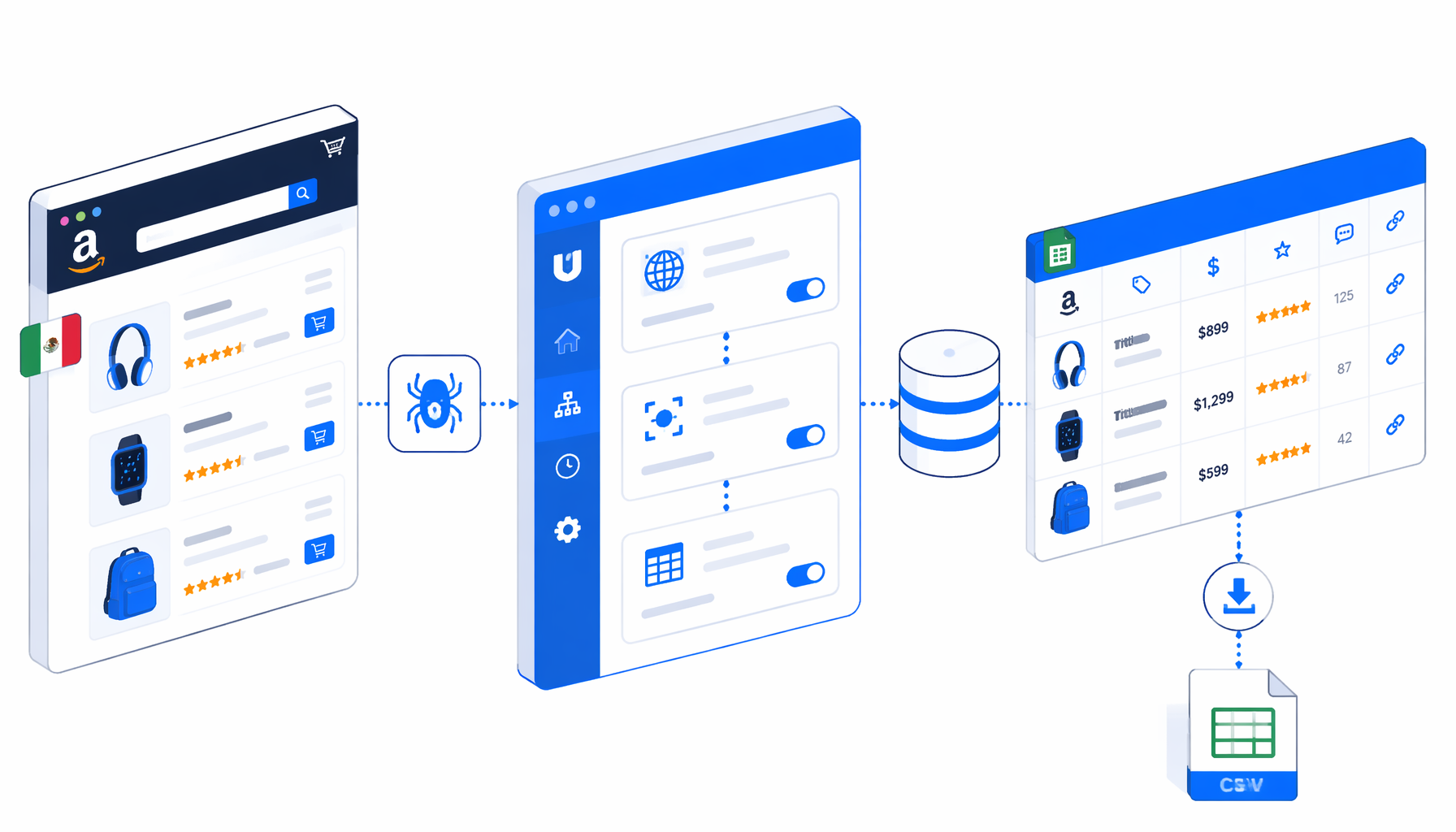
This tutorial shows how to scrape Amazon Mexico product listings into CSV with the Amazon Mexico Product Listing Scraper template for UScraper. You will import the workflow, change the keyword, set the export path, validate a run, and fix common issues.
CSV
8
Next loop
No code
Local
Before you start
Prerequisites, scope, and policy checks
You need UScraper as a local desktop app, one Amazon Mexico keyword, and a folder for the CSV. Start with one keyword and one or two result pages because Amazon varies by region, session, delivery location, sponsored modules, prompts, and layout tests.
This guide covers visible Amazon.com.mx search result listings. It does not cover account pages, carts, checkout, private data, login-only pages, CAPTCHA bypassing, or attempts to defeat anti-abuse controls. Before collecting data, review Amazon's current Conditions of Use, Amazon.com.mx robots.txt, and rules for your use case.
