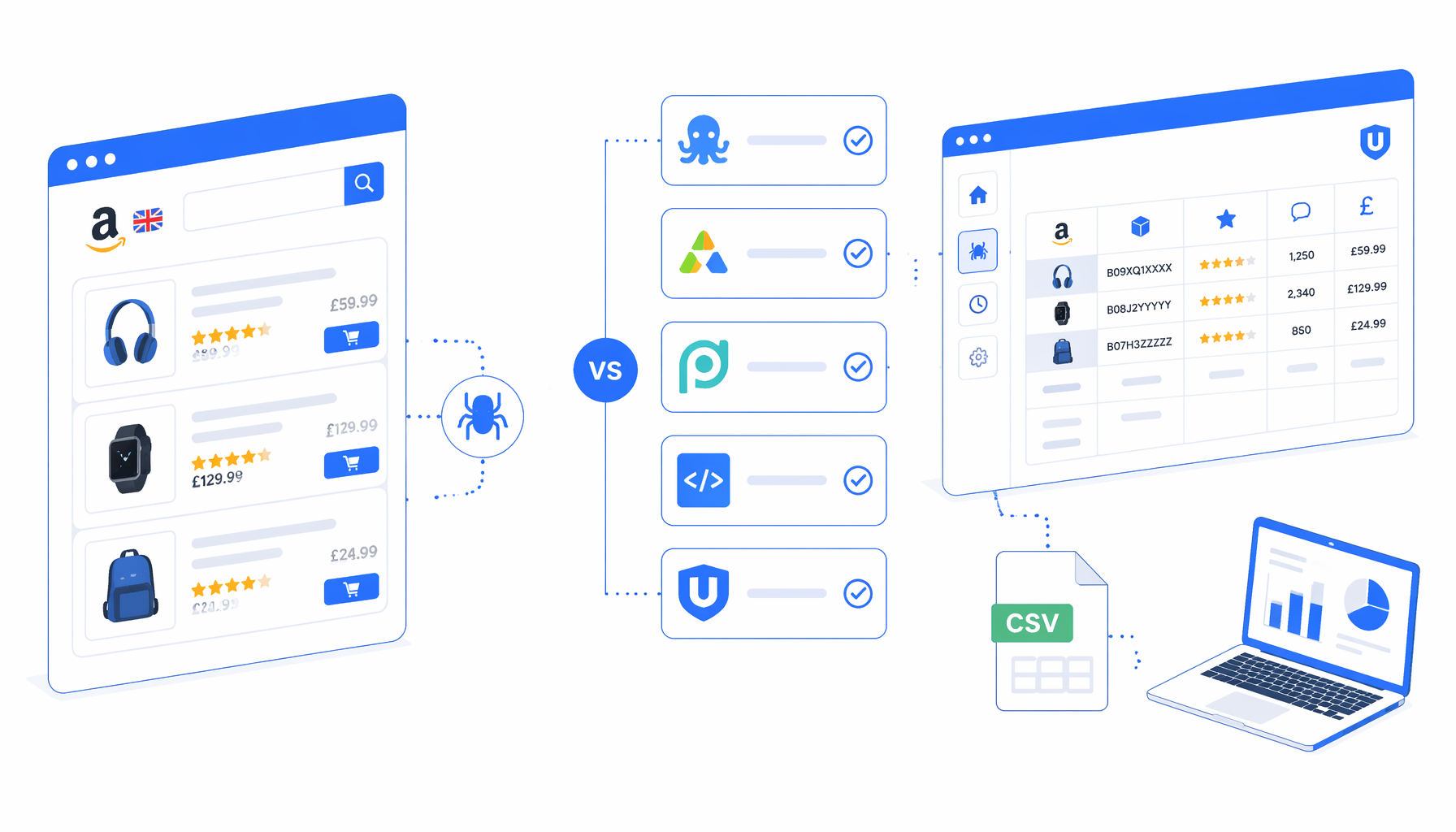
The best Amazon UK scraper alternative is not a single brand. It depends on whether you need hosted scale, no-code setup, developer control, or a local CSV workflow you can inspect. This comparison looks at Octoparse templates, Apify marketplace actors, Bright Data-style scraper APIs, ParseHub-style visual scrapers, custom scripts, and UScraper's Amazon Product Listing Scraper for UK template.
Comparison frame
Amazon UK scraper alternatives compared
Most "how to scrape Amazon UK" searches hide different jobs. A marketplace analyst may need five pages of "shoes" results in CSV. A pricing team may need recurring product checks. A data company may need APIs, queues, retries, proxies, and warehouse delivery. Those are not the same buying decision.
The practical split is:
- Marketplace actors such as Apify Amazon actors, where hosted runs produce datasets and connect to APIs.
- No-code SaaS templates such as Octoparse Amazon listing and detail templates in a hosted visual scraper.
- Scraper APIs and managed data providers such as Bright Data, for structured Amazon endpoints.
- Visual scrapers such as ParseHub for flexible one-off extraction projects.
- Custom scripts using Playwright, Puppeteer, Python, proxies, or scraping libraries.
- Local desktop workflows such as UScraper templates, where flow and export columns stay visible.
