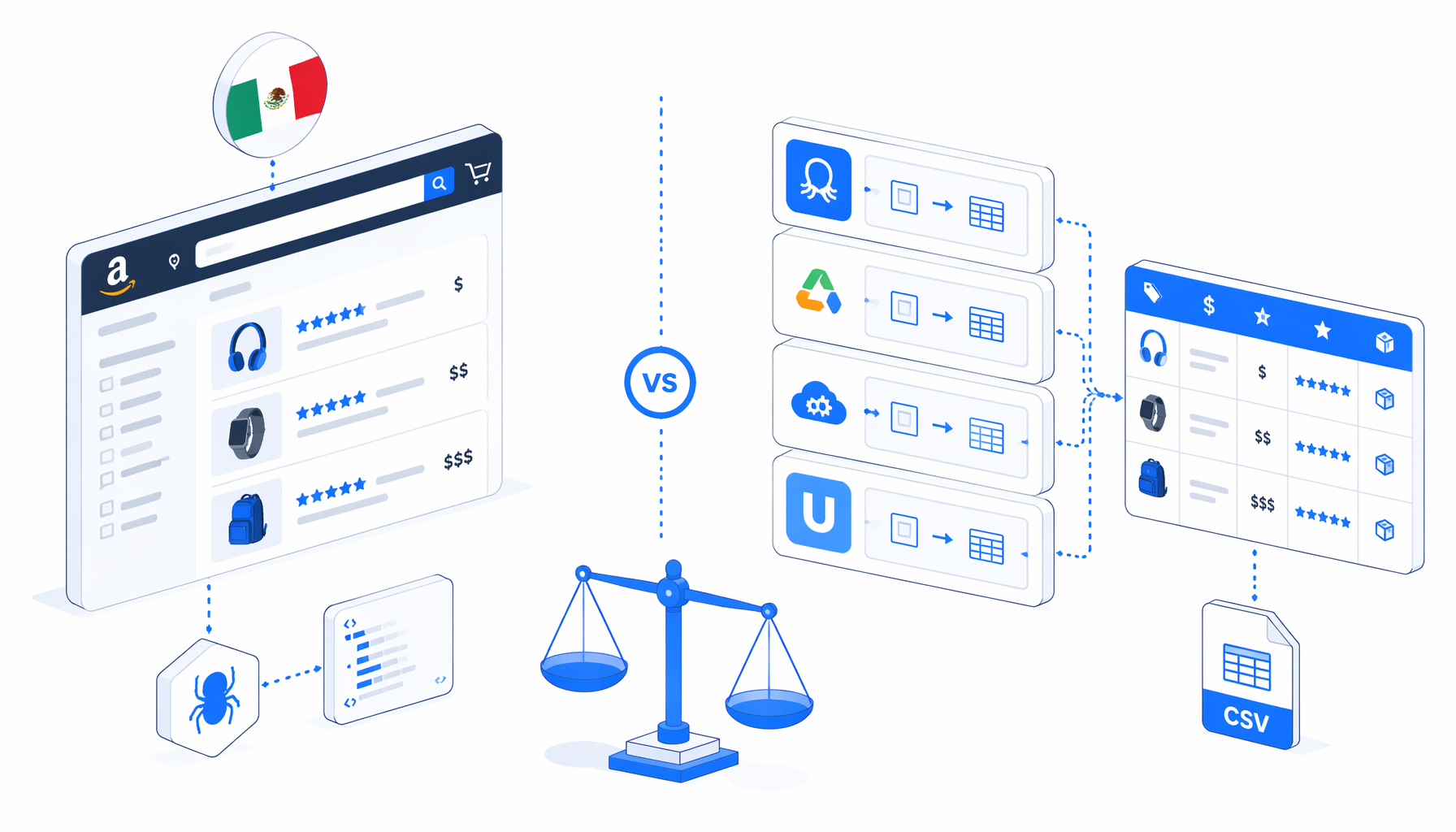
The best Amazon Mexico product scraper is not always the biggest cloud platform. For Amazon.com.mx listing research, choose by where the browser runs, whether code is acceptable, how pricing is metered, and whether the output needs to be a reviewable CSV. This comparison covers Octoparse, Apify, scraper APIs, scripts, and UScraper's Amazon Mexico Product Listing Scraper template.
