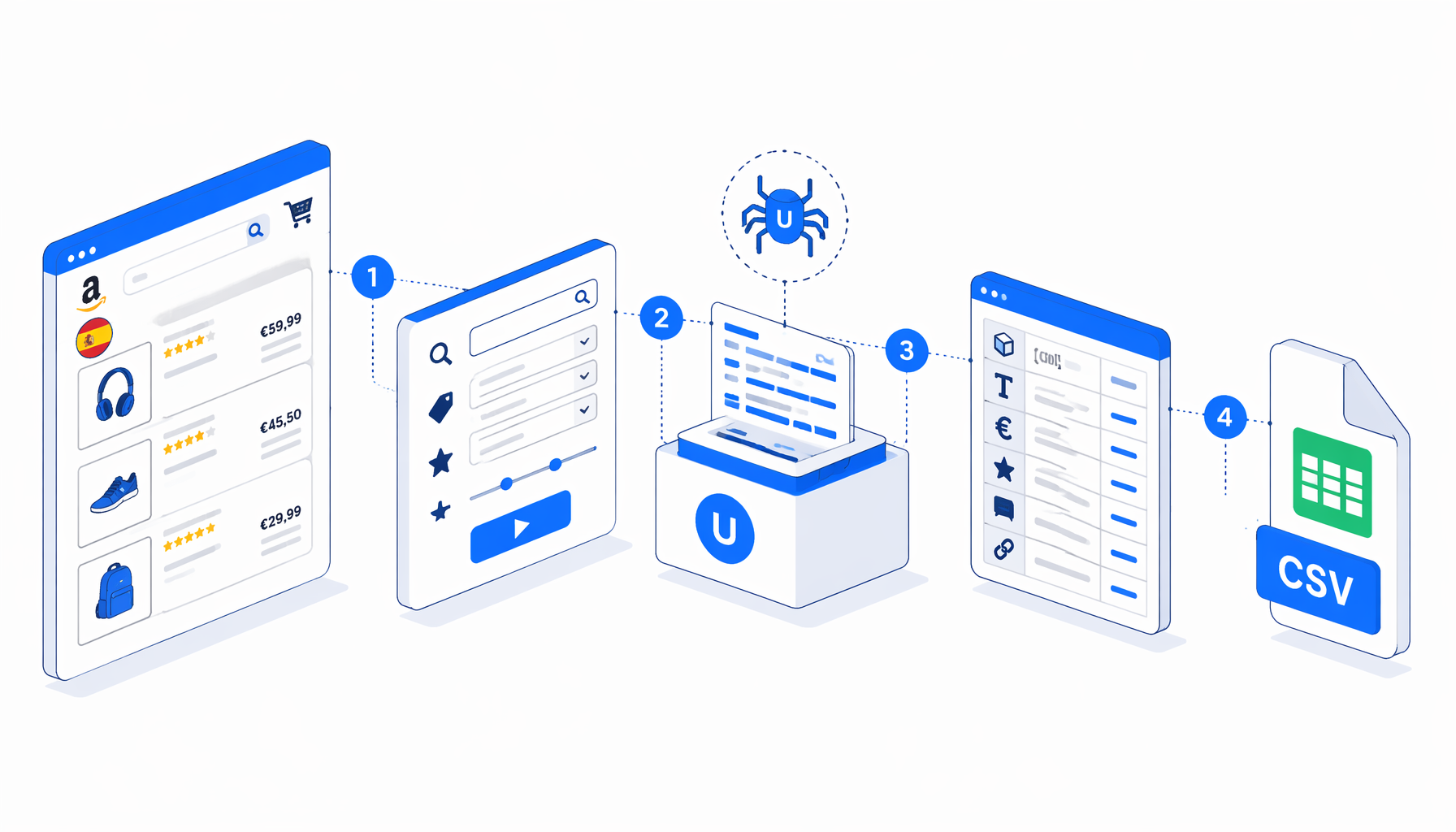
This tutorial shows how to scrape Amazon Spain product listings into CSV with the Amazon Spain Product Listing Scraper for UScraper. You will import the workflow, replace the sample keyword, confirm the export path, run a controlled Amazon.es listing scrape, and validate ASIN, title, price, rating, review count, product URL, and timestamp fields before using the data.
