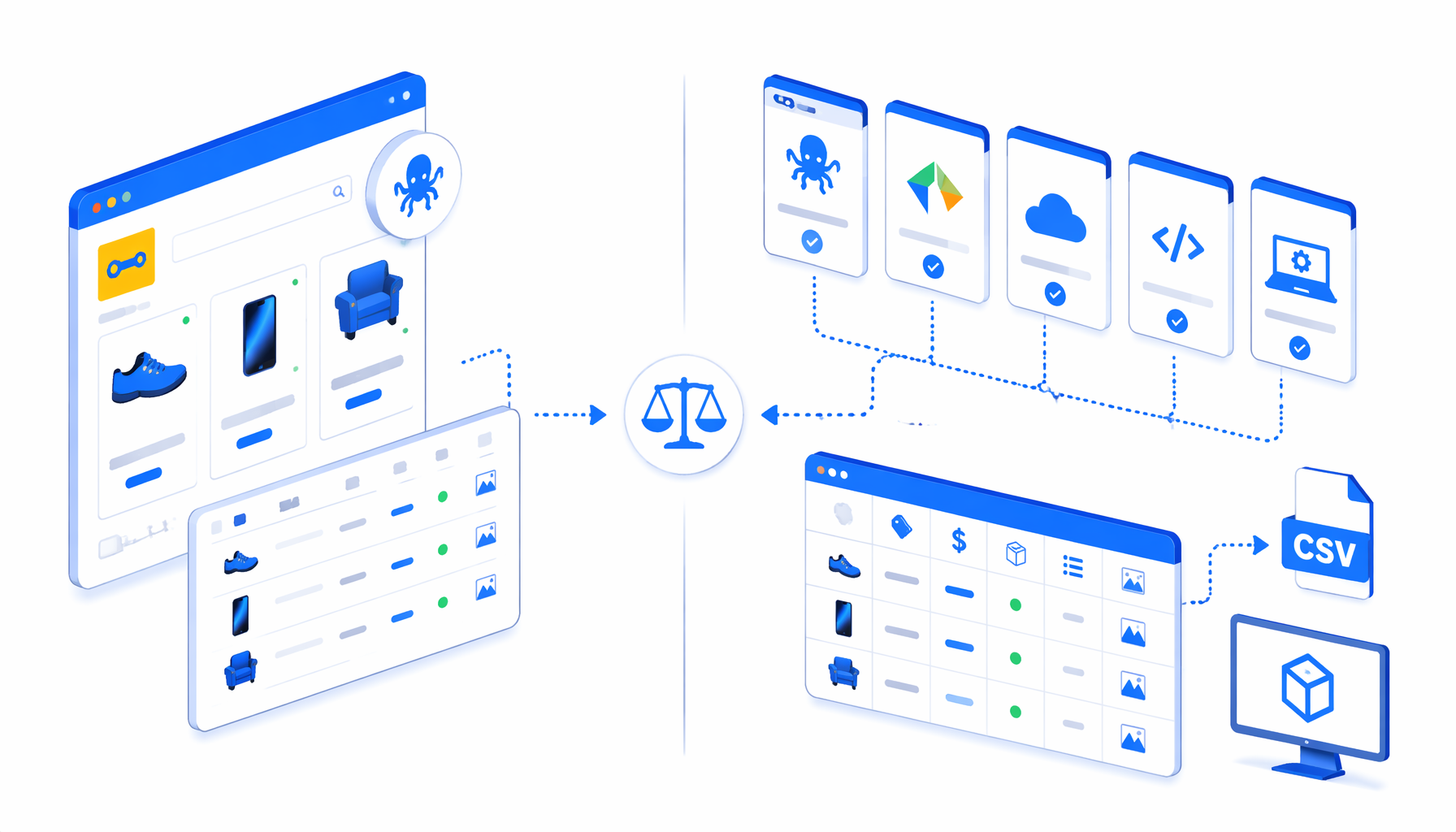
The best Coppel scraper alternative depends less on the logo and more on the workflow: hosted or local, visual or code-based, search listings or product details, CSV or API, one-off analysis or recurring feed. This comparison covers Octoparse, Apify, Thunderbit, Bright Data, managed services, scripts, and UScraper's Coppel Product Details Scraper.
Comparison frame
What Coppel scraper alternatives actually differ on
Most Coppel scraping tools can produce a demo table. The practical differences show up after the demo: where the browser runs, who stores the rows, how pricing is metered, and whether the workflow is inspectable.
For Coppel, there is also a split between listing scrapers and details scrapers. A listing scraper collects product cards from search or category pages. A details scraper starts from product URLs and tries to collect fields from each product page. The UScraper template in this cluster is a Coppel product details scraper, so the fair comparison is against tools that can handle product URL batches, not only broad keyword search.
Searches for how to scrape Coppel usually fall into these lanes:
- No-code SaaS templates such as Octoparse Coppel Detalles Scraper.
- Marketplace actors such as Apify's Coppel Product Search Scraper.
- AI or visual scraping tools such as Thunderbit's Coppel scraper and ParseHub-style builders.
- Managed data providers such as Bright Data's Coppel scraper, Spider, and 123WebData.
- Open-source or custom scripts such as the BoldBastion Coppel product search scraper.
- Local desktop app workflows such as UScraper templates for inspectable CSV exports.
The question is not "which tool can scrape Coppel?" It is "which tool creates rows your team can audit, afford, and maintain for this specific product data extraction job?"
