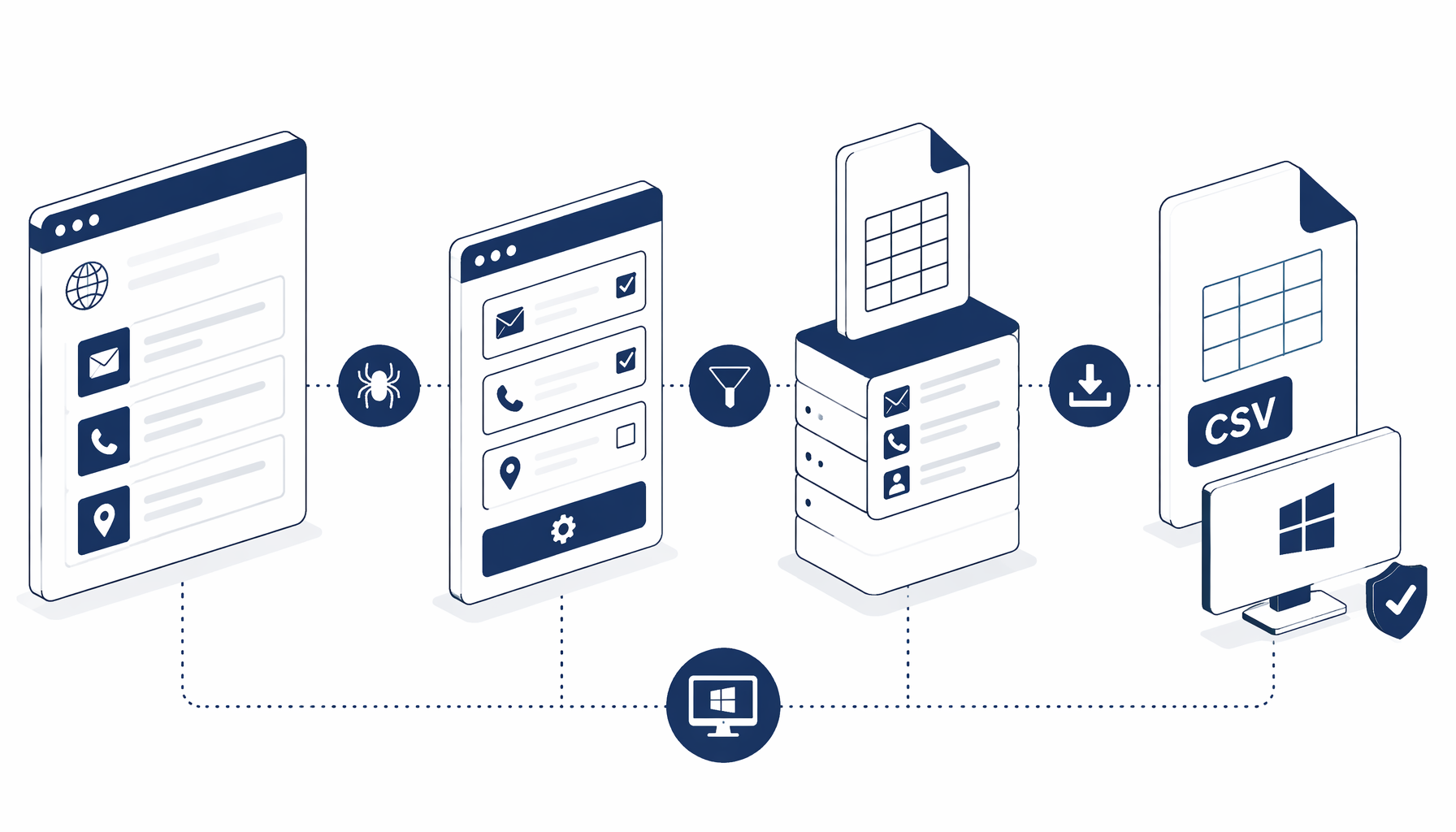
Turning noisy About, Team, or Contact pages into a CSV you can audit is less about heroic regex and more about predictable waits, honest validation, and picking infrastructure that keeps custody on your hardware. This tutorial walks prerequisites, block-by-block flow, and troubleshooting for the Website Contact Details Scraper blueprint—plus where Templates and Blog fit when your pipeline graduates beyond one-off URLs.
