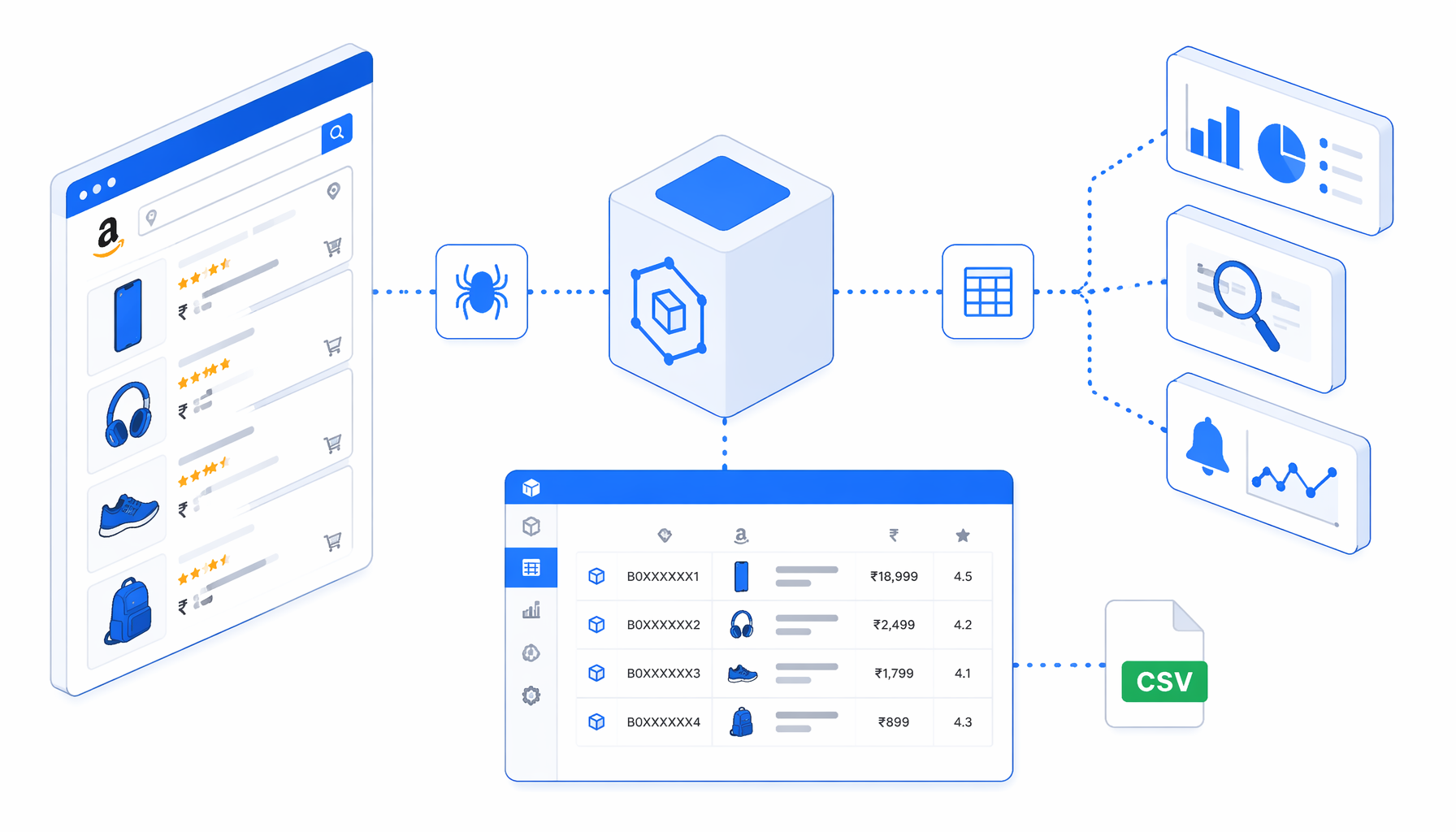
An Amazon India product scraper is most useful when the job is not "collect everything." It is useful when a seller, analyst, SEO team, newsroom, or agency needs a timestamped CSV export from Amazon.in keyword listing pages. The Amazon Product Listing Scraper for India template turns that use case into a local desktop app workflow.
Use-case frame
Why Amazon India listing data needs structure
Amazon.in search pages are live market snapshots. A keyword such as lightning cable can show competing ASINs, price bands, rating density, review depth, title wording, availability signals, sponsored placements, and page layout variants in one view. That is useful data, but it is painful to copy by hand and easy to misread when every browser tab has a different context.
The market context is broad enough that even non-retail teams care. Bain and Flipkart's How India Shops Online 2025 report describes India as a large e-retail market with a massive online shopper base, while business press has covered how online price data from marketplaces can matter for inflation tracking and public-interest analysis. For a smaller team, the same idea becomes practical: collect a clear sample, preserve the source URL, and keep the run date attached.
A search result page is not a database. Treat it as timestamped evidence, then validate it before using it in a report.
Personas
Who uses an Amazon India product scraper?
| Persona | Pain | Useful export outcome |
|---|---|---|
| Marketplace sellers | Manual competitor checks miss price bands, review gaps, and repeated ASINs. | Export products ranking for a target keyword and compare title wording, prices, ratings, and review counts. |
| Brand and category teams | Assortment research becomes a pile of screenshots. | Build a searchable CSV of visible products for category mapping and shortlist selection. |
| SEO and content teams | Product pages need real marketplace language, not guessed keywords. | Collect title patterns, demand signals, and product URLs for content briefs and on-page research. |
| Newsrooms and researchers | Public claims about prices or availability need a documented sample. | Capture visible listing rows with source URLs and collection time for editorial review. |
| Agencies | Client reports need repeatable evidence, not copied notes. | Run the same approved keyword set and attach an auditable CSV to the deliverable. |
The UScraper template is intentionally narrow. It is not a full Amazon product catalog feed, checkout crawler, account-data extractor, or replacement for official access. It is a workflow for turning selected Amazon.in keyword pages into a structured file.
