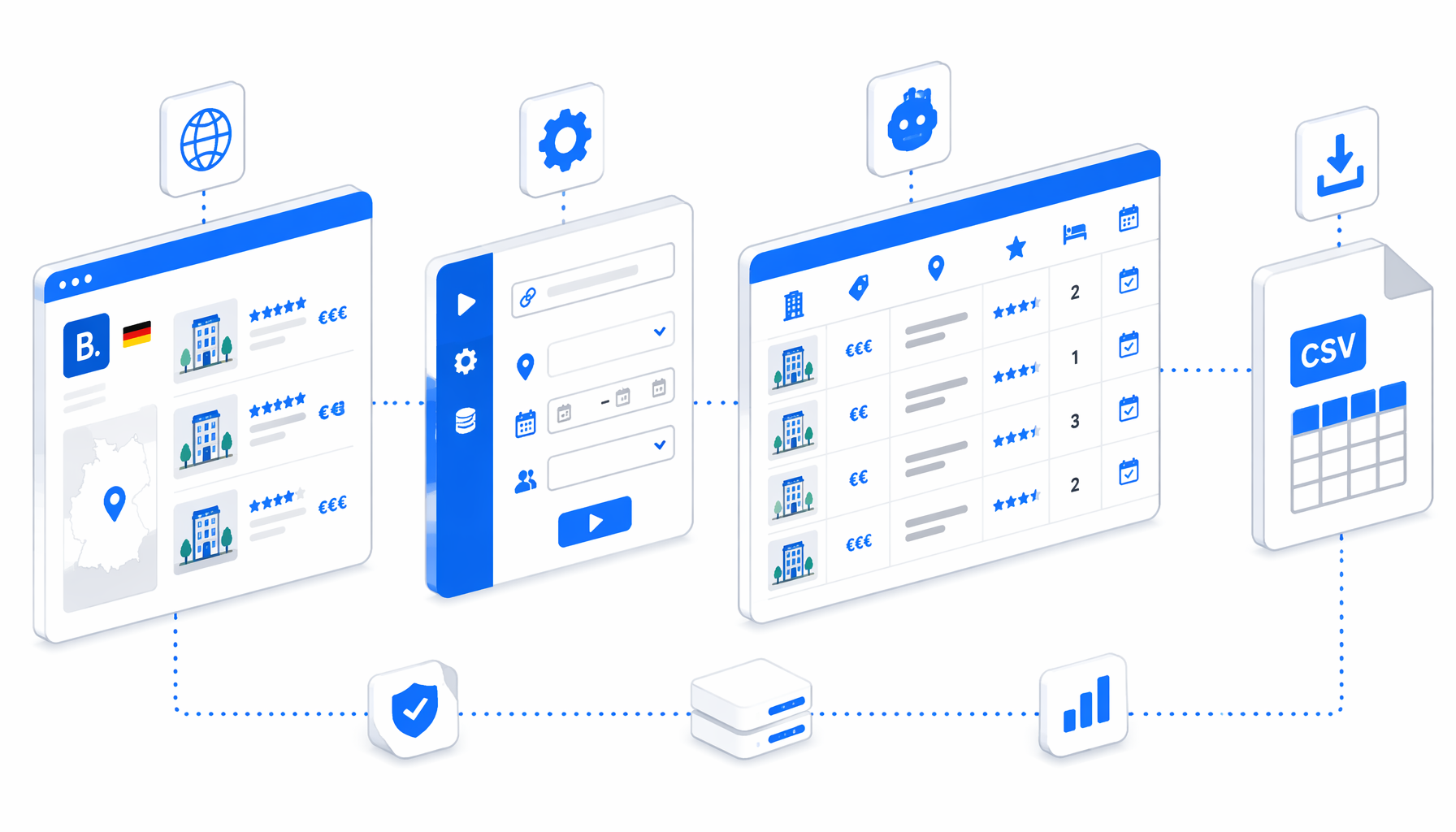
This tutorial shows how to scrape Booking.com Germany hotel listings into CSV with the Booking.com Hotel Listing Scraper for Germany template for UScraper. You will import the workflow, replace the sample hotel URLs, set the export path, run one validation pass, and inspect the rows before scaling.