Technical access is not permission. Keep volume modest, document your purpose, avoid bypassing access controls, and use official Amazon routes when you need contractual product data rights.
Workflow anatomy
What the Amazon Mexico listing scraper does
The companion JSON is intentionally straightforward: Navigate -> Wait for Page Load -> optional continue-shopping click -> type keyword -> search -> wait for result rows -> Structured Export -> pagination loop. The stock keyword is almohada, but the workflow is meant to be edited before a real run.
The row selector targets search result cards with a non-empty data-asin. Structured Export reads each row, using JavaScript where title, review count, or price text may sit in different child elements. Pagination clicks the enabled next button and appends each page until no next page remains.
amazon_mexico_listados_scraper.csvColumn
keyword
Search term.
Column
asin
Listing ASIN.
Column
title
Product title.
Column
detail_page_url
Product URL.
Column
star_rating
Visible rating.
Column
number_of_reviews
Review count.
Column
price
Visible price.
Column
current_time
Export timestamp.
Runbook
How to scrape Amazon Mexico product listings to CSV
Import the template
Open Amazon Mexico Product Listing Scraper, download the JSON, and import it into UScraper.
Change the keyword
In Type Text, replace almohada with your search term. Keep one keyword per validation run so every row has clear context.
Confirm waits and prompts
Keep the load waits and result-row wait. If Amazon shows a continue-shopping screen, let the included click step handle it. If a full CAPTCHA appears, stop and resolve the browser manually.
Set the export folder
In Structured Export, confirm amazon_mexico_listados_scraper.csv, headers, append mode, and a project-specific save location you can inspect after every run.
Run one page, then paginate
Run the first page, compare rows against the browser, then allow the next-page loop only after the CSV shape is correct.
After the first pass, sort by asin and detail_page_url. One visible listing should create one row. Repeated rows usually mean the same page was exported twice or pagination resumed after the current page had already been appended.
Validation
Validate the Amazon Mexico export before analysis
Treat validation as part of the scrape. The same keyword can show different prices, ratings, sponsored placements, delivery context, and availability by session. Keep the browser visible beside the CSV and verify rows from the top, middle, and last exported page.
| Symptom | Likely cause | Fix |
|---|---|---|
| Zero rows exported | Product result rows did not render, a prompt blocked the page, or the row selector changed | Handle prompts, wait for visible listings, and rerun one page. |
Blank price | Price hidden, unavailable, delayed, split across elements, or replaced by a sponsored module | Compare the listing in the browser and refresh the price selector if needed. |
Blank number_of_reviews | Review count hidden, localized differently, or not present for the listing | Treat it as optional and verify against a row where reviews are visible. |
| Wrong keyword in every row | The Type Text block still contains the stock keyword | Replace the keyword before running and clear the old CSV before retesting. |
| Duplicate ASINs | Same page exported twice, pagination resumed mid-run, or Amazon repeated a listing | Dedupe by asin, detail_page_url, and current_time. |
Alternatives
UScraper vs PA-API, Octoparse, Apify, and hosted scrapers
Searches like amazon pa api mexico, Octoparse Amazon Mexico alternative, and best Amazon Mexico scraper surface several approaches.
| Approach | Best fit | Trade-off |
|---|---|---|
| UScraper local desktop template | Supervised CSV research where an analyst wants to see the browser and keep output on disk | You maintain selectors when Amazon changes layout. |
| Official Amazon API routes | Approved affiliate, creator, or product-content integrations that need contractual data access | Requires eligibility, credentials, API rules, and current Amazon program compliance. |
| Hosted scraper actors or services | Cloud scheduling, managed proxy infrastructure, or hands-off extraction | Pricing, data custody, and row limits depend on the vendor. |
| Code-first scraping tutorials | Custom engineering control in Python or JavaScript | You own browser rendering, blocking, pagination, storage, and maintenance. |
Use browser export for research spreadsheets. Use official API routes for production apps, affiliate surfaces, or redistribution workflows that need stable terms and program-level permission.
FAQ
Amazon Mexico listing scraper FAQ
Amazon Mexico listing pages can be visible in a browser, but automated collection can still be restricted by terms, robots directives, anti-abuse systems, copyright, privacy law, and local rules. Review source policies, avoid access-control bypassing, keep runs modest, and get legal review before commercial reuse.
Next step
Download the Amazon Mexico product listing scraper
Download the JSON from Amazon Mexico Product Listing Scraper and keep this open for QA. For adjacent workflows, browse the UScraper template library or UScraper scraping tutorials.