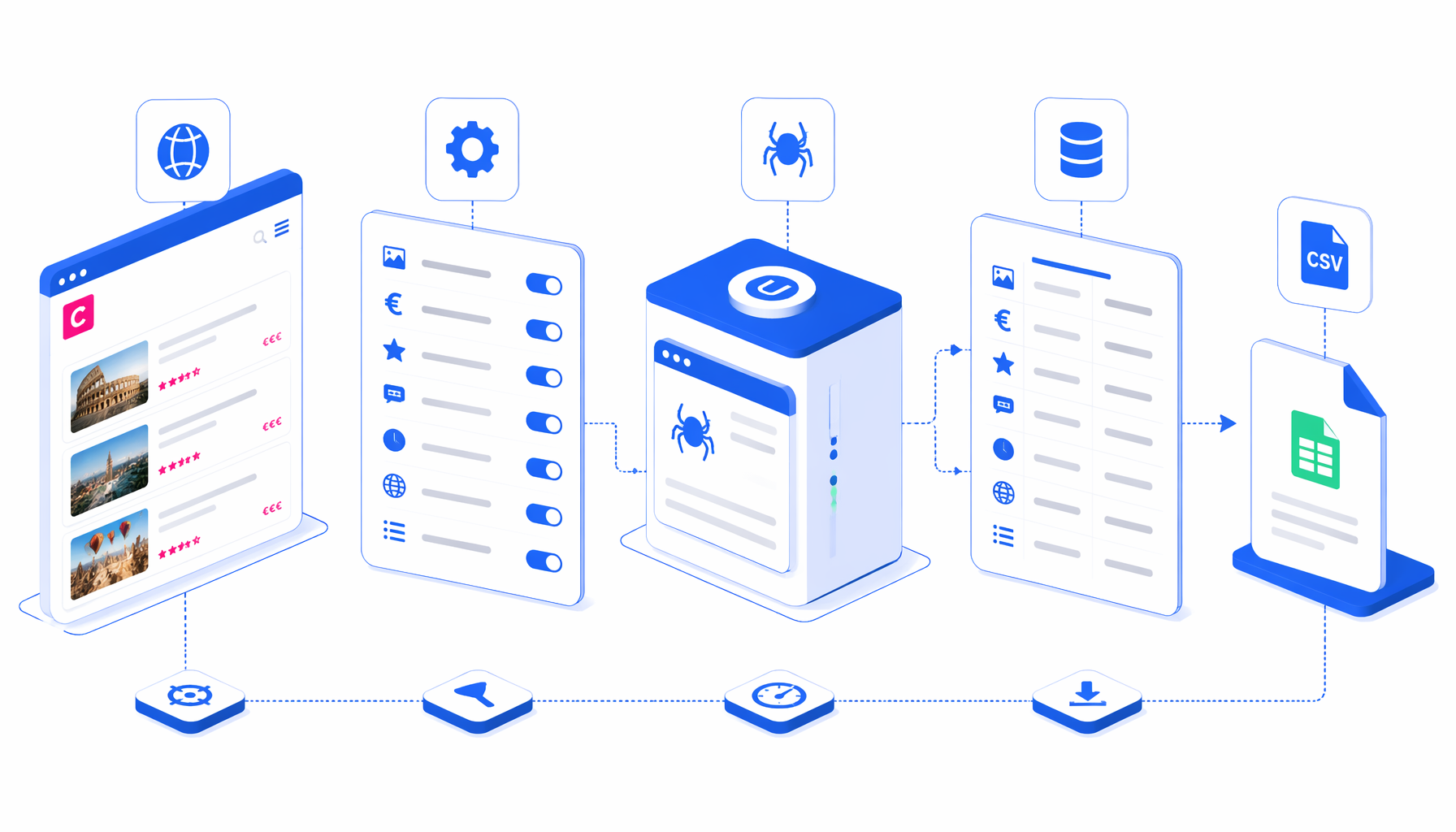
This tutorial shows how to scrape Civitatis activity details into CSV with the Civitatis Details Scraper for UScraper. You will import the workflow, replace the sample URLs, set the export path, run a small batch, and validate the output.
Before you start
Prerequisites, scope, and policy checks
You need UScraper installed as a local desktop app, the companion template JSON, a CSV folder, and a short list of Civitatis activity URLs your team is allowed to process. Start with three to seven URLs. The bundled JSON includes Milan and London examples, but Navigate is meant to be edited.
This guide covers visible activity detail pages only. It does not cover account dashboards, supplier portals, checkout flows, CAPTCHA bypassing, private data, or bulk discovery across the entire site. Before running automation, review Civitatis' current site rules, including robots.txt, and use official channels when your project requires contracted access.
Technical access is not the same as permission. Keep volume modest, avoid access-control bypassing, document your purpose, and get legal review before commercial reuse.
