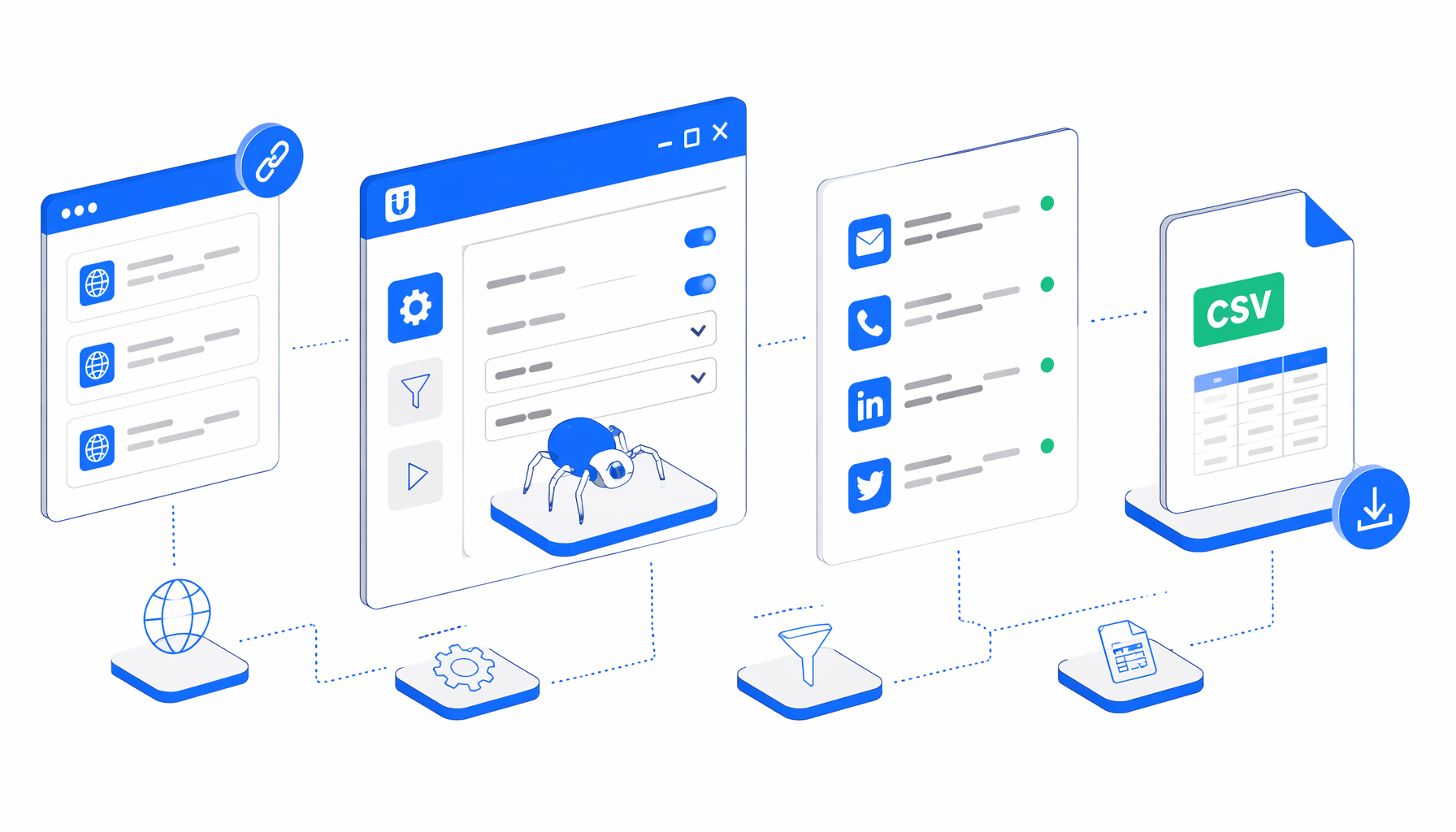
This tutorial shows how to scrape contact details from approved public URLs into CSV with the Contact Details Scraper template for UScraper. You will prepare a clean URL list, import the workflow, confirm the export path, run a short validation batch, and review emails, phone numbers, uncertain phone-like strings, and social profile links before using the file.
Before you start
Prerequisites and contact data rules
You need UScraper installed, the free template JSON, a local folder for exports, and a list of public pages you are allowed to inspect. The workflow is built for supplied URLs, not broad discovery. If your lead generation process starts with search results or directories, dedupe those URLs before the contact pass.
Keep compliance visible from the beginning. Public contact details can still be controlled by website terms, platform policies, privacy law, consent rules, anti-spam law, and robots directives. Do not scrape login-only pages, private dashboards, checkout flows, hidden popups, CAPTCHA-protected pages, or data you cannot manually access. If the CSV will support outreach, enrichment, resale, or model training, get legal review before the run.