The useful question is not "which tool can scrape Amazon?" It is "which tool produces rows your team can maintain and explain?"
Side-by-side
Amazon product scraper comparison table
| Option | Best fit | Hosting | Code needed | Typical output | Pricing shape | Main trade-off |
|---|---|---|---|---|---|---|
| Octoparse Amazon UK templates | No-code teams that want a hosted visual template | Vendor cloud | Low | CSV, Excel, cloud task output | SaaS plan and task limits | Convenient visual setup, less local custody |
| Apify Amazon actors | Recurring hosted runs, datasets, APIs, automation hooks | Apify cloud | Low to medium | Dataset, JSON, CSV, API access | Platform usage plus actor/runtime cost | Strong pipeline fit, cloud-metered workflow |
| Bright Data Amazon Scraper API | Enterprise data collection and structured endpoints | Vendor infrastructure | Low to medium | Structured JSON/API delivery | Usage or dataset pricing | Powerful at scale, usually heavier than analyst CSV work |
| ParseHub-style visual scraper | Generic visual extraction projects | Vendor cloud | Low | CSV, JSON, integrations | Tiered SaaS | Flexible, but page changes and limits still need attention |
| Custom scripts | Engineering-owned parsers and special logic | Your code and infrastructure | High | Whatever you build | Engineering time, proxies, hosting | Maximum control, maximum maintenance |
| UScraper + Amazon Product Listing Scraper for UK | Local CSV from controlled keyword result pages | Local desktop app | Low | CSV listing rows | Template is free; app licensing applies | Best for inspectable local runs, not fleet-scale crawling |
Where UScraper wins
When a local desktop app is the better Amazon UK scraper alternative
UScraper fits the middle ground between copy-paste and cloud infrastructure. The companion Amazon Product Listing Scraper for UK template is not a global Amazon data warehouse. It opens configured Amazon UK search URLs, waits for listing result cards, handles a common cookie prompt, then exports rows with visible selectors.
The workflow definition is explicit. It starts with known URLs such as https://www.amazon.co.uk/s?k=shoes&page=1, waits for page load, runs JavaScript to accept common cookie buttons, waits for Amazon result rows, and uses Structured Export against each row.
The output columns are:
| Column | Why it matters |
|---|---|
keyword | Preserves the search term that created the row |
asin | Stable Amazon product identifier when present |
title | Listing title for spreadsheet review |
detail_page_url | Link back to the product or sponsored click path |
star_rating | Visible rating text from the listing |
number_of_reviews | Review count shown in search results |
price | Listing price text when visible |
current_time | Scrape timestamp for audit and freshness checks |
That makes UScraper useful for desk-grade price monitoring, product research, keyword shelf checks, and merchandising analysis where CSV is the handoff format.
Where cloud wins
Octoparse vs Apify for Amazon, and where ParseHub or APIs fit
Octoparse is usually the easier comparison for non-technical users: a visual scraper, Amazon-oriented templates, and hosted execution. It fits teams that already use Octoparse and want cloud task management more than local file custody.
Apify is stronger when Amazon scraping becomes part of a data pipeline. Actors, datasets, API access, storage, and Zapier-style integrations matter when runs feed downstream systems.
Bright Data-style scraper APIs make sense when the target is structured Amazon data at scale and the organization prefers managed infrastructure.
ParseHub-style tools are useful when a generic visual scraper is already approved and the job is exploratory.
Scripts win when engineers need complete control over parsing, retries, validation, proxies, storage, and tests. They also create the highest maintenance burden.
Prefer UScraper when exported rows, input URLs, and workflow edits should stay in a local desktop app and land in files your team controls.
Policy
Review Amazon rules before scaling any scraper
Amazon UK pages may be visible in a browser, but automated access can still be restricted by terms, Amazon UK robots.txt, intellectual property rights, privacy law, anti-circumvention rules, and local law. Do not bypass CAPTCHA, login walls, checkout flows, or technical access controls.
For commercial redistribution, reseller feeds, or customer-facing datasets, do a legal review before choosing any scraper. Local execution changes custody and auditability; it does not remove platform obligations.
Decision guide
Which Amazon UK scraper should you pick?
Pick UScraper for analyst-owned CSV
Use UScraper when you need a transparent local workflow, modest page counts, editable URLs, visible selectors, and repeatable CSV.
Pick hosted actors for pipelines
Use Apify or similar actor marketplaces when runs need APIs, schedules, cloud datasets, webhooks, and engineering-owned automation.
Pick SaaS templates for shared workspaces
Use Octoparse or ParseHub when operators prefer hosted visual projects and vendor cloud execution is already approved.
Pick APIs or scripts for special cases
Use managed scraper APIs for enterprise data delivery, or custom scripts when engineering control matters most.
Start with the Amazon Product Listing Scraper for UK template if your immediate job is keyword search/listing export to CSV. Browse the wider template library for adjacent workflows, or use the UScraper blog for more comparison guides.
FAQ
Frequently asked questions
The best option depends on ownership. Use cloud scrapers for large recurring jobs. Use UScraper when the work is analyst-led, the output is CSV, and the team wants visible navigation, waits, selectors, and export columns.