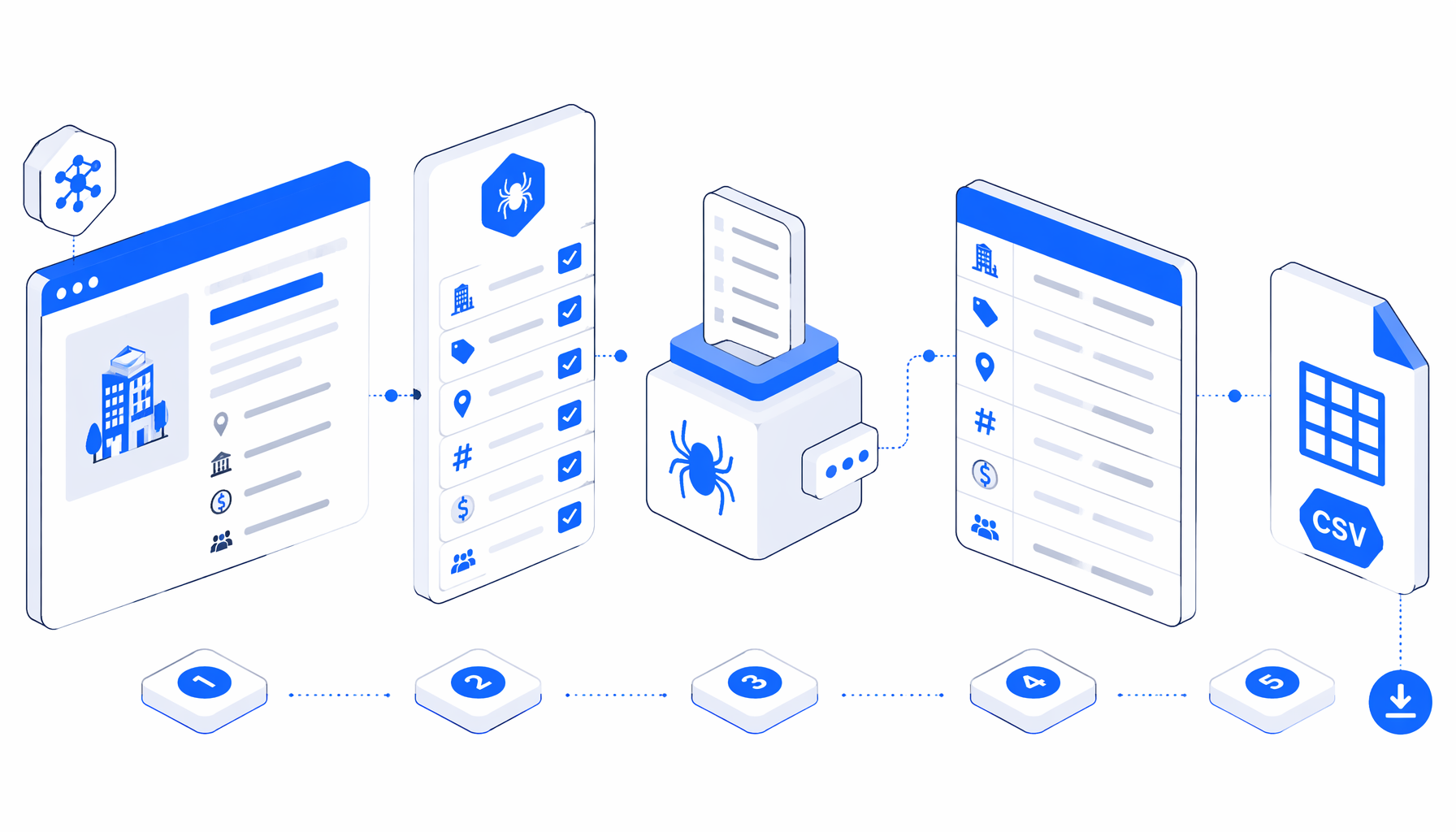
This Baseconnect scraper tutorial shows how to turn reviewed Baseconnect company detail URLs into CSV with the Baseconnect Company Scraper template for UScraper. You will import the workflow, replace the sample URLs, set the export folder, and validate the first rows before using them for research.
Before you start
Prerequisites for a Baseconnect scraper tutorial
You need the UScraper local desktop app, a folder where CSV files can be written, and a short list of Baseconnect company detail URLs you are allowed to process. Start with three to five URLs. Baseconnect profiles can vary by category, company size, listing status, account visibility, and layout section, so the first run is about proving row shape.
This tutorial focuses on detail-page extraction. Use Baseconnect search paths such as industry browsing, prefecture and ward browsing, or business-keyword search to find companies, then feed only reviewed detail URLs into this template.
Review Baseconnect's current terms and robots.txt before automating. Separate public Baseconnect pages from Musubu access; this article does not cover login automation, bypassing controls, or extracting gated data.
Compliance first: scrape only pages you have permission to access, keep request volume modest, do not defeat technical controls, and document why each exported field is needed.