Before you start
Prerequisites, scope, and policy checks
You need UScraper installed as a local desktop app, the Booking.com Germany hotel scraper template, and a small list of Booking.com hotel detail URLs you are allowed to process. Start with three to five URLs from the same locale and date context. Booking.com can vary price, language, room availability, review labels, and currency by session.
This guide covers supervised exports from visible hotel pages, not account dashboards, partner portals, checkout flows, private messages, CAPTCHA bypassing, or login-only data. Review Booking.com's Terms of Use and robots.txt before automation. If you need contractual access for a travel product, compare this workflow with the Booking.com developer portal and Demand API documentation.
Technical access is not permission. Keep runs modest, avoid defeating access controls, collect only fields you need, and document why the dataset is being collected.
Input prep
Build a clean Booking.com Germany URL list
The quality of the CSV starts with the URL list. Use Booking.com in a normal browser session, choose the Germany destination, dates, adults, rooms, language, currency, and sort order, then open the hotel detail pages you actually want to analyze. The public Germany hotels page can be a starting point for discovery, but the scraper should run against specific hotel detail URLs, not an open-ended country crawl.
Copy the final hotel URLs after the page reflects the exact search context. In the sample JSON, the URLs include parameters such as checkin, checkout, dest_id, dest_type, group_adults, no_rooms, hpos, hapos, matching_block_id, and sr_pri_blocks. You do not need every parameter for every project, but you should avoid stripping them blindly. They are often the only record of the stay assumptions that produced a visible price, search rank, or room block.
Before importing a long list, create a small control set:
- One hotel where price and room type are clearly visible.
- One hotel with a strong review score and review count.
- One hotel from a different city or region inside Germany.
- One URL copied from the exact date and occupancy context your project needs.
Run those first. If the control rows look right, the wider batch has a much better chance of producing a clean Booking.com hotel data export.
Workflow anatomy
What the Booking.com Germany scraper does
The workflow definition is compact:
Set Window Size -> Navigate -> Wait for Page Load
-> Wait for Element -> Sleep -> Structured Export -> Loop Continue
The Navigate block holds the hotel URL list. Each URL should preserve the query parameters that matter to your analysis, especially check-in, checkout, adults, rooms, search-result position, locale, and any selected room block. The wait blocks give Booking.com time to render the hotel title, room modules, and price text. Structured Export writes one CSV row from the current page, and Loop Continue advances to the next supplied URL.
The template is a booking scraper Python alternative for analysts who need a no-code CSV rather than a maintained crawler. It does not pretend Booking.com pages are stable. The value is that the block graph, waits, export filename, and selectors are visible inside UScraper, so you can test and revise the workflow when the page changes.
Output map
CSV fields for Booking.com hotel data
No CSV sample was bundled with this workflow, so the export shape below comes from the JSON definition. Treat it as the contract for your validation pass.
| CSV column | What it captures | Validation check |
|---|---|---|
standort | Region, city, or district from Booking.com location links or visible text | Compare against the property page and destination context. |
suchergebnisse | Search-result position from hpos or hapos URL parameters | Confirm the original URL includes rank parameters. |
titel | Hotel title from metadata, headings, or Booking.com title modules | Match the row to the visible hotel name. |
hotel_url | Current page URL | Use it for reruns, dedupe, and audit. |
details | Stay length and adult count inferred from URL dates and guests | Confirm check-in and checkout were preserved. |
preis | Visible price text or parsed price parameter | Expect blanks for unavailable, hidden, or changed price modules. |
adresse | Visible address or Germany postal-code line | Check a few rows manually because address modules vary. |
kundenbewertung | Numeric review score | Compare against the score badge. |
anzahl_der_bewertungen | Review count | Watch comma, period, and language formatting. |
bewertungsgrad | Star grade such as 3 von 5 | Treat as optional when Booking.com does not expose a grade. |
zimmer_typ | Selected room, suite, dormitory, or apartment label | Preserve the selected room block in the source URL. |
zimmer_typ_details | Longer room table text | Trim or clean this column before reporting. |
zimmer_platz | Availability note such as rooms left | Validate because urgency messages change quickly. |
Runbook
How to scrape Booking.com Germany hotel pages to CSV
Import the template
Open Booking.com Hotel Listing Scraper for Germany, download the workflow JSON, and import it into UScraper.