CSV
8
Next loop
Visual
Local
Decision frame
How to compare Amazon Mexico product data extraction tools
Searches like how to scrape Amazon Mexico, apify Amazon Mexico scraper, octoparse Amazon alternative, and amazon scraper API comparison usually mix several operating models into one bucket. An Amazon Product Advertising API integration, an Apify actor, an Octoparse template, a Bright Data endpoint, an Outscraper service, a ParseHub project, and a Playwright script can all produce product data. They do not give your team the same custody model, cost model, or maintenance path.
Amazon.com.mx listing pages vary by keyword, delivery context, session state, language, sponsored modules, availability, anti-abuse prompts, and layout changes. A useful Amazon Mexico listing scraper must preserve context, not just grab the first title and price on the page.
Do not compare these tools only by "can it scrape Amazon?" Compare hosting, code ownership, output shape, pricing meter, compliance path, and who fixes selectors when Amazon changes the page.
Side-by-side
Amazon Mexico scraper alternatives compared
| Option | Best fit | Hosting | Code needed | Output shape | Pricing shape | Main trade-off |
|---|---|---|---|---|---|---|
| Amazon Product Advertising API | Eligible affiliate, commerce, and product applications | Amazon API | Developer integration | Official API responses | API eligibility, quotas, and terms | Strong sanctioned route, but not a quick browser-to-CSV scraper |
| Octoparse Amazon Mexico Listados template | No-code operators who prefer hosted visual scraping | Vendor cloud | Low | Cloud table, CSV, Excel | SaaS plans, task limits, and run modes | Fast setup, less local custody over runs and browser state |
| Apify Amazon Mexico actors | Recurring hosted jobs, datasets, APIs, and automation | Apify cloud | Low to medium | Dataset, JSON, CSV, API | Platform usage plus actor/runtime pricing | Strong automation surface, but runs and data live in a cloud workflow |
| Bright Data Amazon Scraper | Larger scraping programs, managed unblocking, and API delivery | Vendor infrastructure | Low to medium | API JSON, datasets, or scraper output | Usage, endpoint, or dataset pricing | Strong scale, usually heavier than one analyst CSV |
| Outscraper Amazon Scraper or managed services | Teams that want packaged product extraction | Vendor infrastructure | Low | Structured product data delivery | Service/API pricing | Convenient, but less selector-level control |
| ParseHub, Browse AI, or Zapier-connected flows | General visual scraping and monitoring workflows | Vendor app/cloud model | Low to medium | CSV, JSON, automations | Tiered SaaS plans and task limits | Flexible, but Amazon-specific QA still matters |
| Crawlee or DIY scripts | Engineering-owned parsers, tests, queues, and custom storage | Your machines or servers | High | Whatever you build | Engineer time plus proxy/rendering cost | Maximum control, maximum maintenance burden |
| UScraper + Amazon Mexico Product Listing Scraper | Local keyword research, price snapshots, ASIN shortlists, and CSV handoff | Local desktop app | Low | CSV: keyword, ASIN, title, URL, rating, reviews, price, timestamp | Template is free; app licensing applies | Best for inspectable local runs, not fleet-scale cloud crawling |
This is a fit comparison, not a universal ranking. A marketplace intelligence platform may prefer managed APIs. A developer team may prefer Apify or scripts. A seller, agency, or analyst checking defined Amazon.com.mx keywords may prefer UScraper because the extraction logic, browser session, and output folder are visible.
Where UScraper fits
When UScraper is the better Amazon Mexico listing scraper alternative
UScraper is strongest when the project is concrete: "I need Amazon.com.mx search listings for this keyword, I need a CSV, and I want to inspect the workflow before trusting the rows." The Amazon Mexico Product Listing Scraper template is built for that lane.
The bundled JSON export defines a visual flow:
Navigate -> Wait for Page Load -> optional continue-shopping click
-> type keyword -> search -> wait for listing rows
-> Structured Export -> next-page loop -> append CSV
The stock workflow searches for almohada, targets search-result cards with a non-empty data-asin, exports visible listing fields, and clicks a.s-pagination-next:not(.s-pagination-disabled) until no enabled next page remains. It does not include a CSV sample in the bundle; the first dry run is the authoritative sample for your session, keyword, and region.
| CSV column | What it captures | Why it matters |
|---|---|---|
keyword | Search term used by the workflow | Keeps every row tied to the query |
asin | Amazon product identifier from the result card | Helps deduplicate products |
title | Visible listing title | Main product discovery field |
detail_page_url | Canonical product URL assembled from the listing link | Preserves source traceability |
star_rating | Visible rating text when Amazon renders it | Supports quality filters |
number_of_reviews | Visible review count when present | Helps sort by demand or trust |
price | Visible price text from the listing card | Supports price snapshots |
current_time | Local scrape timestamp | Explains when volatile prices were observed |
That workflow shape is the main reason to choose UScraper over an opaque hosted task. You can inspect the Navigate block, wait logic, optional gate click, search keyword, row selector, JavaScript columns, append mode, and save folder. When Amazon changes a card layout or hides a field, you can debug the visible flow instead of waiting for a third-party template to be patched.
