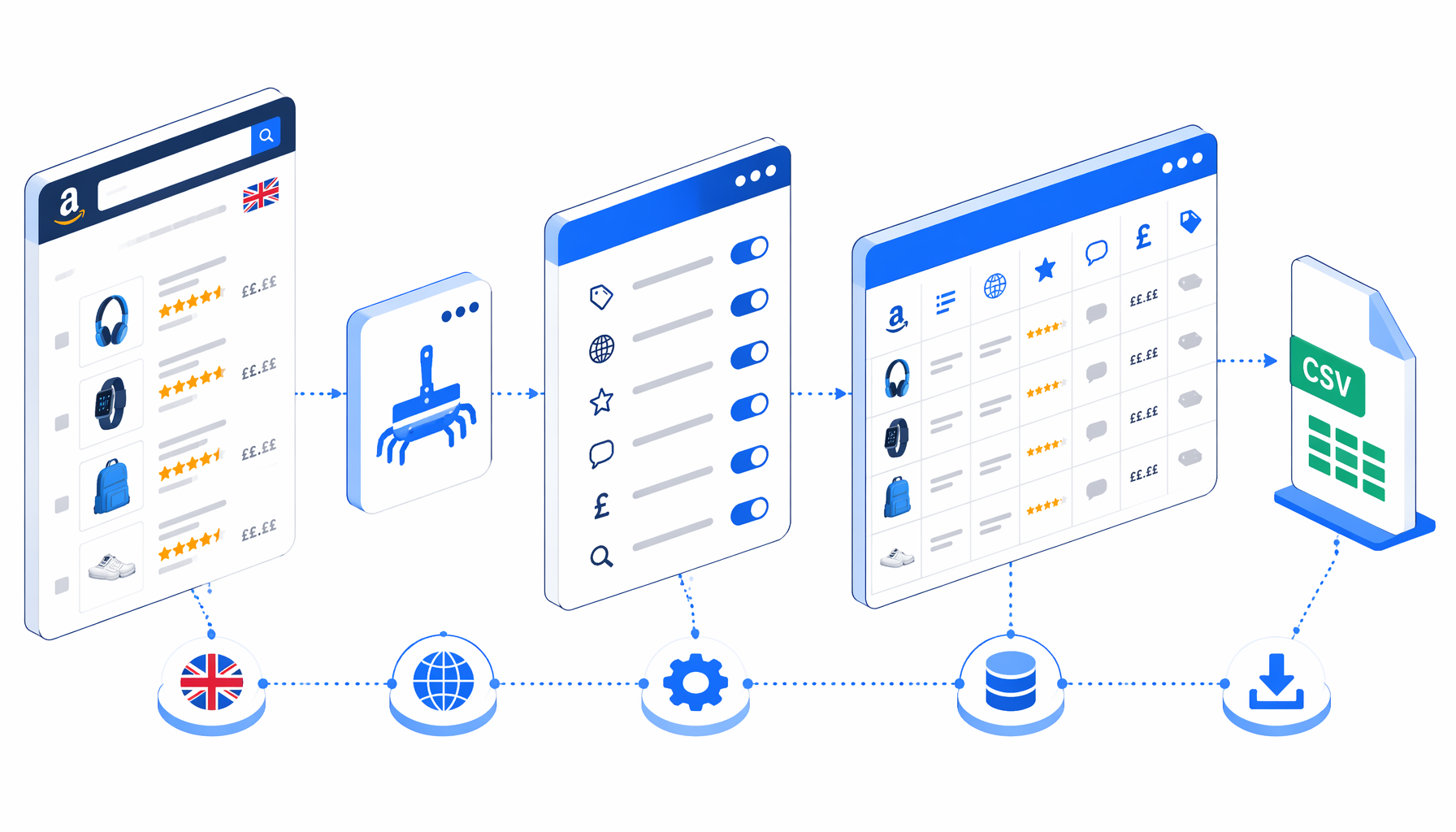
This tutorial shows how to scrape Amazon UK product listings from keyword search results into CSV with the Amazon Product Listing Scraper for UK template for UScraper. You will import the workflow, edit the keyword and page URLs, set the export path, validate the rows, and decide when an official API route is a better fit.
Before you start
Prerequisites, scope, and policy checks
You need UScraper installed as a local desktop app, the Amazon UK product listing template, and a folder where the CSV can be written. Start with one keyword, one or two result pages, and a single output file so validation stays fast.
This guide covers public Amazon.co.uk keyword search-result pages, not account pages, seller dashboards, checkout flows, or CAPTCHA bypassing. Before automating any source, review the current Amazon.co.uk robots.txt, Amazon terms that apply to your use case, and your local rules around collection, retention, and resale.
If your project needs sanctioned product data, signed requests, service-level reliability, or production redistribution, compare this workflow with Amazon's official Product Advertising API UK locale reference and SearchItems documentation. A no-code browser workflow is useful for controlled CSV research; an official API is usually cleaner for approved application integrations.
Compliance first: scrape only pages you are allowed to access, keep batches modest, stop on access challenges, and do not use automation to defeat controls.