Replace the sample URLs
Paste your approved Booking.com Germany hotel URLs into Navigate. Keep check-in, checkout, guest, room, locale, currency, and result-position parameters when those values affect the row.
Preserve the waits
Keep the page-load wait, the visible title wait, and the short sleep before Structured Export. These pauses reduce empty price, room, and review fields on dynamic pages.
Set the export folder
In Structured Export, confirm booking-hotel-listing-scraper-for-germany.csv, headers, append mode, and a project-specific local save folder.
Run one URL, then batch
Run one hotel, open the CSV, compare it with the browser, then process the remaining URLs only after title, price, review, room, and address fields look correct.
Append mode is useful for batches, but it can mix test rows with production rows. Use a dated filename or clear the CSV before rerunning a corrected workflow.
Validation
Validate the export before using it
Open the CSV beside the browser after the first run. Spot-check one row from the start, middle, and end of the URL list. Sort by hotel_url to detect duplicates from repeated input URLs or reruns.
| Symptom | Likely cause | Fix |
|---|---|---|
| Zero rows exported | Prompt, verification page, or page-load failure blocked the hotel page | Resolve the prompt, rerun one URL, and keep the visible-title wait. |
Empty titel | Booking.com served a different layout or the title did not render | Extend the wait and inspect the visible heading selector. |
Blank preis | Price hidden, sold out, session-specific, or delayed | Reopen the exact URL, verify dates and adults, then rerun one page. |
Missing zimmer_typ | The selected room block is not present in the URL or page | Use a URL copied after selecting dates and room context. |
| Review count mismatch | Locale-specific text changed | Adjust the parsing pattern for the page language. |
| Repeated hotels | Duplicate input URLs or append-mode rerun | Dedupe by hotel_url and clear old test rows before the next batch. |
Alternatives
UScraper vs Booking.com API, Python, and cloud scrapers
UScraper is useful when a researcher needs a reviewable local CSV from a controlled list of hotel URLs. It is not a replacement for official partner access. The Booking.com Demand API is the cleaner path for approved affiliates or platforms that need sanctioned search, details, availability, booking, reviews, or reporting endpoints.
Python scraping gives engineers full control over requests, browser rendering, retries, storage, and tests, but it also creates ongoing parser ownership. Hosted Booking.com scraping tools can help with scheduling, proxy infrastructure, remote storage, and larger workloads, but data custody, pricing, and output shape depend on the vendor.
| Approach | Good fit | Trade-off |
|---|---|---|
| UScraper template | Analyst-led Germany hotel exports, no-code setup, local CSV review | Best for supervised URL batches, not high-volume cloud infrastructure. |
| Booking.com Demand API | Approved partner integrations and production travel products | Requires onboarding, credentials, implementation, and permitted use. |
| Python scraper | Engineering teams that need custom parsing and pipelines | Requires code, tests, anti-bot handling, and maintenance. |
| Cloud scraping tools | Scheduled remote runs, APIs, retries, and managed infrastructure | Vendor terms, metering, data custody, and templates vary. |
For most "how to scrape Booking com" research tasks, start with the smallest defensible export. Validate three rows, then widen the URL list only after the CSV matches the browser.
FAQ
Booking.com Germany scraper FAQ
Booking.com hotel pages may be visible in a browser, but automated collection can still be limited by Booking.com's terms, robots directives, copyright, database rights, privacy law, and local regulations. Review the current terms and robots.txt, avoid bypassing CAPTCHA or access controls, keep runs modest, and get legal review before commercial reuse.
Next step
Download the Booking.com Germany hotel scraper template
Use the Booking.com Hotel Listing Scraper for Germany template as the download path, then keep this tutorial open for your first validation pass. For adjacent workflows, browse the broader UScraper template library or return to the UScraper blog for more local desktop app scraping tutorials.