Signals on the page
What “contact details” means when you scrape text
Prospect sites rarely volunteer a tidy schema: addresses hide in paragraphs, regional phone formats collide with order IDs, and marketing teams love copy-and-paste-resistant obfuscation. A practical extractor mirrors what automated browsers see after scripts execute—not what static HTML hinted at five seconds earlier.
| Signal | Reliable when… | Watch for… |
|---|---|---|
| Emails | Tokens appear in innerText, mailto anchors, or lightly masked strings | Canvas-rendered glyphs, images-only signatures, bogus example.com fillers |
| Phones | Numeric clusters include separators consistent with geography | UUID fragments, SKU tokens that resemble NANP patterns |
Beyond defaults, skim BeautifulSoup email threads, mailto regex notes, Beautiful Soup docs, and Scrapy when you want code-first parallels.
Pick your extraction lane
Regex scans, anchor parsers, or visual workflows
Import Website Contact Details Scraper from Templates so Navigate → Sleep → Structured Export mirrors the JSON bundle—then tune waits visually instead of redeploying scripts.
Blueprint anatomy
What the JSON workflow actually defines
Four blocks ship by default: Navigate loads the seed URL, Sleep waits for lazy widgets, Structured Export emits Website, Emails, and Phone Numbers into contact-details.csv (headers on, append mode), then End closes the graph—trust the downloadable JSON over screenshots.
Execution
Run Website Contact Details Scraper on Desktop
Fetch JSON from Website Contact Details Scraper—canonical import surface—and align waits with your slowest property before scaling batches.
Download / import the JSON
Open Website Contact Details Scraper inside Templates, save the workflow bundle, and import it into UScraper on Desktop so block IDs and connectors match support screenshots your team expects.
Seed Navigate with your URLs
Drop prospect domains or partner microsites into Navigate—each pass stamps Website via window.location.href for downstream audits.
Tune Sleep against lazy layouts
Extend waits when hero sliders mask contacts; shorten only after DevTools confirms innerText stabilizes.
Validate Structured Export rows
Open contact-details.csv, dedupe email tokens, discard obvious seeds such as noreply@, and spot-check phones against the live DOM so regex optimism does not poison downstream dialers.
Export / archive locally
Use append mode for multi-URL sweeps; rotate filenames when experiments diverge. Keep a one-line memo per list—why it exists and who approved outreach—because compliance questions arrive quarters after the scrape finished.
Alternative stacks
Local desktop bundles versus hosted marketplaces
| Dimension | UScraper blueprint Website Contact Details Scraper | Hosted templates (e.g., Apify actors, Bright Data Easy Scraper quickstart) |
|---|---|---|
| Custody | CSV paths you control on Desktop hardware | Processing often routes through vendor clusters and dashboards |
| Pricing cadence | Align a desktop workflow once vs. perpetual credits | Metered runs ideal for bursty mega-queues |
| Setup | Import JSON, adjust Sleep visually | Tokens, quotas, webhook wiring |
Neither stack deletes legal homework—pick tooling after policy boundaries are mapped; Blog rounds out sibling explainers when campaigns expand beyond contact pages.
Lead-gen reality check: Extraction velocity outran regulations for nobody. Before loading a sheet into outbound tooling, reconcile Outscraper’s email extraction playbook with counsel on consent, suppression lists, and regional cold-contact law—technical success without program discipline is still program risk.
FAQ
Frequently asked questions
Publicly visible contact strings can still be personal data and may be restricted by terms of service, robots.txt, anti-spam laws, and regional privacy rules. Limit collection to pages you may access, avoid authenticated areas without permission, throttle requests, document purpose and retention, and obtain legal advice before outreach or resale. Tooling does not replace compliance planning.
Related links and next steps
- Download JSON from Website Contact Details Scraper and bookmark Templates for SERP, marketplace, or review flows when contacts are only phase one.
- Continue Blog tutorials when governance questions outgrow a single blueprint.
Trace every row to an authorized URL, tune Sleep off measured DOM stability, and your export contact details CSV practice stays defensible—not just fast.