Side-by-side
Coppel product details scraper alternatives compared
| Option | Best fit | Hosting | Code needed | Output shape | Pricing shape | Main trade-off |
|---|---|---|---|---|---|---|
| Octoparse Coppel templates | Hosted no-code templates | Vendor cloud | Low | CSV, Excel, task exports | SaaS plan and task limits | Convenient setup, less local custody |
| Apify Coppel Product Search Scraper | Cloud search collection and APIs | Apify cloud | Low to medium | Dataset, JSON, CSV, API | Platform and actor usage | Strong hosted runs, different from local detail-URL CSV |
| Thunderbit or ScrapeBit-style AI scrapers | Quick browser-assisted extraction | Extension or vendor cloud | Low | Spreadsheet-like tables | Credit, plan, or usage | Fast first result, column stability needs QA |
| Bright Data, Spider, 123WebData, managed services | Recurring feeds and vendor delivery | Vendor infrastructure | Low to medium | API, feed, dataset, files | Usage or service contract | Useful at scale, heavier for small CSV jobs |
| ParseHub-style visual builders | Custom point-and-click projects | Vendor cloud | Low | CSV, JSON, integrations | Tiered SaaS limits | Flexible, but maintenance remains yours |
| Custom Python or JavaScript scripts | Engineering-owned pipelines | Your infrastructure | High | Whatever code writes | Engineering and proxy cost | Maximum control, maximum maintenance |
| UScraper + Coppel Product Details Scraper | Local CSV from known detail URLs | Local desktop app | Low | CSV with 13 columns | Free template; app licensing applies | Best for inspectable local batches |
This is a comparison, not a universal ranking. Daily feeds may justify a managed provider. API pipelines may justify Apify or code. A short product review may only need a visible workflow and coppel-detalles-scraper.csv.
Where UScraper wins
When the local desktop app approach is better
UScraper is strongest when the job is narrow and auditable: you already have product detail URLs, the output needs to be CSV, and the workflow owner wants to see the navigation, waits, normalization, export columns, save folder, and loop behavior.
The Coppel Product Details Scraper exports one row per configured product URL. The bundled workflow follows:
Navigate -> Wait for Page Load -> Wait for Element -> Sleep
-> Inject JavaScript -> Wait for normalized row
-> Structured Export -> Loop Continue
The JSON workflow is the authoritative sample of the export shape. It appends rows to coppel-detalles-scraper.csv with these columns:
| UScraper column | What it captures | Why it matters |
|---|---|---|
SKU, Modelo | Product identifier and cleaned model/title text | Helps match Coppel products to product barcode, catalog, or SKU records. |
Disponibilidad | Visible availability wording when available | Keeps stock checks separate from price checks. |
Precio, Precio_original, Descuento | Current price, second price candidate, and savings text | Supports price monitoring and promotion review. |
Talle, Caracteristicas | Derived size, color, and feature notes | Adds context for catalog QA. |
Imagen1 to Imagen5 | Coppel CDN image URL candidates | Helps merchandising teams verify image coverage. |
Where hosted tools win
When Octoparse, Apify, Bright Data, or scripts make more sense
Choose Octoparse when non-technical users want a hosted visual scraper and SaaS task management. Its listing template can help collect product URLs, and the details template processes product pages.
Choose Apify when engineering wants cloud actors, datasets, API calls, run logs, and search-result scraping. Its Coppel actor focuses on search data such as prices, inventory, sellers, payment plans, and specifications.
Choose Thunderbit, ScrapeBit, or similar AI tools when speed matters more than deterministic workflow ownership. Test whether generated columns stay stable across Coppel categories.
Choose Bright Data, Spider, 123WebData, or another managed provider when vendor-managed delivery, support, and recurring feeds matter more than workflow control.
Choose scripts when developers own the scraper long term. Code gives you parsers, tests, queues, storage, monitoring, and custom fallbacks. The cost is maintenance.
UScraper is the better fit when input URLs, intermediate review, and CSV exports should stay on machines your team administers. Use SaaS or managed providers only after their data handling model is approved.
Policy and QA
Do not skip Coppel policy review
Coppel pages may be visible in a browser, but automated collection still has to respect Coppel's current terms and conditions, robots.txt, privacy rules, copyright, marketplace restrictions, and local law. Avoid private account areas, checkout flows, CAPTCHA, login-only pricing, and unauthorized access controls.
For commercial use, review whether the data will be used internally, redistributed, sold, merged with personal data, or sent to customers. Public visibility does not remove usage limits.
Decision guide
Which Coppel scraping tool should you pick?
Pick UScraper for a supervised product-details batch: import the template, add allowed Coppel product URLs, run a two-URL test, inspect the CSV, then scale after fields match the source pages.
Pick Octoparse for hosted no-code Coppel templates. Pick Apify for cloud actors and API-oriented datasets. Pick Thunderbit or ScrapeBit-style tools for quick AI-assisted extraction. Pick Bright Data, Spider, 123WebData, or managed services when you need vendor-managed delivery. Pick custom scripts when engineering owns the pipeline and accepts maintenance.
Start with the Coppel Product Details Scraper if your target is local CSV. For implementation steps, read the companion Coppel scraper tutorial, browse the template library, or return to the UScraper blog.
FAQ
Coppel scraper alternatives FAQ
It depends on hosting, scale, budget, output format, and maintenance ownership. UScraper is strongest for local desktop app CSV exports from known product detail URLs. Hosted tools are stronger for cloud scheduling, APIs, and managed infrastructure.