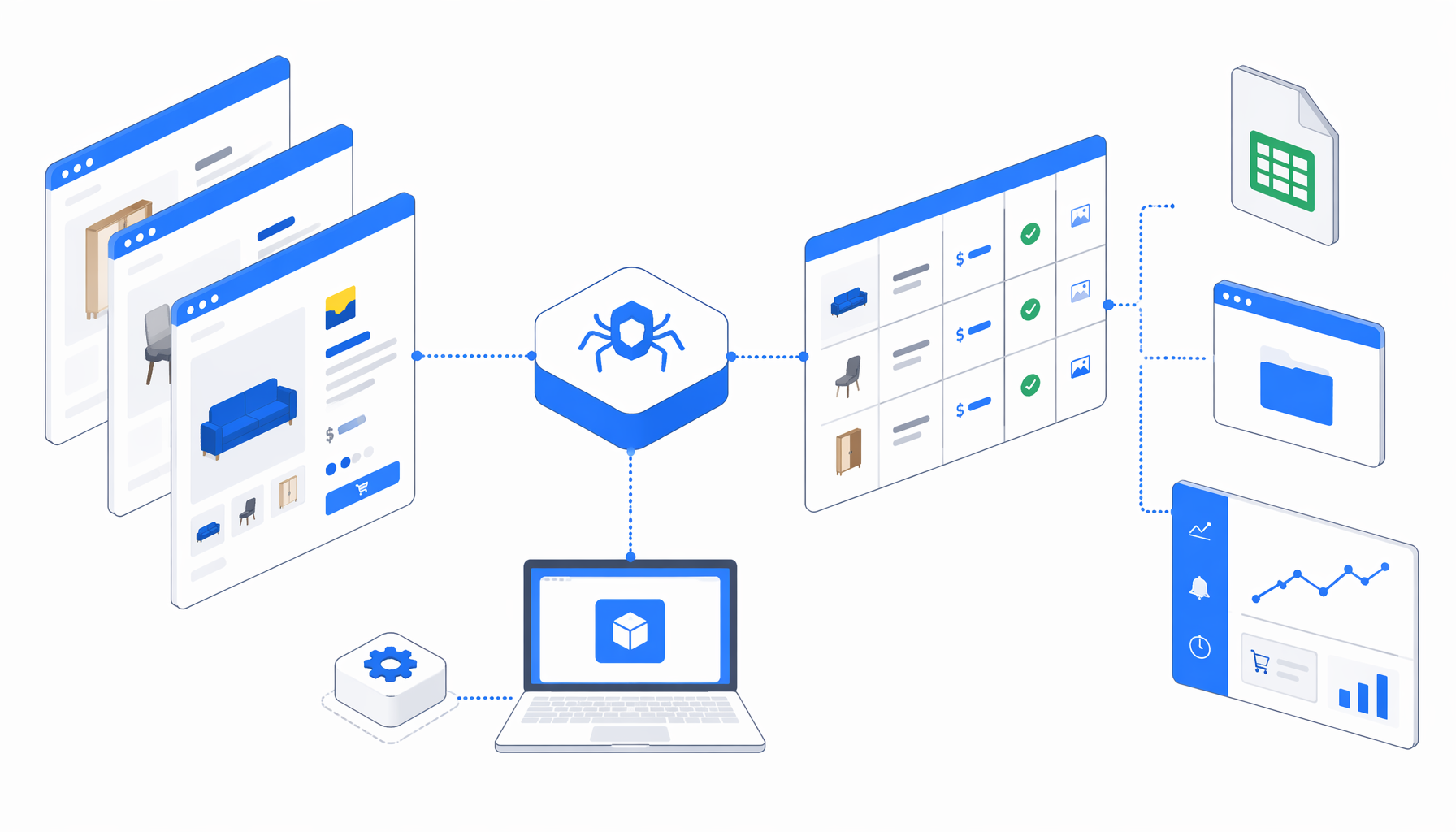
A Coppel product details scraper turns reviewed product URLs into a clean table for research, SEO, catalog QA, or price monitoring. The Coppel Product Details Scraper template exports SKU, model, availability, price fields, discount text, feature notes, and image URLs.
Use-case frame
Why Coppel product data needs a repeatable workflow
Coppel is a major Mexican retail and ecommerce destination, and Coppel has publicly described work on a faster ecommerce platform for Coppel.com and App Coppel as part of its 2030 digital push. Its product pages can show visible price, availability, assortment, feature, and image signals.