Treat this as an operational tutorial, not legal advice. The safest habit is to collect modestly, keep source URLs, validate rows manually, and honor opt-out or deletion requests.
Workflow shape
What the contact details scraper does
The bundled JSON is the authoritative workflow definition:
Navigate through URLs -> Wait for Page Load -> Sleep
-> Inject JavaScript scroll marker -> Sleep -> Wait for body
-> Structured Export -> Loop Continue
The Navigate block contains the target URL list. The JavaScript step stores the starting URL and scrolls without clicking links, which can expose lazy-rendered contact sections while avoiding accidental navigation away from profile pages. Structured Export uses body as the row scope and writes one row per page in append mode.
| Export area | Columns | Validation check |
|---|---|---|
| Source audit | start_url, domain, depth, referrer_url, current_url | Confirm every row can be traced back to the supplied URL and any redirect. |
| Email and phone signals | emails, phones, uncertain_phones | Verify strict phones separately from long number-like strings before outreach. |
| Social profiles | twitter, youtube, facebook, linkedin, instagram, tiktok | Open a few exported links and remove share, login, or unrelated links if a source layout changed. |
Runbook
How to scrape emails, phone numbers, and social links
Prepare approved URLs
Build a clean list of public company pages, contact pages, or public profiles. Remove duplicates, shortened links, private pages, and URLs that only work after a personal account action.
Replace navigate.urls
In the Navigate block, replace the Octoparse X/Twitter, YouTube, and LinkedIn examples with your own URL list. Keep related source types in separate runs when possible.
Confirm the export path
In Structured Export, confirm contact-details-scraper.csv, headers, append mode, and the local save folder for this project.
Run a small batch
Run five URLs and keep the browser visible. Watch for redirects, login prompts, verification pages, slow JavaScript, and pages that publish no contact data.
Validate before scaling
Compare exported emails, phones, uncertain phones, and social links against the source pages. Fix the input list or selectors before adding more URLs.
Output
Contact details CSV columns
The output is intentionally audit-friendly: a reviewer can see which URL produced each contact signal and which values are uncertain.
| Column | Meaning | Review rule |
|---|---|---|
emails | Unique email-like strings found in rendered text or markup | Remove generic, stale, or role addresses your use case should not contact. |
phones | Stricter phone matches using common 10-digit and international formats | Normalize formatting before CRM import. |
uncertain_phones | Longer phone-like strings that may include extensions, IDs, or false positives | Always review manually before use. |
linkedin, instagram, youtube, facebook, twitter, tiktok | Public profile links detected on the current page | Check for share URLs, login URLs, or unrelated social links on heavily templated pages. |
start_url,domain,current_url,emails,phones,uncertain_phones,linkedin,instagram,youtube
https://example.com/contact,example.com,https://example.com/contact,[email protected];+1 415 555 0199,,https://linkedin.com/company/example,https://instagram.com/example,
The scraper gives you a reviewable CSV, not an automatic permission slip to contact every address it finds.
Alternatives
UScraper template vs contact scraper API
Use the UScraper template when you want an inspectable no-code workflow, a visible browser session, local CSV custody, and a finite URL list you can validate manually.
Tools such as ScrapeHero, Bright Data, Apify, and HasData approach contact extraction through hosted apps, actors, or APIs. UScraper is the better fit when the job is supervised extraction from known URLs into a local CSV you can inspect before sharing.
Troubleshooting
Common issues when scraping contact details
| Symptom | Likely cause | Fix |
|---|---|---|
| Email column is blank | The page does not expose email text, uses an image, requires login, or renders late | Open the page manually and decide whether the data is actually public and accessible. |
Phone appears in uncertain_phones | The value matched a loose number pattern but not the stricter phone pattern | Review manually, then normalize accepted values downstream. |
| Social links are wrong | The page contains share links, footer links, or platform redirects | Spot-check links and adjust the selector logic for that source type if needed. |
| Rows repeat | The same URL was supplied twice or append mode reused an old CSV | Dedupe inputs and start production runs with a dated empty file. |
| The page shows verification | Rate limit, login wall, CAPTCHA, or platform protection | Stop the run. Do not bypass access controls. Remove the source or use an approved data route. |
FAQ
Contact details scraper FAQ
Public contact details can still be governed by website terms, robots directives, privacy law, platform rules, and anti-spam laws. Use only pages you are allowed to access, do not bypass login walls or challenges, keep source URLs, and get legal review before outreach or enrichment.
Next step
Download the contact details scraper template
Use Contact Details Scraper as the download path, then keep this tutorial open while you validate your first CSV. For adjacent workflows, browse all UScraper templates or read more tutorials on the UScraper blog.