted no-code scraping suite. Apify actors are useful when you want cloud runs, APIs, datasets, and scheduling around a scraper. Thunderbit, NanoScrape, and similar tools may fit AI-assisted extraction or managed data pipelines. The tradeoff is custody and control: for a careful lead-review batch, a local CSV workflow is easier to inspect; for production-scale scheduling, cloud tooling may be easier to operate.
FAQ
Das Örtliche lead scraper FAQ
Das Örtliche records may be publicly visible, but automated collection can still be limited by site terms, robots guidance, database rights, privacy law, and how exported contact data is reused. Review the current rules, keep runs modest, avoid restricted areas, and get legal review before commercial outreach.
Next step
Download the Das Örtliche lead scraper template
When you are ready to run the tutorial, open Das Örtliche Lead Scraper, import the JSON into UScraper, and keep this guide open for validation. For neighboring workflows, browse all UScraper templates or the UScraper blog for more CSV export tutorials.