Before you start
Prerequisites and Amazon Spain checks
You need UScraper installed as a local desktop app, one approved Amazon.es search keyword, and a folder where the CSV can be saved. Start with a narrow keyword such as a brand, category, model, or the bundled sample keyword cable. Do not start with a long keyword list or a broad category crawl.
This guide covers supervised collection from visible Amazon.es search result pages. It does not cover account pages, seller dashboards, checkout flows, login-only content, private data, CAPTCHA bypassing, or resale of scraped data. Before automation, review Amazon source terms, robots guidance, marketplace policies, official API options, and your own legal obligations.
Browser access is not the same thing as permission. Keep the run modest, document the business reason, stop when Amazon presents a verification barrier, and use official or licensed data routes when a production system needs guaranteed coverage.
Workflow anatomy
What the Amazon Spain product listing scraper does
The bundled JSON workflow is the workflow contract. It starts at https://www.amazon.es/s?k=cable&page=1&language=es_ES, waits for the page, checks for a CAPTCHA continue button, waits for result cards, and runs Structured Export against each non-empty listing row. After export, an Element Exists block checks for a.s-pagination-next:not(.s-pagination-disabled). If the live Next link exists, UScraper clicks it, waits again, and returns to the same export block. If Next is disabled or missing, the workflow ends.
The detail URL column uses a robust extractor: first it looks for a direct /dp/ASIN link, then for encoded product links, and finally falls back to https://www.amazon.es/dp/{ASIN}. That makes the CSV easier to dedupe and easier to join with detail-page or review workflows later.
| Workflow part | What it does | Why it matters |
|---|---|---|
| Navigate | Opens the Amazon.es keyword URL | Keeps the run tied to one reviewed search query. |
| CAPTCHA check | Detects a visible Amazon validation button | Lets you stop, review, or continue manually instead of treating a blocked page as data. |
| Wait for result cards | Waits for div.s-main-slot product rows | Reduces empty CSV rows from dynamic page loading. |
| Structured Export | Appends one row per visible result card | Produces spreadsheet-ready Amazon.es product listing data. |
| Pagination loop | Clicks the enabled Next link and repeats | Collects reachable result pages without rebuilding the workflow. |
Runbook
How to scrape Amazon Spain product listings to CSV
Download and import
Open the Amazon Spain product listing scraper template, download the JSON workflow, and import it into UScraper.
Edit the keyword URL
In the Navigate block, replace k=cable with the Amazon.es keyword your team is allowed to review. Keep the domain on www.amazon.es and keep one keyword per dry run.
Keep waits and checks in place
Leave the page-load wait, CAPTCHA check, result-card wait, and short pagination sleep enabled for the first run. Amazon result cards render dynamically.
Confirm the export path
Structured Export writes amazon-espana-listados-scraper.csv with headers enabled and file mode set to append. Change the folder for each client, date, or keyword batch.
Run, inspect, and continue
Run one page, compare the CSV with the visible browser results, then let the Next-button loop continue through reachable pages.
After the first export, sort the CSV by keyword, asin, and current_time. One visible product card should create one row. If the same ASIN appears more than once, check whether Amazon displayed both organic and sponsored placements before deduping.
Output
Amazon.es product listing output fields
The export is designed for marketplace research, pricing checks, assortment review, ASIN discovery, and spreadsheet handoff. There is no bundled CSV sample for this template, so use the JSON workflow definition and the output shape below as the source of truth.
| CSV column | Source in the workflow | Validation tip |
|---|---|---|
keyword | Parsed from the current URL search parameter | Confirm it matches the keyword in the browser address bar. |
asin | Result card data-asin attribute | Blank ASINs should be filtered out before analysis. |
title | Visible result-card title | Open a few detail URLs and compare product titles. |
detail_page_url | Direct, encoded, or fallback /dp/ASIN URL | Use this as the join key for detail-page scraping. |
star_rating | Visible rating text or accessible rating label | Expect locale-specific text such as "de 5". |
number_of_reviews | Review link text or accessible label | Review counts may be blank for new or hidden items. |
price | Listing card price selector | Blank prices can be valid when Amazon hides offers. |
current_time | Export-time timestamp | Use it for run auditing and freshness checks. |
amazon-espana-listados-scraper.csvColumn
keyword
Keyword parsed from the Amazon.es search URL, such as cable.
