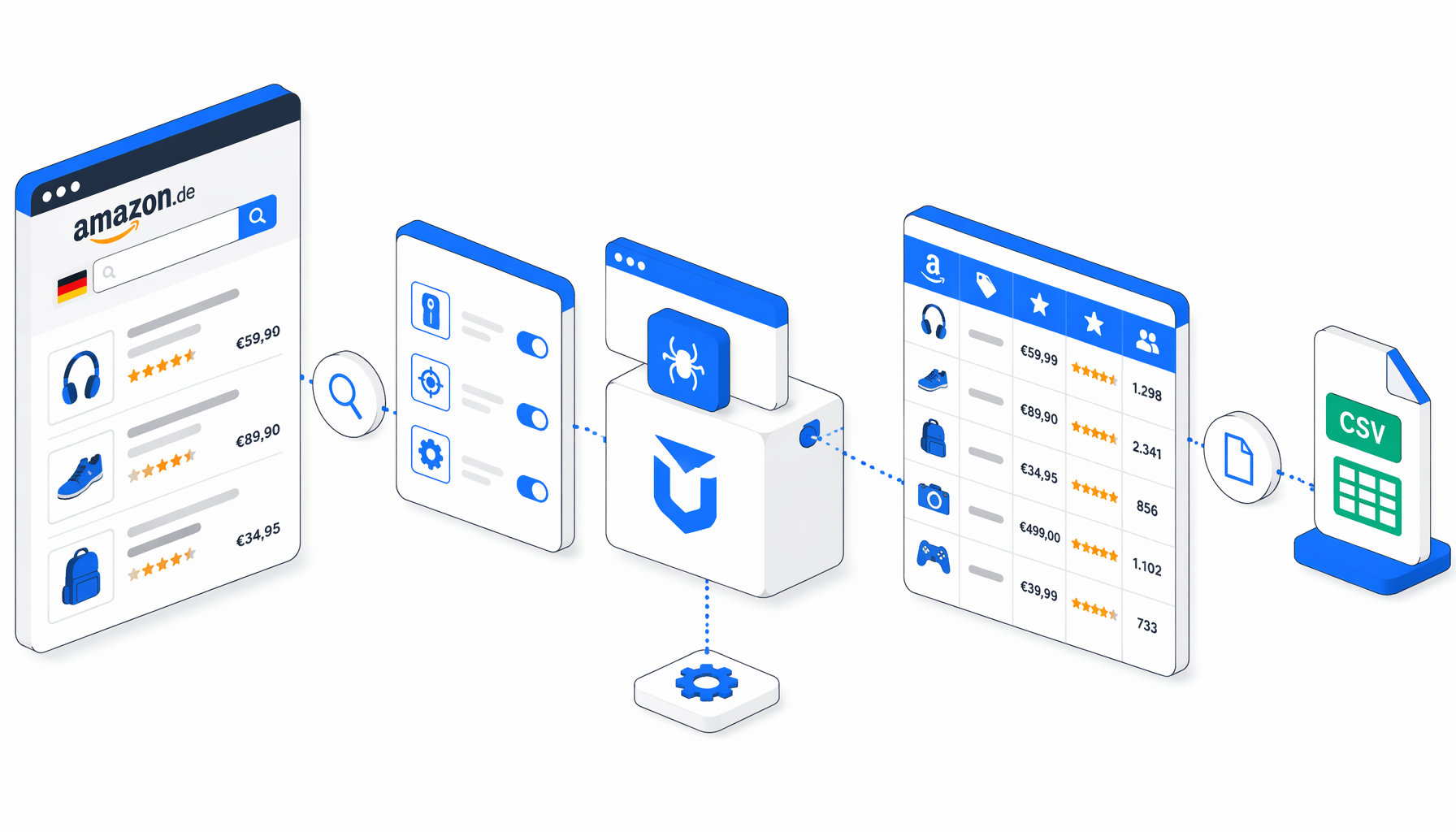
This tutorial shows how to scrape Amazon.de product data from keyword search results into CSV with the Amazon.de Product Scraper for Germany template for UScraper. You will import the workflow, edit the keyword URLs, set the export path, validate the first rows, and decide when an official API or hosted scraper is a better fit.
Before you start
Prerequisites and scope
You need UScraper installed as a local desktop app, the free template JSON, one Amazon.de keyword you are allowed to research, and a folder for CSV exports. The bundled workflow uses the sample keyword weihnachten+kerzen across 10 known Amazon.de search-result URLs. Treat that as a safe starting shape, not a fixed topic.
This is a search-results tutorial. It collects visible product cards, not full product detail pages, private account data, checkout information, seller dashboards, or review bodies. For deeper product-page fields, use a detail-page workflow after you shortlist ASINs. For sanctioned product applications, compare this approach with Amazon Product Advertising API and Selling Partner API access before building a recurring pipeline.
Technical access is not the same thing as permission. Review source terms, robots guidance, marketplace policies, and local data rules before collecting or redistributing product data.