Workflow
What the UScraper template exports
The bundled JSON workflow is built around a visible block path: Set Window Size -> Navigate -> Wait for Page Load -> Sleep -> Continue Shopping Check -> Product Rows -> Structured Export -> Loop Continue. The Navigate block is preconfigured for Amazon.in pages 1-20 for the sample keyword lightning cable. Replace those URLs with the keyword and page range your team has approved.
The export is append-mode CSV. Each product row comes from div[data-component-type="s-search-result"][data-asin], then the workflow extracts values from the result card. Amazon can change result cards or show validation screens, so the JSON should be treated as the authoritative workflow definition and the CSV should be audited after every meaningful run.
amazon-product-listing-scraper-for-india.csvColumn
keyword
Keyword parsed from the current Amazon.in search URL.
Column
asin
Product ASIN from the listing row.
Column
title
Visible product title from the search result card.
Column
detail_page_url
Product detail page URL from the listing card.
Column
star_rating
Visible rating text when rendered.
Column
number_of_reviews
Review or rating count when rendered.
Column
price
Visible listing price when available for the session.
Column
current_time
Collection timestamp generated at export time.
| Field group | Columns |
|---|---|
| Search context | keyword, current_time |
| Product identity | asin, title, detail_page_url |
| Demand signals | star_rating, number_of_reviews |
| Commerce signal | price |
Scenarios
Concrete workflows for research and monitoring
Keyword assortment map
Run a small keyword set, dedupe by asin, and group products by title language, rating depth, and price band. This helps teams see which products dominate a search before selecting pages for deeper analysis.
Amazon price monitoring India
Repeat the same keyword URLs on a fixed cadence, keep region and session assumptions stable, and compare visible prices across runs. Treat blank prices and validation pages as QA flags, not zero values.
SEO product-language research
Export titles and product URLs for a query, then identify common phrases, attributes, pack sizes, compatibility terms, and trust signals that should inform content briefs.
Newsroom marketplace checks
Use a documented keyword sample to support reporting on visible prices, product availability, or rating signals. Keep screenshots and editorial review alongside the CSV.
Agency reporting
Reuse the same approved keyword list for each client check, attach the CSV, and summarize changes in ASIN mix, price bands, and review count distribution.
Product shortlist creation
Start with listing data to decide which detail pages deserve manual review, API lookup, or a richer product-detail extraction workflow.
Decision
UScraper vs Octoparse, Apify, Bright Data, and APIs
Octoparse publishes Amazon scraper templates, including listing workflows. Apify actors can run Amazon.in search, ASIN, product URL, or category scraping in a hosted environment. Bright Data positions Amazon scraping as a managed scraper/API product. Amazon's own Product Advertising API documentation is the right starting point when you need sanctioned product metadata access.
| Route | Best fit | Trade-off |
|---|---|---|
| UScraper template | Local no-code research batches, visible workflow blocks, CSV saved to a chosen folder | Best for supervised Amazon listings to CSV, not high-volume unattended crawling. |
| Octoparse-style no-code template | Hosted visual scraping and vendor-managed runs | Execution and exports depend on the vendor environment and plan. |
| Apify or managed scraper actors | Scheduling, queues, API handoff, retries, and larger recurring jobs | More cloud infrastructure, metering, and third-party custody. |
| Bright Data scraper/API | Managed extraction pipelines and structured delivery | Better for API-driven operations than one-off analyst review. |
| Official Amazon API route | Sanctioned metadata, affiliate workflows, quotas, and production use | Requires eligibility, credentials, implementation, and API-specific limits. |
If you are comparing Apify Amazon scraper vs no code or looking for an Octoparse Amazon scraper alternative, frame the choice around custody and scale. UScraper is strongest when a human wants to inspect the browser run and own the CSV locally. Cloud tools are stronger when scheduling and operational infrastructure matter more than local review.
Guardrails
Compliance and data-quality guardrails
Before scraping, review the current Amazon.in Conditions of Use, Amazon.in robots.txt, and official API documentation. Do not use a scraper to bypass CAPTCHA, login walls, checkout flows, account pages, or access-control prompts. Keep batches modest, document the business purpose, and get legal review before commercial reuse or redistribution.
Runbook for a reliable first batch
- Pick one approved keyword and one or two result pages.
- Import the Amazon Product Listing Scraper for India template instead of rebuilding the workflow.
- Replace the sample
lightning+cableURLs with your target keyword. - Confirm the CSV save folder and keep append mode intentional.
- Run one page, then compare several CSV rows against the browser.
- Dedupe by
asinanddetail_page_urlbefore analysis. - Save the keyword, run date, region assumptions, and any selector changes with the report.
For implementation steps, use the companion Amazon India scraping tutorial. For more extractors, browse the template library or the broader UScraper blog.
FAQ
Amazon India product scraper FAQ
The best option depends on custody, scale, and permission. UScraper is a strong fit for supervised keyword snapshots that need a local CSV export. Cloud actors and managed APIs fit larger scheduled jobs, while official Amazon API routes should be reviewed for sanctioned product data use.
Next step
Download the Amazon India product scraper template
Use this workflow when you have a defined Amazon.in keyword list and need a local CSV that teammates can inspect. Download the Amazon Product Listing Scraper for India template, run a small validation batch, then expand only after the rows match what you see in the browser.