Workflow anatomy
What the Civitatis details scraper does
The JSON export is the authoritative sample of the workflow definition. In plain English, the flow is:
Navigate -> Wait for Page Load -> accept common consent prompt -> Sleep
-> Wait for activity title -> Structured Export -> Loop Continue
The important design choice is that Civitatis detail pages do not expose normal pagination for these fields. Instead, the workflow uses navigate.urls[] as the input list and Loop Continue as the multi-URL iterator. Each URL should create one row, and append mode keeps the batch in one CSV.
| Workflow part | What it does | What to check |
|---|---|---|
| Navigate | Opens the configured activity URLs one by one | Replace sample URLs with approved Civitatis detail pages. |
| Wait blocks | Wait for the page load and the activity title selector | Keep these in place; increase timeouts if pages load slowly. |
| Consent script | Clicks common accept-style consent buttons when visible | If a different prompt appears, handle it manually before trusting output. |
| Structured Export | Writes configured fields to civitatis-details-scraper.csv | Confirm the file path, headers, and append mode. |
| Loop Continue | Advances to the next URL in the list | Stop after one URL during testing, then reconnect for the batch. |
Output
Fields exported from Civitatis activity pages
The export shape comes from the bundled JSON, not from a separate CSV sample. Spanish column names appear because the sample pages use Spanish Civitatis URLs; rename them in Structured Export if you prefer English headers.
| CSV column | Captures | Validation check |
|---|---|---|
Original_URL | The exact activity URL opened during the run | Open a few links from the CSV to confirm source rows. |
Actividad | Activity title from the page heading | Compare against the visible H1. |
puntuacion and opiniones | Rating and review-count text when exposed | Expect blanks if the module is absent or rendered differently. |
Precio | Visible price text from the page price module | Recheck availability and region if price is missing. |
imagen1, imagen2, imagen3 | First three image URLs from page metadata | Treat images as references; verify rights before reuse. |
descripcion | Cleaned meta description text | Compare one sample against the browser page. |
duracion, Idioma | Duration and language sections | These depend on page language and heading labels. |
Incluido, No_incluido | Included and not-included items | Review line breaks before sending the CSV to downstream tools. |
civitatis-details-scraper.csvColumn
Original_URL
The source Civitatis activity detail URL.
Column
Actividad
Activity name from the product page heading.
Column
Precio
Visible price or fallback price text.
Column
descripcion
Cleaned page description.
Column
Incluido
Included items from the activity detail page.
Runbook
How to scrape Civitatis activity details to CSV
Import the template
Open Civitatis Details Scraper, download the workflow JSON, and import it into UScraper.
Replace the URL list
Edit Navigate and paste the Civitatis activity detail URLs you have approved. Keep language and destination paths intact because they affect labels and prices.
Confirm waits and prompts
Keep the page-load wait, short sleep, and visible activity-title check. If a consent or verification screen appears, handle it before trusting the row.
Set the export folder
In Structured Export, confirm civitatis-details-scraper.csv, headers, append mode, and a project-specific save folder.
Run one URL, then scale
Run one activity, compare the CSV against the browser, then allow Loop Continue to process the rest of the URL list.
After the first run, sort by Original_URL. One detail URL should create one row. If rows repeat, the same URL was supplied twice or an earlier test run was appended. Use dated filenames for production exports.
Validation
Validate the Civitatis CSV export
Open the CSV beside the browser after the first page. Check one row from the beginning, middle, and end of the run. Treat a row as clean only after the URL, activity name, price, rating, description, duration, language, and inclusion fields match the page.
| Symptom | Likely cause | Fix |
|---|---|---|
| Zero rows exported | The product article selector never appeared | Confirm the page loaded, handle prompts, and extend the wait. |
Blank Precio | Price module was hidden, delayed, or unavailable for that page | Rerun one URL after the page fully renders and confirm the visible price. |
Empty Incluido | The heading label changed or the section was absent | Inspect the page language and update the JavaScript heading match. |
| Broken image URLs | Civitatis changed metadata or returned fewer images | Keep image columns optional and validate only when your use case needs them. |
| Repeated rows | Append mode wrote a test run into the same file | Clear the CSV or use a new dated filename before rerunning. |
Alternatives
Civitatis API vs scraper tools
A Civitatis scraper tutorial is useful for supervised research: collect a small set of visible activity pages, review the browser output, and export a spreadsheet. The UScraper template fits that path because the workflow is local, editable, and easy to audit row by row.
The Civitatis API is the better path when you are building an affiliate, supplier, booking, or marketplace integration. APIs are designed for contracts, stable schemas, availability workflows, and support expectations that a page scraper cannot provide.
Hosted scraper tools and data providers can help when you need managed infrastructure, scheduling, or external delivery. The trade-off is custody and cost: data passes through another vendor, pricing is often usage-based, and debugging depends on their platform. If you are comparing the best Civitatis scraper tools, decide first whether you need a local research CSV or an approved production integration.
FAQ
Frequently asked questions
Civitatis pages may be publicly visible, but automated collection can still be limited by Civitatis terms, robots rules, supplier rights, privacy law, and local regulations. Review the current rules, keep runs modest, avoid bypassing access controls or CAPTCHA checks, and get legal review before commercial reuse.
Next step
Download the Civitatis scraper template
Use this tutorial as the operating runbook and the Civitatis Details Scraper template as the download path. For more travel and research workflows, browse the UScraper template library or return to the blog for related scraper tutorials.