Column
asin
Product ASIN from the result card data attribute.
Column
title
Visible product title from the search result card.
Column
detail_page_url
Best-effort product URL, with canonical /dp/ASIN fallback.
Column
star_rating
Visible star rating text when Amazon renders one.
Column
number_of_reviews
Review count parsed from review links or accessible labels.
Column
price
Visible listing price from the result card when present.
Column
current_time
Collection timestamp generated during export.
Quality control
Validate the first Amazon Spain scraper run
Do not judge the run by row count alone. Keep the browser open beside the CSV and spot-check rows from page one, a middle page, and the final page reached by the pagination loop.
| Symptom | Likely cause | Fix |
|---|---|---|
| Zero rows exported | Product cards did not render, a prompt blocked the page, or the row selector changed | Handle the prompt, wait for visible cards, then rerun one keyword. |
Blank price | Offer hidden by region, unavailable item, delayed module, or page variant | Check the visible listing before treating the cell as failed. |
| Wrong keyword value | Navigate URL still contains the sample query or a redirected URL | Update k= and rerun the dry test. |
| Broken product URL | Amazon wrapped links in an unexpected format | Use the ASIN fallback and inspect the link extractor if needed. |
| Pagination stops early | Amazon removed or disabled the Next link for that session | Keep the last page reached and record the run context. |
Guardrails for reliable Amazon Spain listing scraping
Keep keyword batches conservative
Avoid parallel runs against the same source, keep wait blocks in place, and stop if Amazon responds with repeated verification or access warnings.
Expect layout maintenance
Amazon can change result cards, rating labels, price modules, sponsored modules, and pagination markup. Empty columns usually mean the visible page changed.
Use permitted keywords and data
Review source terms, official API options, retention rules, and downstream use before redistributing, reselling, or enriching scraped Amazon product data.
Alternatives
Best Amazon Spain scraper approach: template, API, or cloud actor?
UScraper is strongest when an analyst wants a no-code CSV workflow, a visible browser session, editable selectors, and local file custody. Hosted actors and scraper APIs can be useful for scheduling, proxy handling, or developer integration, but they usually introduce vendor custody, usage-based pricing, schema constraints, or implementation work.
If you are comparing Apify vs Octoparse for Amazon Spain, think in workflow terms rather than brand terms. Octoparse-style templates are useful for no-code managed scraping. Apify-style actors are useful when you want cloud automation and programmatic runs. Amazon's Product Advertising API is the route to review when your use case needs approved product metadata access and you can meet its eligibility, authentication, and request requirements.
| Approach | Good fit | Trade-off |
|---|---|---|
| UScraper local desktop template | Controlled keyword snapshots and Amazon listings to CSV | You validate prompts, pacing, and selectors before scaling. |
| No-code cloud templates | Teams that want a hosted interface and managed runs | Search terms and output pass through a third party. |
| Cloud scraper actors or APIs | Developer workflows, scheduled jobs, and infrastructure handling | Pricing, quotas, schemas, and vendor custody need review. |
| Amazon Product Advertising API | Approved product-data workflows with documented API behavior | Requires credentials, eligibility, request signing, and API-specific field coverage. |
Browse the UScraper template library for adjacent ecommerce workflows, including product details and reviews, or read more UScraper blog tutorials when you need a runbook before importing a template.
FAQ
Frequently asked questions
Amazon.es listing pages may be visible in a browser, but automated collection can still be restricted by Amazon terms, robots directives, anti-abuse systems, intellectual property rights, privacy law, and local rules. Keep batches modest, do not bypass CAPTCHA or access controls, and get legal review before commercial reuse.
Next step
Download the Amazon Spain listing workflow
Use Amazon Spain Product Listing Scraper as the download path, then keep this tutorial open while you validate the first CSV. For related workflows, browse all UScraper templates or the UScraper blog for other ecommerce scraping tutorials.