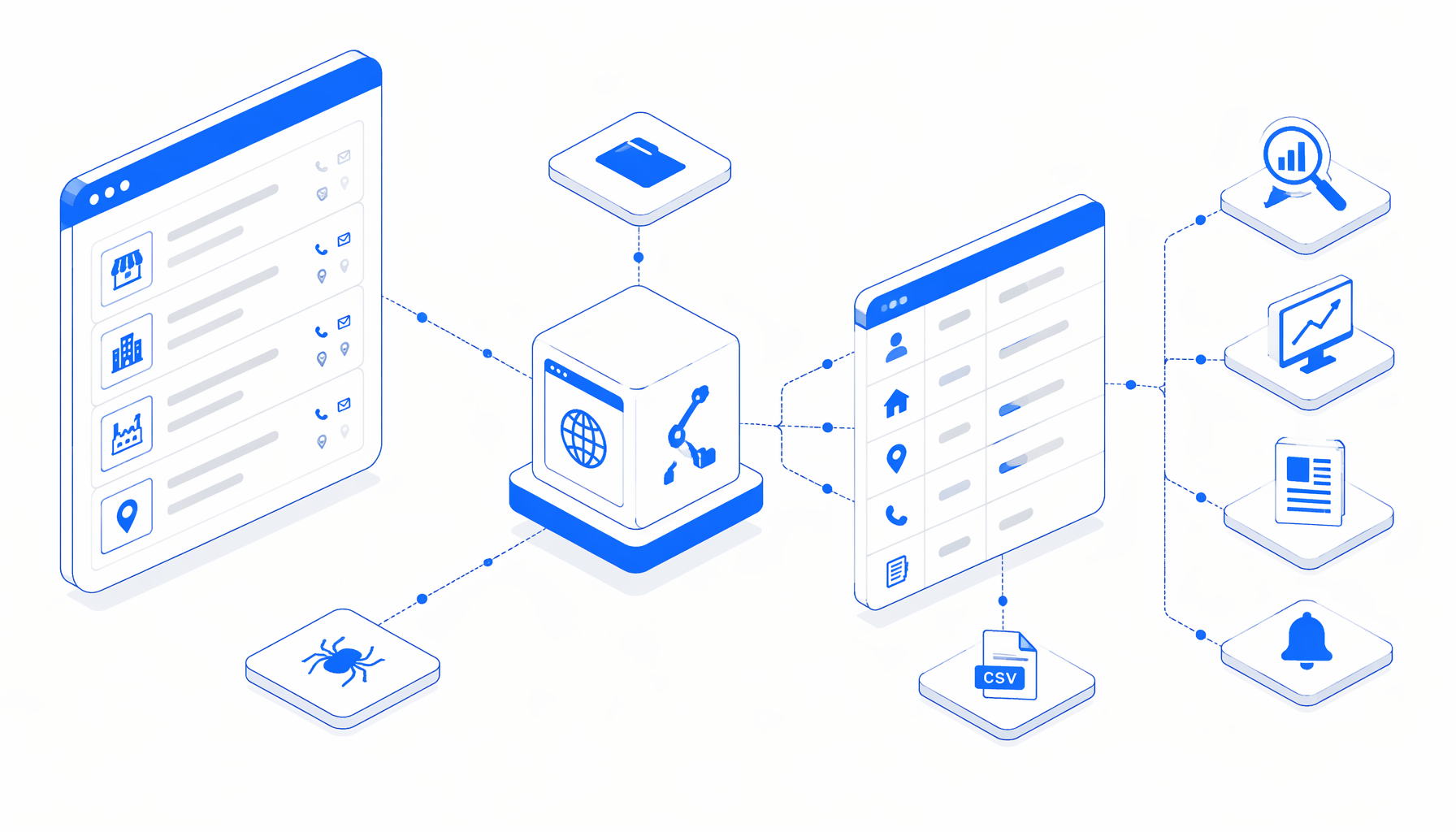
A scraper annuaire 118000 workflow is useful when a team needs a controlled CSV from directory pages, not a loose pile of copied phone numbers. The Annuaire 118000 Data Scraper template turns listing URLs into local rows with name, address, postcode, phone, and note fields for research, SEO, newsroom checks, and monitoring.
Use-case frame
Why directory scraping needs a workflow, not copy-paste
Annuaire 118000 has several useful surfaces: the main professional directory, an activity index, regional pages such as Ile-de-France, a separate private/person directory, city indexes, and reverse-directory pages. Those pages are easy to browse one by one. They become difficult when the question changes from "Who is listed here?" to "Can we compare 200 rows, filter them, verify phones, and document the source?"
That is the gap a directory workflow fills. A good annuaire 118000 data scraper does not just extract contacts. It preserves enough structure for someone else to inspect the result: listing name, address text, five-digit postcode, telephone, note text, source run context, and the fact that pagination was handled consistently.
The value is not the scrape alone. The value is a repeatable export that a researcher, editor, or analyst can defend later.
Personas
Who uses an Annuaire 118000 data scraper?
| Persona | Pain | Useful CSV outcome |
|---|---|---|
| Market researchers | Regional directory checks are slow when every city and activity page is reviewed by hand. | Export rows by location or category, then compare coverage and gaps in a spreadsheet. |
| Newsrooms | Local business or public-interest stories need documented samples rather than screenshots from browser tabs. | Capture names, addresses, postcodes, phone fields, and notes for fact-checking and follow-up calls. |
| SEO teams | Local landing pages need entity research and category coverage checks. | Use directory rows to understand address phrasing, service categories, city coverage, and competitor density. |
| Data operations teams | CRM records need phone and address verification before enrichment or merge work. | Compare exported contact fields against internal data, then route mismatches for manual review. |
| Monitoring teams | A recurring category or location watchlist needs the same collection method each time. | Re-run the same approved URLs and compare row counts, missing phones, or address changes across exports. |
This is where searches like extraire contacts 118000, scraper annuaire entreprises, and tutoriel scraping 118000 usually point to the same problem: the user does not need a big crawling platform first. They need a clean, repeatable table.