Where cloud wins
When Apify, Octoparse, APIs, or scripts make more sense
Choose Amazon Product Advertising API when you are eligible and your use case fits official API rules. For affiliate or product applications, the SearchItems API and Mexico locale documentation should be reviewed before any scraper workflow.
Choose Apify when engineering wants hosted actors, API calls, datasets, scheduled runs, retries, and cloud automation. Apify is a better fit when Amazon Mexico collection is part of a recurring data pipeline.
Choose Octoparse when non-technical operators want a hosted no-code environment, preset Amazon Mexico templates, cloud execution, and cloud exports. It is closest to UScraper for visual setup, but the operating model is cloud-first.
Choose Bright Data, Outscraper, Product Data Scrape, or other managed providers when procurement values vendor infrastructure, scale, and structured delivery more than workflow-level selector control.
Choose scripts when developers need tests, version control, queues, custom storage, monitoring, and exact parser behavior. The downside is long-term ownership: Amazon layout drift becomes your engineering problem.
UScraper wins when keyword inputs, browser state, workflow edits, and final CSV files should stay inside a local desktop app workflow.
Hosted providers win when you need scheduling, API orchestration, shared datasets, high concurrency, and vendor-managed retries.
Depends. Octoparse and UScraper both reduce code. Pick Octoparse for cloud tasks; pick UScraper for local workflow inspection.
Scripts win only when engineers are ready to own selectors, tests, storage, monitoring, and future Amazon layout changes.
Policy check
Do not skip Amazon policy review
Amazon.com.mx listing pages may be visible in a browser, but automated collection can still be restricted by Amazon's current Conditions of Use, robots directives, anti-abuse systems, intellectual property rights, privacy rules, and local law. Do not bypass CAPTCHA, login gates, payment flows, or access controls. Keep batches modest, collect only fields you need, and use official API or partner routes when you need contractual rights to product content.
For adjacent options, browse the UScraper template library, read more comparison posts on the UScraper blog, or start with the maintained Amazon Mexico Product Listing Scraper template when your deliverable is local CSV.
FAQ
FAQ
What is the best Amazon Mexico product listing scraper?
The best choice depends on scale, hosting, code tolerance, compliance requirements, and output format. Use official API access when eligible, hosted actors or scraper APIs for recurring cloud jobs, scripts for engineering-owned pipelines, and UScraper when you need a local desktop app workflow that exports visible Amazon.com.mx listing rows to CSV.
How does UScraper compare with Octoparse for Amazon Mexico listings?
Octoparse offers hosted no-code Amazon Mexico listing and detail templates. UScraper runs an importable workflow locally, keeps navigation, waits, selectors, and export columns visible, and writes amazon_mexico_listados_scraper.csv to the configured folder. Octoparse is stronger for hosted task management; UScraper is stronger for local custody and workflow inspection.
How does UScraper compare with Apify Amazon Mexico scrapers?
Apify is stronger for hosted actors, datasets, APIs, scheduling, and cloud-scale automation. UScraper is stronger for supervised CSV work where an operator wants to inspect the browser flow, validation handling, pagination loop, Structured Export columns, and save folder before using the output.
Do I need Amazon Product Advertising API access?
Use the Amazon Product Advertising API when you are eligible for official API access and your use case fits its terms, credentials, quotas, and field coverage. A scraper workflow is more practical for supervised browser-based CSV extraction from reviewed pages, but it is not a substitute for contractual product data rights.
What does the UScraper Amazon Mexico listing template export?
The companion template writes amazon_mexico_listados_scraper.csv with keyword, asin, title, detail_page_url, star_rating, number_of_reviews, price, and current_time columns. The bundled workflow searches Amazon.com.mx, handles the observed continue-shopping gate when present, exports listing rows, and follows the enabled next-page link until pagination stops.