Workflow shape
What the Amazon.de product scraper does
The JSON export is the authoritative workflow definition. In plain English, it follows this path:
Set Window Size -> Navigate -> Wait for Page Load -> Cookie Check
-> Result Row Check -> Structured Export -> Sleep -> Loop Continue
The Navigate block holds explicit URLs for pages 1-10 of the sample Amazon.de keyword. That makes the run easy to audit because each page URL is visible before execution. The workflow then waits for the page, checks for #sp-cc-accept, clicks the cookie button when present, waits again, and looks for search result rows with non-empty ASIN values. If product rows exist, Structured Export writes them to CSV in append mode. If not, the workflow stops gracefully instead of writing empty output.
| Workflow part | Purpose | What to verify |
|---|---|---|
| Set Window Size | Opens a consistent browser viewport | Keep the default unless your selectors need a different layout. |
| Navigate | Visits each Amazon.de search URL | Replace only the keyword and page count you intend to collect. |
| Cookie branch | Accepts #sp-cc-accept when shown | Run once manually if Amazon changes the consent prompt. |
| Result row check | Looks for Amazon product cards with ASINs | Stop on CAPTCHA, sign-in gates, or blank layouts. |
| Structured Export | Appends rows to the configured CSV | Confirm headers, file name, save folder, and append mode. |
| Loop Continue | Advances to the next configured URL | Watch the first loop for repeated pages or blocked responses. |
Runbook
How to scrape Amazon.de product data to CSV
Import the template
Open Amazon.de Product Scraper for Germany, download the workflow JSON, and import it into UScraper.
Edit the keyword URLs
In Navigate, replace weihnachten+kerzen with your approved Amazon.de keyword. Keep one URL per result page, such as page=1, page=2, and so on.
Confirm the export folder
In Structured Export, confirm amazon-produkt-scraper-results.csv, headers enabled, append mode, and a project-specific local save folder.
Run one page first
Execute the first URL, then compare a few CSV rows with the browser for ASIN, title, detail URL, rating, review count, price, and timestamp.
Run the remaining pages
Continue the configured URL loop only after the first page passes QA. Watch for CAPTCHA, repeated pages, sudden redirects, or large blocks of blank values.
The key habit is to treat the first export as setup, not production. If the first page has wrong titles, blank ASINs, or mismatched prices, running nine more pages only creates a larger cleanup job.
Output
Amazon.de to CSV fields to validate
The bundle has no static CSV sample, so use the workflow export shape plus your first live run as the sample for your keyword, language, session, and delivery context. The CSV columns are intentionally narrow because this template is for product discovery from search results.
| CSV column | Source | Validation note |
|---|---|---|
Keyword | Parsed from the current Amazon.de search URL | Confirm URL encoding did not change the intended keyword. |
ASIN | Search-result row data-asin attribute | Use ASIN as the main dedupe key. |
Title | Visible product title, with fallback logic | Check long titles and sponsored cards. |
Detail_Page_URL | Product link pointing to /dp/ or /gp/product/ | Open a few links before reporting. |
Star_Rating | Visible rating text from the card | Expect blanks for unrated or differently rendered products. |
Number_of_Reviews | Review link text or accessible review label | Compare high-review products first. |
Price | Visible price text from the result card | Blank is valid when Amazon shows no price. |
Current_Time | Export timestamp generated by the workflow | Useful for monitoring and audit trails. |
Troubleshooting
Common Amazon.de scraping issues
| Symptom | Likely cause | Fix |
|---|---|---|
| No product rows exported | CAPTCHA, bot check, sign-in gate, regional redirect, or selector drift | Stop the run, inspect the browser, and do not try to bypass access controls. |
| Product titles are blank | Amazon changed card title markup or the page did not finish rendering | Increase waits, rerun one page, then update selector logic if needed. |
| Prices are missing | No visible price, unavailable item, delayed price module, or location-dependent pricing | Keep blanks when the browser has no price; do not invent values. |
| Ratings or review counts look wrong | Locale text or review module changed | Compare live cards and update the extraction pattern for Amazon.de. |
| Duplicate rows appear | Same URL supplied twice or append mode reused an old file | Dedupe URLs, archive old CSVs, and restart with a clean output file. |
Tool choice
UScraper vs Amazon APIs and hosted scraper tools
People searching for an Amazon product scraper Germany often compare no-code templates, Apify actors, Octoparse templates, Python scripts, scraper APIs, Product Advertising API, and Selling Partner API. They are not interchangeable.
| Option | Best fit | Main trade-off |
|---|---|---|
| UScraper local desktop template | Analyst-led keyword research and CSV-first product discovery | Best for supervised batches, not unattended high-volume crawling. |
| Product Advertising API | Approved product or affiliate applications that need documented API responses | Requires eligibility, credentials, policy compliance, and implementation work. |
| Selling Partner API | Registered seller and marketplace operations use cases | Not a general replacement for public search-result scraping. |
| Hosted actors and scraper APIs | Engineering teams needing managed runtime, APIs, scheduling, proxies, or larger scale | Inputs and outputs pass through a third-party provider, and pricing often scales with usage. |
| Python scripts | Technical users who need full control over requests and parsing | You own rendering, blocking, retries, selector maintenance, and data QA. |
For a quick research spreadsheet, UScraper keeps the workflow visible and editable. For a production feature, contractual feed, affiliate use case, or recurring high-volume job, evaluate official APIs and vendor terms first.
FAQ
Amazon.de product scraper FAQ
Amazon.de search results may be visible in a browser, but automated collection can still be limited by Amazon terms, robots directives, anti-abuse controls, intellectual property rights, privacy law, and local rules. Keep batches modest, do not bypass CAPTCHA or access controls, and get legal review before commercial reuse.
Next step
Download the Amazon.de product scraper template
Use Amazon.de Product Scraper for Germany as the download path, then keep this tutorial open while you edit the keyword URLs and validate the first CSV. For adjacent workflows, browse all UScraper templates or return to the UScraper blog for more scraping tutorials.