Workflow
How the Annuaire 118000 template produces structured export
The template is built from a visible workflow graph, not a hidden script. It opens a starting Annuaire 118000 URL, waits for the page to load, waits for section.card.part listing cards, exports the fields, checks whether link[rel="next"] exists, and uses a short JavaScript step to move to the next page when one is present.
The configured export columns are intentionally simple:
| Column | What it captures | Why it matters |
|---|---|---|
nom | Listing name from the result card | Primary entity for research, dedupe, and manual review |
adresse | Address text cleaned into one line | Location context for local analysis and CRM matching |
cp | Five-digit postcode parsed from the address | Fast filtering by city, department, or territory |
telephone | Visible text, tel: link, or best-effort decoded number image | Phone review without manual copy-paste |
remarque | Short note from the listing bubble when present | Useful context for opening hours, contact hints, or card annotations |
There was no CSV sample in the source bundle, so the safest way to describe the output is the workflow definition itself: annuaire_118000_data_scraper.csv, headers enabled, append mode on, and pagination repeated until no next-page link remains.
Scenarios
Concrete use cases for Annuaire 118000 data
1. Local market research
A researcher comparing business density across cities can start from activity or regional URLs, export listings, and group rows by postcode. The goal is not to claim complete market coverage from one run. The goal is to create a defensible sample that can be filtered, cleaned, and reviewed with the source pages nearby.
2. Newsroom source building
Newsrooms often need quick contact lists for a local story: businesses in a category, professionals in a region, or records connected to a public-interest topic. A CSV export helps editors divide verification work, assign calls, and mark which rows were confirmed. It should sit beside editorial checks, not replace them.
3. SEO and local content planning
SEO teams working on French local pages can use a directory export to inspect naming patterns, category density, city coverage, and address formats. That research can inform briefs, internal linking, service-area pages, and competitor maps. It is a research input, not a source to publish blindly.
4. CRM cleanup and record matching
Data teams can compare the exported nom, adresse, cp, and telephone columns against existing records. Strong matches move through cleanup faster. Weak matches become a manual review queue. That is a better workflow than importing unverified rows directly into a CRM.
5. Directory monitoring
For recurring monitoring, keep the input URL, collection date, and CSV filename together. Compare row counts, blank phone rates, postcode spread, and changed notes across runs. When a field suddenly goes empty, treat it as a selector or layout-change signal before treating it as a business change.
Decision
UScraper vs Annucapt, custom scripts, and cloud tools
People searching for the meilleur scraper annuaire or an alternative Annucapt are usually comparing effort, custody, and scale. The right answer depends on how much infrastructure you want to own.
| Route | Best fit | Trade-off |
|---|---|---|
| UScraper template | Controlled Annuaire 118000 URLs, local desktop app runs, visible workflow edits, CSV review | Best for analyst-led batches, not unattended fleet-scale crawling |
| Annucapt or directory extraction suites | Broad French directory extraction needs and dedicated directory workflows | May be better for larger managed use cases, but can be more tool-specific |
| Custom Scrapy or Crawlee project | Engineering teams that need tests, queues, proxies, versioned parsers, and full control | Highest flexibility, highest maintenance burden |
| Hosted scraper platforms | Cloud scheduling, API delivery, large recurring jobs, and vendor-managed infrastructure | Inputs, outputs, logs, and billing live inside the provider model |
For many research teams, the first useful step is not a full crawler. It is a local CSV run that proves which fields are available and whether the row quality is good enough to justify a larger process.
Responsible use
Compliance and robots checks before you run
Directory data can include personal data, business contact data, or both. Public visibility does not remove compliance obligations. Before using exported rows for outreach or enrichment, review the relevant 118000 terms, the site's robots.txt, and guidance from regulators such as the CNIL on reusing public online data for commercial prospecting and legitimate-interest safeguards for web scraping.
Robots.txt is also not a legal permission slip. Google describes robots.txt as a way to manage crawler traffic, which makes it a technical signal to check alongside terms, access controls, privacy rules, rate limits, and your own lawful basis.
Runbook
A reliable Annuaire 118000 scraping runbook
Choose one approved result URL
Start with a focused professional, city, activity, or regional page. Avoid mixing unrelated sources in the same run.
Import the template
Download the Annuaire 118000 Data Scraper template and import the JSON workflow into UScraper.
Confirm the export folder
Structured Export writes annuaire_118000_data_scraper.csv. Keep headers enabled and use a clean folder for each research batch.
Run a small validation batch
Compare the first page of CSV rows against the browser. Check names, postcodes, phone values, and notes before increasing the URL scope.
Audit before using the data
Mark blanks, duplicates, layout-change symptoms, and records that need manual confirmation before CRM import, reporting, or outreach.
For adjacent workflows, browse the UScraper template library or the wider UScraper blog for directory, research, and monitoring examples.
FAQ
Annuaire 118000 data scraper FAQ
It is for researchers, newsrooms, SEO teams, local-market analysts, and data operations teams that need a controlled CSV from approved Annuaire 118000 result pages. It works best for reviewable batches, not unrestricted bulk collection.
Next step
Download the Annuaire 118000 Data Scraper template
Use this workflow when you need to extraire contacts 118000 into a CSV that teammates can inspect. Download the Annuaire 118000 Data Scraper template, validate one small run, then expand your research process only after the exported rows match the source pages.