The manual workflow is familiar: open product pages, copy the model name, paste the current price, save an image URL, then repeat. It works for five products. It breaks when a newsroom needs a documented sample, an SEO team needs category language, or a pricing analyst needs the same list every week.
A copied price is not a monitoring record unless it includes the product URL, model, availability, collection context, and enough notes to explain blank fields.
Before collecting data, review Coppel's current robots.txt, terms and conditions, privacy notice, and your downstream use case.
Personas
Who uses a Coppel product details scraper?
| Persona | Pain | CSV outcome |
|---|---|---|
| Retail researchers | Coppel assortment checks are scattered across tabs. | Compare SKU, model, price, discount, availability, and image URLs. |
| Newsrooms and analysts | Ecommerce stories need traceable examples. | Keep normalized rows beside reporting notes for review. |
| SEO teams | Category briefs need real product phrasing. | Export model names, attributes, feature notes, and images. |
| Catalog QA teams | Supplier sheets and live pages drift. | Check SKU, model, color, capacity, price state, and images. |
| Price monitoring teams | Weekly checks get noisy by hand. | Re-run the same URL list and compare changes. |
If your workflow also needs UPC, EAN, or a product barcode database match, treat that as separate enrichment. The Coppel URL and visible SKU are useful identifiers, not verified product barcodes.
Workflow
How the template turns Coppel URLs into CSV rows
The bundled JSON workflow is the authoritative definition. It uses a multi-URL loop: Navigate -> Wait for Page Load -> Wait for Element -> Sleep -> Inject JavaScript -> Wait for normalized row -> Structured Export -> Loop Continue.
During template validation, direct automated navigation to Coppel could return HTTP/2 or access-denied responses in some environments. The workflow therefore routes product URLs through a readable endpoint pattern and injects a hidden normalized row for export. When page text is available, it attempts price, availability, and discount fields. When access is blocked, it can still derive identifiers, model text from the URL slug, and likely Coppel CDN image URLs from the product ID.
coppel-detalles-scraper.csvColumn
SKU
Product identifier.
Column
Modelo
Model or title.
Column
Disponibilidad
Visible availability.
Column
Precio
Current price.
Column
Precio_original
Previous or crossed price.
Column
Descuento
Savings text.
Column
Talle
Derived attributes.
Column
Caracteristicas
Feature or access notes.
Column
Imagen1...5
Coppel CDN image URLs.
Scenarios
Five concrete Coppel scraping workflows
Build category snapshots
Export reviewed appliance, electronics, furniture, or apparel URLs, then sort by model, price, discount, availability, and images.
Run price monitoring
Keep the same URL list and compare Precio, Precio_original, Descuento, and Disponibilidad.
Support newsroom checks
Use the CSV as an evidence index, then pair rows with screenshots and editorial verification.
Audit catalog records
Compare live model names, attributes, and image URLs against internal sheets. Treat blanks as QA events.
Alternatives
Coppel scraper vs Apify, Octoparse, and managed tools
Searches like best Coppel web scraper, Octoparse Coppel scraper alternative, and Coppel scraper vs Apify usually ask the same question: cloud scraper, managed provider, custom code, or local desktop app?
Use UScraper when analysts want editable blocks, visible browser QA, and CSV files saved to a chosen folder.
Use UScraper for a supervised CSV from a reviewed list. Use hosted options for high-volume datasets or production APIs.
Governance
QA and compliance before scale
Use Coppel's sitemap only as discovery context. Keep batches modest and stop on access-denied, verification, or unexpected response states.
| Check | Why it matters |
|---|---|
| Confirm URL scope | Use product-detail URLs, not account, checkout, or restricted pages. |
| Validate one row | Compare the CSV against the browser before scaling. |
| Treat blanks as QA events | Blank prices can mean access denial, layout drift, or unreadable text. |
| Keep run notes | Save input URLs, run date, file name, and extractor edits. |
| Review data rights | Decide allowed storage, sharing, enrichment, and commercial use. |
Browse adjacent templates or more articles in the UScraper blog.
FAQ
Coppel product scraping FAQ
Start with approved product detail URLs, run the template, and export one CSV row per page. Validate a small batch first.
Next step
Download the Coppel product details scraper
Use the Coppel Product Details Scraper template when your team has a defined product URL list, a clear research question, and a need for local CSV output. Run a small validation batch first, then expand after the export matches the browser.