Workflow anatomy
What the Baseconnect company info scraper does
The companion template uses a short multi-URL flow: Navigate -> Wait for Page Load -> Wait for Element -> Structured Export -> Loop Continue. Navigate owns the URL list, the wait blocks confirm the profile is rendered, Structured Export writes the row, and Loop Continue moves to the next detail page.
| Workflow part | What it controls | Why it matters |
|---|---|---|
| Navigate | The Baseconnect company detail URLs | This is your input list. Replace the three sample URLs with the pages you reviewed. |
| Wait for Page Load | Up to 30 seconds for page load | Prevents the export from firing against a half-loaded page. |
| Wait for Element | Visible main h1 | Confirms the profile title is present before row extraction. |
| Structured Export | CSV filename, save folder, columns, append mode | This is the authoritative export shape from the JSON workflow. |
| Loop Continue | Advances the multi-URL loop | Keeps one row per configured detail URL. |
The JSON export is the source of truth for the columns. It defines baseconnect-company-info-scraper.csv, headers enabled, append mode, and JavaScript-backed columns for rendered profile text.
baseconnect-company-info-scraper.csvColumn
company_name
Cleaned company name from the profile heading.
Column
detail_page_url
The Baseconnect detail URL opened for this row.
Column
industry
Visible industry tags joined into one value.
Column
listing_place
Listing market or status when visible on the profile.
Column
summary
Short company summary from the profile header.
Column
address
Registered address or address label text when available.
Column
employee_count
Visible employee count or availability marker.
Column
corporate_number
Corporate number parsed from the profile.
Column
revenue
Revenue field when visible to the browser session.
Runbook
How to scrape Baseconnect company data to CSV
Import the template
Open the Baseconnect Company Scraper template, download the JSON, and import it into UScraper.
Prepare detail URLs
Build a reviewed list of Baseconnect company detail pages. Keep search-result crawling and deduping outside this first extraction workflow.
Replace sample URLs
Open Navigate and replace the bundled URLs with your own Baseconnect company pages. Keep a small first batch so failures are easy to inspect.
Confirm the export folder
In Structured Export, set the save location for baseconnect-company-info-scraper.csv. Leave headers and append mode enabled unless you have a reason to split files.
Run one page
Run a single URL, open the CSV, and compare the row against the browser. Check company name, URL, industry, address, corporate number, and any financial fields.
Run the batch
Reconnect or enable the full loop only after the first row validates. Keep the original URL list beside the CSV so retries and blanks can be traced.
After the first batch, sort by detail_page_url. One unique URL should produce one row. Duplicates usually mean the URL appeared twice or a run resumed after a previous append.
Validation
Validate Baseconnect company list scraping results
Treat validation as part of the workflow. Baseconnect detail pages may expose fields differently across companies, and some values can be unavailable unless the browser session can see them.
| Symptom | Likely cause | Fix |
|---|---|---|
Empty company_name | The page did not reach the expected profile heading | Handle prompts, extend waits, and rerun one URL. |
Blank employee_count or revenue | The value is hidden, unavailable, or not present for that company | Keep the row, but mark the field as not visible instead of inventing a value. |
| Address contains extra text | Baseconnect label structure changed around the address block | Update the selector against the live page and rerun the affected URLs. |
| Industries are missing | The industry list did not render or moved in the layout | Check the page visually and refresh the industry selector. |
| Rows append to an old file | Append mode reused a previous CSV | Clear the file, rename the export, or use a dated project folder. |
Alternatives
Octoparse Baseconnect alternative, Apify, or UScraper?
If you searched for an Octoparse Baseconnect alternative, decide whether you want hosted execution or a local CSV workflow. Octoparse publishes a Baseconnect company info scraper template, and Apify-style actors can help with cloud scheduling or APIs. UScraper fits when the analyst wants to inspect the browser, control the URL list, edit selectors, and keep the CSV local.
| Option | Best fit | Trade-off |
|---|---|---|
| UScraper local desktop app | Supervised Baseconnect exports, analyst QA, local CSV custody | You manage pacing, selector checks, and the run environment. |
| Octoparse template | Hosted no-code extraction and familiar cloud workflows | Less emphasis on local custody and direct workflow ownership. |
| Apify or custom scraper | API-driven jobs, scheduling, engineering integration | More setup, vendor infrastructure, or code maintenance. |
Broad searches such as "company info scraper", "metadata scraper", or "niche scraper" still need a concrete plan. For Baseconnect: gather detail URLs, run a small local export, validate visible fields, then scale.
FAQ
Baseconnect scraper FAQ
Automated access can be restricted by Baseconnect terms, robots directives, copyright, database rights, privacy law, and account rules. Review the current policies, avoid bypassing controls, pace runs modestly, and get legal advice before commercial use.
Next step
Download the Baseconnect company scraper template
When you are ready to run the workflow, download the JSON from Baseconnect Company Scraper and keep this tutorial open for QA. For adjacent company-data workflows, browse all UScraper templates, or use the UScraper blog for more local CSV export tutorials.