This tutorial shows how to scrape Craigslist jobs from saved detail-page URLs into CSV with the Craigslist Job Details Scraper for UScraper. You will import the template, replace the sample URLs, choose an export path, run a small validation batch, and troubleshoot common blank-field or expired-post issues.
Before you start
Prerequisites and policy checks
You need UScraper installed as a local desktop app, the Craigslist Job Details Scraper template, and Craigslist job detail URLs you are allowed to process. The workflow is built for detail pages, not search-result pages.
Review Craigslist's current terms of use, robots.txt, and job-related help pages before automation. Craigslist job posts can contain personal data, copyrighted writing, platform-restricted content, and contact instructions. This tutorial is for controlled research workflows, not bypassing access controls, mass harvesting, or republishing job posts.
Technical access is not the same as permission. Keep runs modest, document why you are collecting the data, and prefer approved or contractual routes when you need redistribution rights.
Workflow anatomy
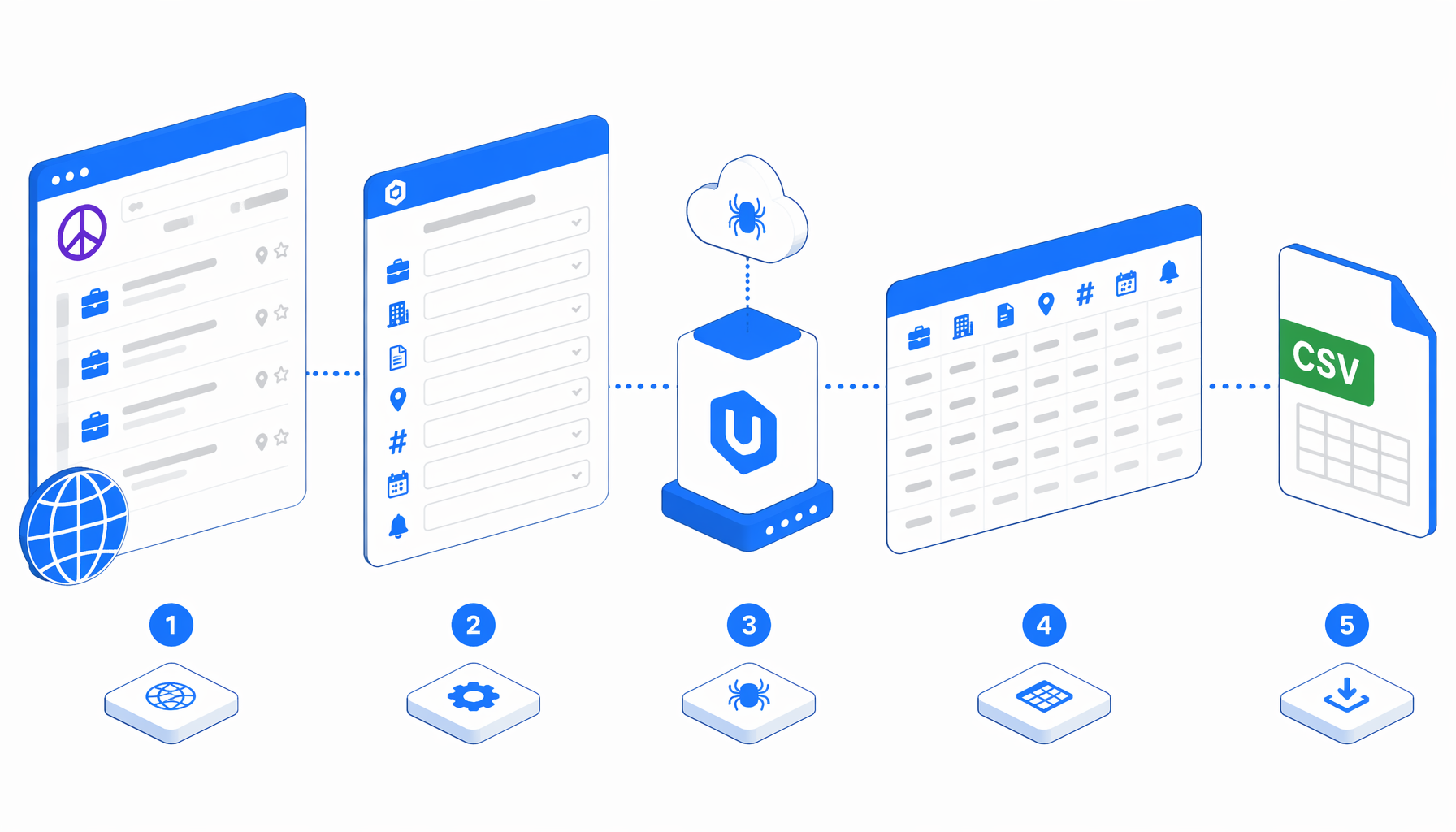
How the Craigslist job details scraper works
The template is intentionally narrow. It does not crawl every Craigslist jobs page or discover new listings on its own. Instead, it accepts job detail URLs, visits each one, and writes a normalized CSV row.