Workflow anatomy
What the Amazon UK listing scraper template does
The bundled JSON workflow is intentionally direct: Navigate -> Wait for Page Load -> Cookie Prompt -> Sleep -> Wait for Product Rows -> Structured Export -> Sleep -> Loop Continue. Navigate contains editable Amazon.co.uk search URLs. The sample bundle uses the keyword shoes across pages 1-5; replace those URLs with the keyword and page range your team has approved.
Structured Export is the main block. It selects visible product result cards, appends rows to amazon-product-listing-scraper-for-uk.csv, includes headers, and writes these columns:
amazon-product-listing-scraper-for-uk.csvColumn
keyword
Keyword parsed from the current Amazon.co.uk search URL, such as shoes.
Column
asin
ASIN from the search-result row data attribute.
Column
title
Visible product title from the result card.
Column
detail_page_url
Product detail URL from a /dp/ or sponsored click-through listing link.
Column
star_rating
Visible star rating text when Amazon renders one.
Column
number_of_reviews
Review or rating count text from the listing card.
Column
price
Visible price from the result card when available in the session.
Column
current_time
Collection timestamp generated at export time.
The JSON export is the source of truth for block IDs, selectors, file mode, and connections. Use the Amazon Product Listing Scraper for UK page as the download path rather than rebuilding blocks from prose.
Runbook
How to scrape Amazon UK products to CSV
Import the template
Open Amazon Product Listing Scraper for UK, download the JSON, and import it into UScraper.
Edit the keyword URLs
In Navigate, replace the sample https://www.amazon.co.uk/s?k=shoes&page=... URLs with your approved Amazon UK keyword and page count.
Confirm prompts and waits
Keep the 45-second page-load and product-row waits. The template includes a small browser-side step for common cookie consent buttons.
Set the export folder
In Structured Export, choose your own save folder, keep headers enabled, and keep append mode if multiple pages should land in one CSV.
Run one page, then expand
Run a single URL first, compare the CSV with the browser, then add the remaining search pages after ASIN, title, price, and review fields look sane.
Validation
Validate the Amazon search results export
Treat validation as part of scraping, not an afterthought. Amazon result pages are dynamic, and listing cards can vary by region, delivery context, availability, ads, language, and session state. Keep the browser open beside the CSV and check one row from the first page, one from the middle, and one from the end.
| Symptom | Likely cause | Fix |
|---|---|---|
| No rows exported | Product cards did not render, a prompt blocked the page, or a challenge page loaded | Open the browser view, handle the prompt, keep waits, and rerun one URL |
Blank price | Amazon did not show a visible price for that card or session | Keep the row, but do not treat price as required for every listing |
Missing star_rating or number_of_reviews | New products, sponsored modules, or layout variants may omit review text | Compare the card in the browser and update selectors only after confirming the field exists |
| Duplicate ASINs | The same product appeared on multiple pages or the same URL ran twice | Deduplicate by asin plus keyword and keep current_time for audit |
| Wrong keyword | Navigate URL was edited but encoded query parameters changed | Check the k parameter in every URL before a batch run |
API fit
Amazon API vs web scraping for product listings
The question is not whether an API or scraper is "better" in the abstract. It is which access path matches the job. The Product Advertising API is designed for eligible applications that need signed requests and documented item responses. The SearchItems operation is the official keyword-search path in that API family, while the UK locale docs define the marketplace context for Amazon.co.uk.
Use the API path when you need approved access, contractual clarity, application integration, predictable schemas, and production behavior. Use a no-code scraper when the task is narrower: an analyst needs a supervised CSV of visible Amazon UK search results, wants to inspect the browser state, and can tolerate layout maintenance.
| Option | Best fit | Trade-off |
|---|---|---|
| UScraper local desktop app template | Controlled keyword research, spreadsheet exports, visible browser QA | Needs careful pacing, policy review, and selector maintenance |
| Amazon Product Advertising API | Approved apps, signed requests, documented item search | Requires eligibility, credentials, implementation work, and API coverage review |
| Hosted tools such as Octoparse or Apify | Cloud runs, scheduling, managed infrastructure, API-style datasets | Search terms and exported rows usually pass through a third-party platform |
| Custom Python or Selenium scripts | Engineering teams that own parsing, retries, tests, and storage | Highest control, highest maintenance cost |
Common issues
Common issues and practical fixes
Stop the run. Do not automate around access challenges. Reduce volume, review the source rules, and use an official API or approved provider when the use case requires reliability at scale.
FAQ
Frequently asked questions
Amazon UK listing pages can be visible in a browser, but automated access may still be limited by Amazon terms, robots directives, anti-abuse systems, intellectual property rules, privacy law, and local regulations. Keep runs modest, do not bypass CAPTCHA or access controls, and get legal review before commercial reuse.
Next step
Download the Amazon UK product listing scraper template
When you are ready to run the workflow, download the JSON from Amazon Product Listing Scraper for UK and keep this article open for validation. For adjacent ecommerce workflows, browse all UScraper templates or return to the UScraper blog for more scraping tutorials and comparison guides.