Navigate -> Wait for Page Load -> Wait for body
-> Structured Export -> Loop Continue
The JSON export is the authoritative workflow definition. The most important settings are the multi-URL Navigate block, the body wait, append-mode CSV output, and JavaScript columns that extract both visible text and embedded job metadata.
{
"project": {
"name": "Craigslist Job Details Scraper",
"description": "Scrapes Craigslist job detail pages by a list of job URLs."
},
"flow": [
"Navigate",
"Wait for Page Load",
"Wait for Element: body",
"Structured Export: craigslist-job-details-scraper.csv",
"Loop Continue"
],
"export": {
"fileMode": "append",
"columns": [
"page_url",
"title",
"business_name",
"image_url",
"posting_body",
"location",
"latitude",
"longitude",
"data_accuracy",
"notice",
"post_id",
"listing_date"
]
}
}
Output shape
What the Craigslist job data scraper exports
The output is designed for recruiting research, local labor-market monitoring, job lead review, and spreadsheet cleanup. There is no bundled CSV sample, so treat your first validation run as the sample.
| Field group | Columns to inspect | Why it matters |
|---|---|---|
| Identity | page_url, post_id, notice | Confirms each input URL produced one auditable row. |
| Job content | title, business_name, posting_body, image_url, listing_date | Gives analysts the actual posting context for review. |
| Location | location, latitude, longitude, data_accuracy | Supports city, neighborhood, and map-based filtering when exposed. |
Runbook
How to scrape Craigslist job details to CSV
Import the template
Open Craigslist Job Details Scraper, download the JSON template, and import it into UScraper.
Replace sample URLs
Paste active Craigslist job detail URLs into Navigate. Use a short list first so you can verify selectors, notices, and export path.
Set the export folder
Structured Export writes craigslist-job-details-scraper.csv. Change the save location to your research folder and use a dated filename for repeated studies.
Run a validation batch
Run five URLs, then open the CSV beside the browser. Confirm one row per input URL, clean posting body text, and expected expired-page notices.
Expand gradually
Add more approved URLs only after the first batch looks clean. If Craigslist shows verification, throttling, or blocked access, stop and reassess the workflow.
For job details, the most reliable flow is usually: curate URLs separately, then use this detail-page extractor to produce a stable CSV. If you also need search-page discovery, browse the UScraper template library for adjacent job-board templates.
Validation
Validate the Craigslist jobs CSV
Open the CSV after the first run and compare it against the browser. Check the first row, a middle row, and the final row. Sort by post_id to spot duplicates, then filter notice to review expired, removed, or missing-body pages.
| Symptom | Likely cause | Fix |
|---|---|---|
Blank title and posting_body | The post expired, returned 404, or the page did not expose a posting body | Check notice, open the source URL manually, and replace stale URLs. |
| Repeated rows | The same input URL was included twice or the CSV was not cleared before rerun | Dedupe by page_url or post_id; use a dated output file for each batch. |
| Missing company name | Craigslist did not expose a company field or the employer used free-text body copy | Treat business_name as optional and review the posting body manually. |
| Empty map fields | The post has no map, no exact location, or only a coarse location phrase | Use location when present and keep coordinates optional. |
| Slow or interrupted run | Network delay, challenge page, or too many URLs in one batch | Reduce batch size, increase waits only for valid loads, and avoid aggressive cadence. |
Alternatives
UScraper vs Craigslist scraper alternatives
Python tutorials, cloud actors, browser automation tools, and hosted Craigslist scraper APIs can all be valid. Use cloud tools for scheduled infrastructure, Python for custom engineering pipelines, and manual review for tiny one-off checks. UScraper fits analyst-supervised CSV work where you can see the browser, adjust the workflow, and keep output in a local folder.
For broader context, the UScraper blog covers more no-code scraping tutorials, and the template library lists related workflows.
FAQ
Craigslist job scraping FAQ
Craigslist automation can be limited by terms, robots directives, technical controls, privacy rules, intellectual property rights, and local law. Review the current rules, use lawful inputs, keep runs modest, and get legal review before commercial use.
Next step
Download the Craigslist job details scraper template
Download the JSON from Craigslist Job Details Scraper, import it into UScraper, and keep this guide open for the first validation pass.